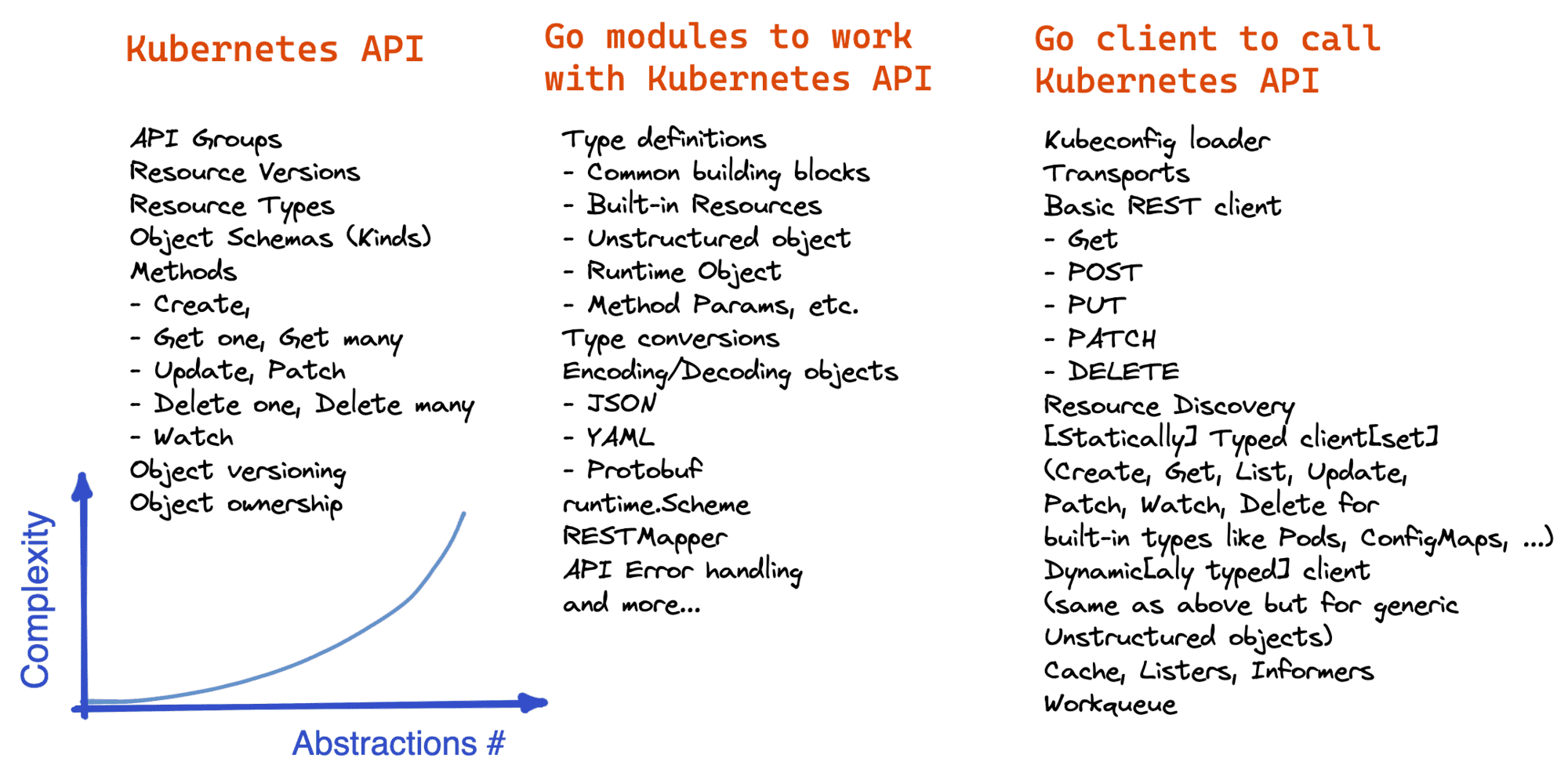
"How to start programming in Go and for Kubernetes?" - the question I often get from fellow DevOps people. This is a tricky one. And I don't have a universal answer to it. However, I do have some thoughts to share.
But first, let me tell you my own story.
In my case, it was rather an evolutionary step - I'd been developing software for almost 10 years by the time I started coding for Kubernetes. I'd also been (sporadically) using Go for some of my server-side projects since probably 2015. And around 2019, I started my transition to, first, SRE and, then, Platform Engineering. So, when I decided to get my hands dirty with Kubernetes controllers, it was just a matter of joining the right team and picking up the Kubernetes domain. Luckily, I had a good candidate on my radar, and that required just an internal transition from one team to another.
However, based on my observations, for many contemporary DevOps engineers, the direction of the desired transformation is often inverse. From Ops to Dev (preferably, for Ops).
Since your background and experience may vary, instead of giving a concrete piece of advice here, I'll try to explain how I'd approach the problem given different levels of proficiency with the technologies.
Read more