[not a] Kubernetes 101 - Pods, Deployments, and Services As an Attempt To Automate Age-Old Infra Patterns
Saim Safdar from the Cloud Native Islamabad community generously invited me to his channel to conduct a Kubernetes 101 workshop. However, as often happens, I found myself pulled in a slightly different direction:
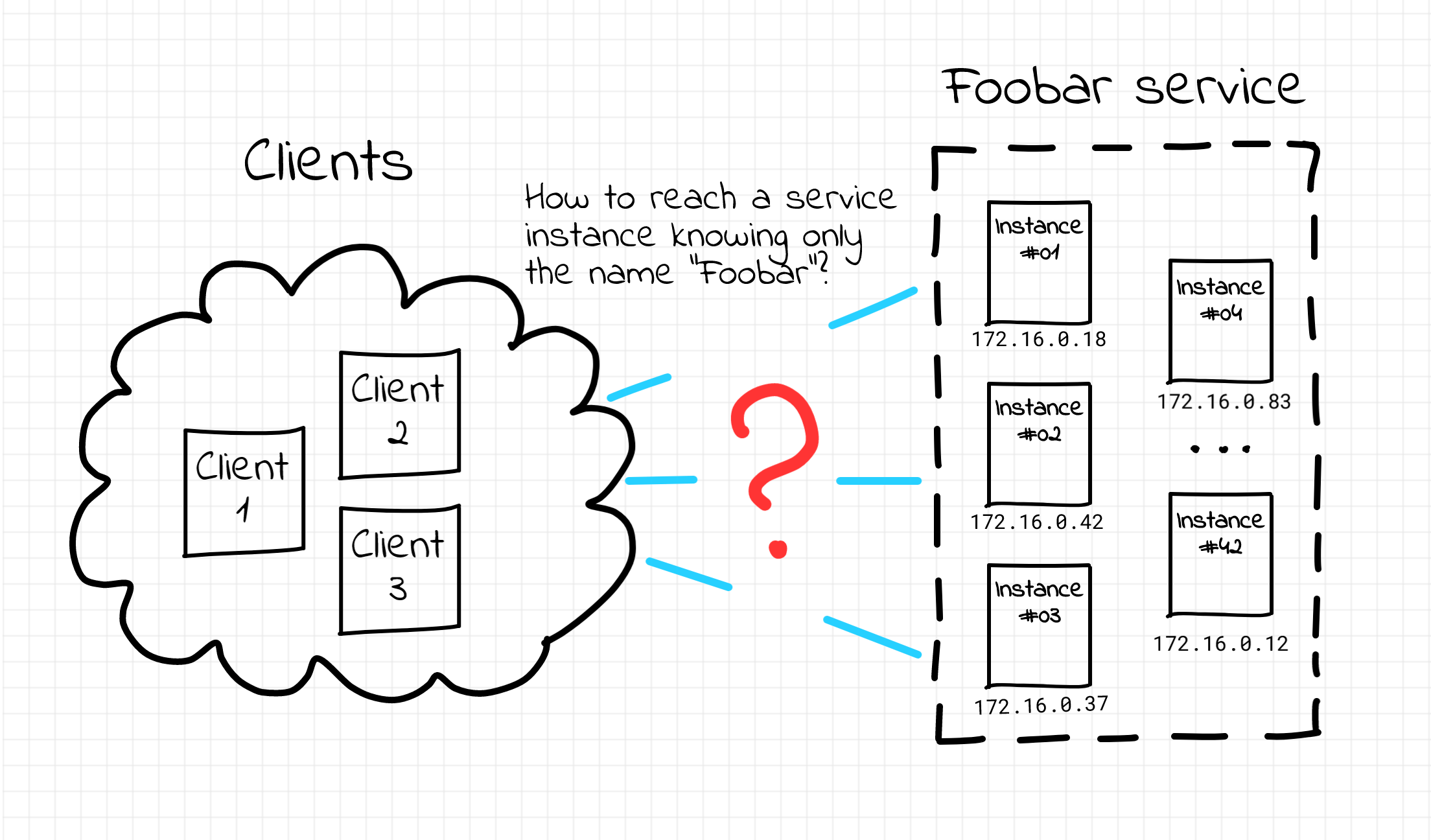
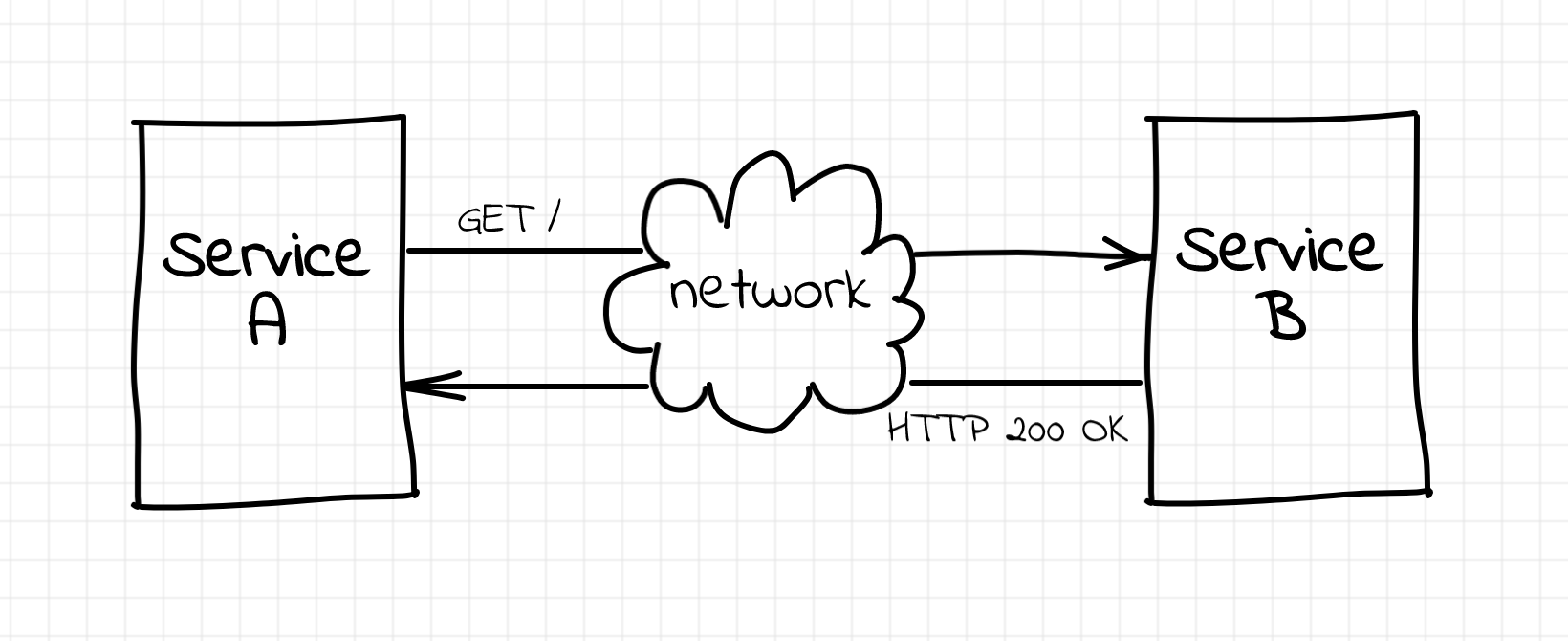
What if you don't start with Pods, Deployments, and Services and instead take a step back and look at how things were done in the past with good old VMs? Can it help you understand Kubernetes faster and deeper?
Below, I present a more polished version of the workshop, enriched with illustrations and runnable examples. You can experiment with these examples directly in your browser on labs.iximiuz.com.