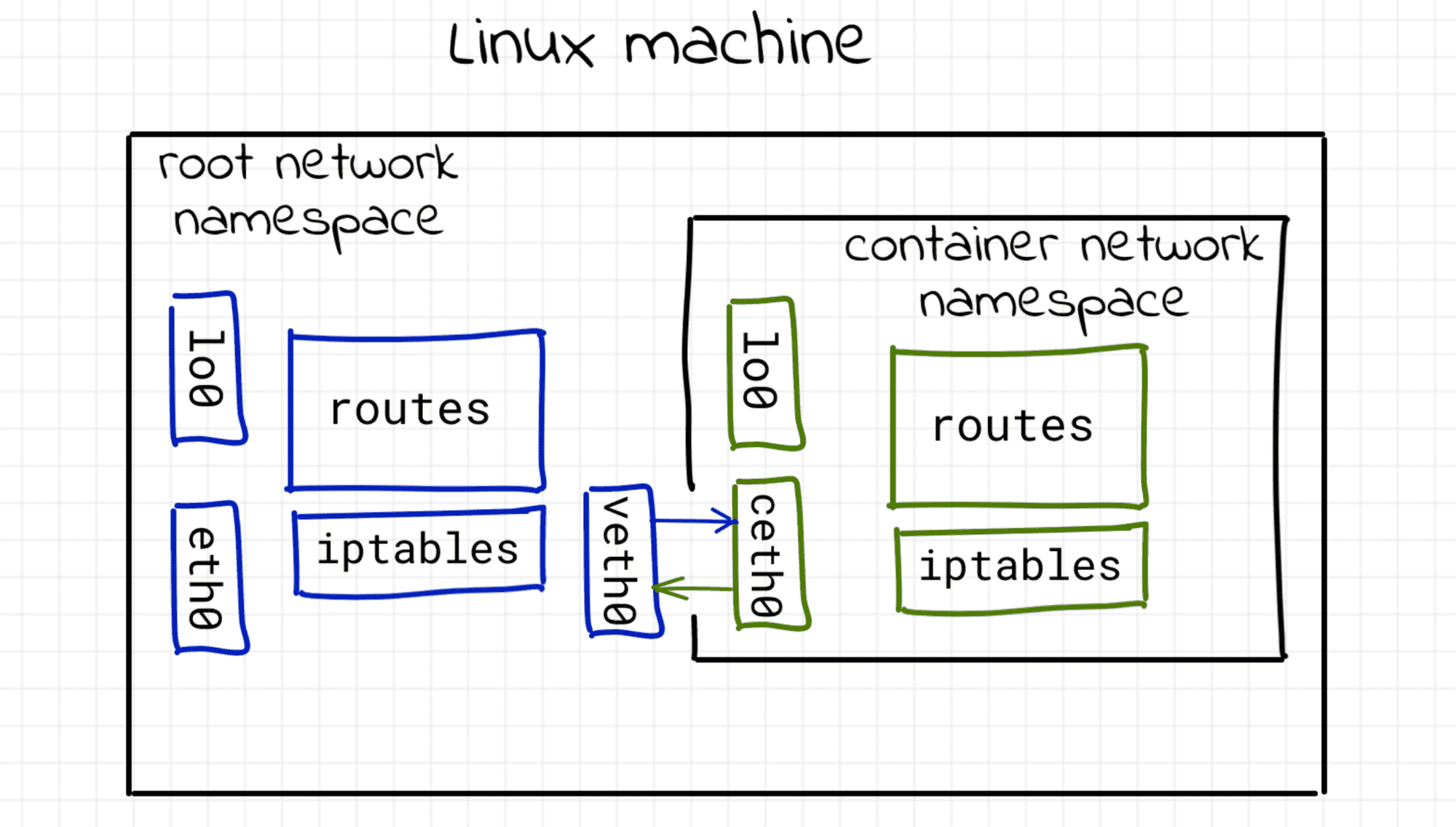
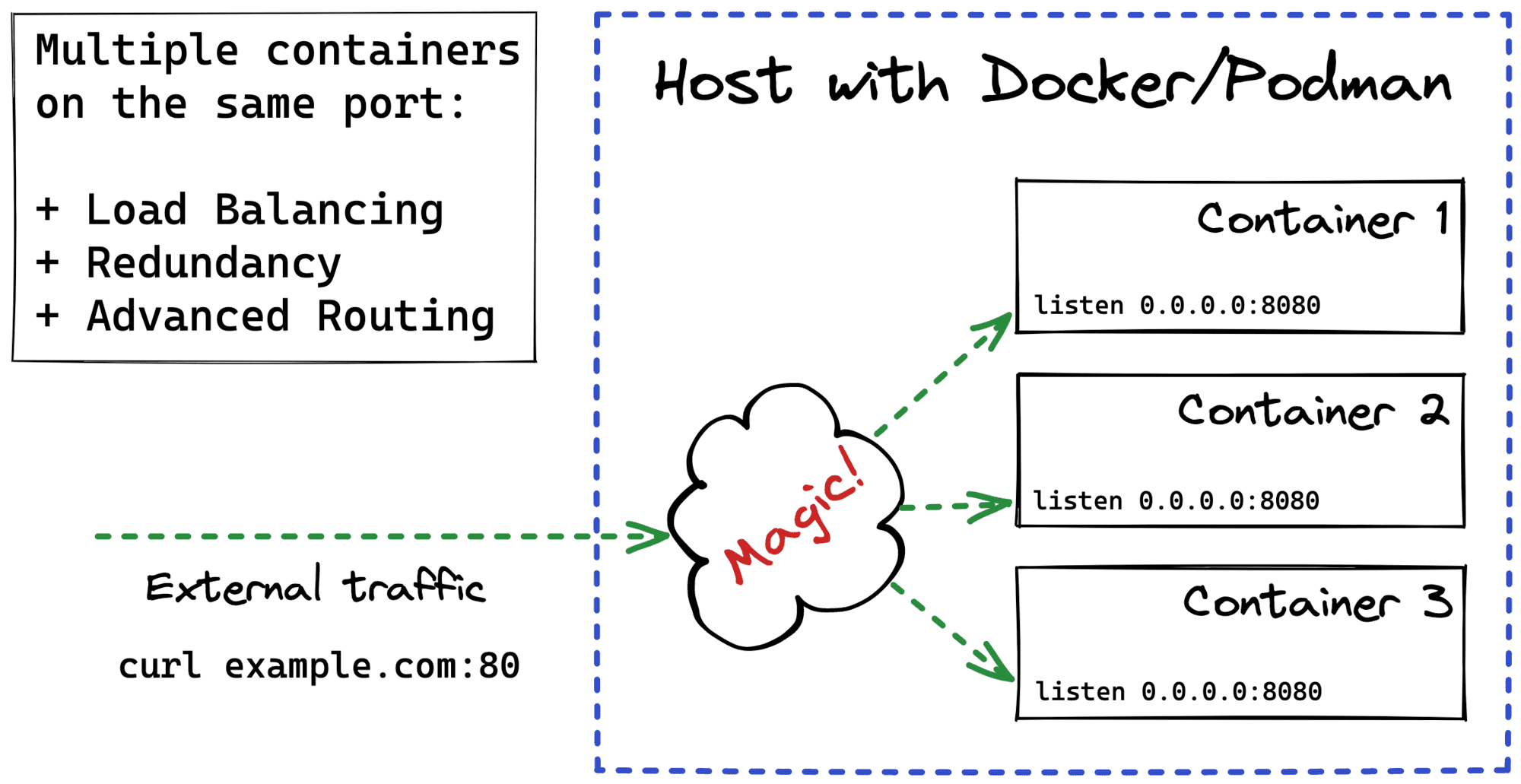
If you're dealing with containers regularly, you've probably published ports many, many times already. A typical need for publishing arises like this: you're developing a web app, locally but in a container, and you want to test it using your laptop's browser. The next thing you do is docker run -p 8080:80 app and then open localhost:8080 in the browser. Easy-peasy!
But have you ever wondered what actually happens when you ask Docker to publish a port?
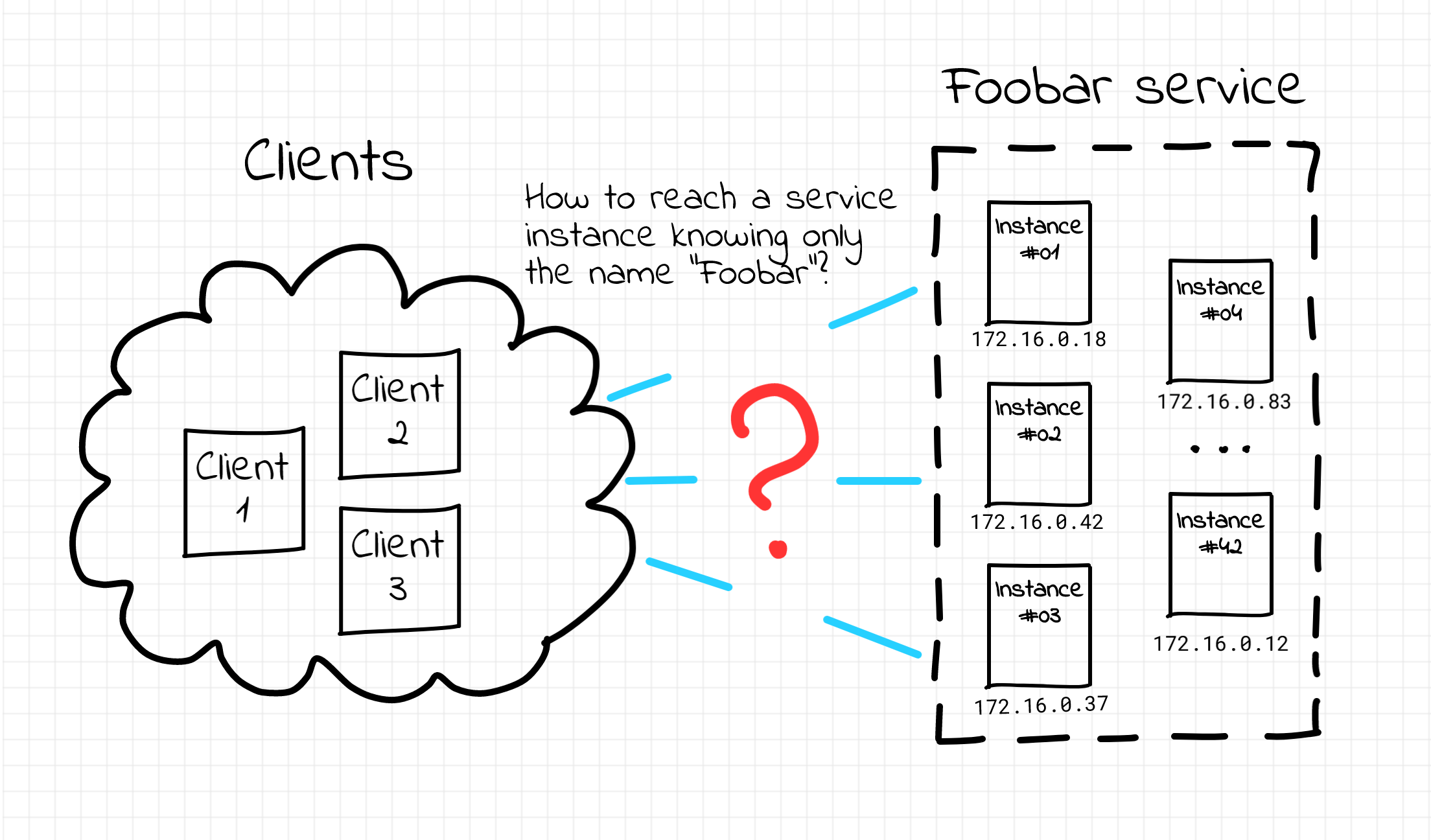
In this article, I'll try to connect the dots between port publishing, the term apparently coined by Docker, and a more traditional networking technique called port forwarding. I'll also take a look under the hood of different "single-host" container runtimes (Docker Engine, Docker Desktop, containerd, nerdclt, and Lima) to compare the port publishing implementations and capabilities.
As always, the ultimate goal is to gain a deeper understanding of the technology and get closer to becoming a power user of containers. Let the diving begin!
Read more