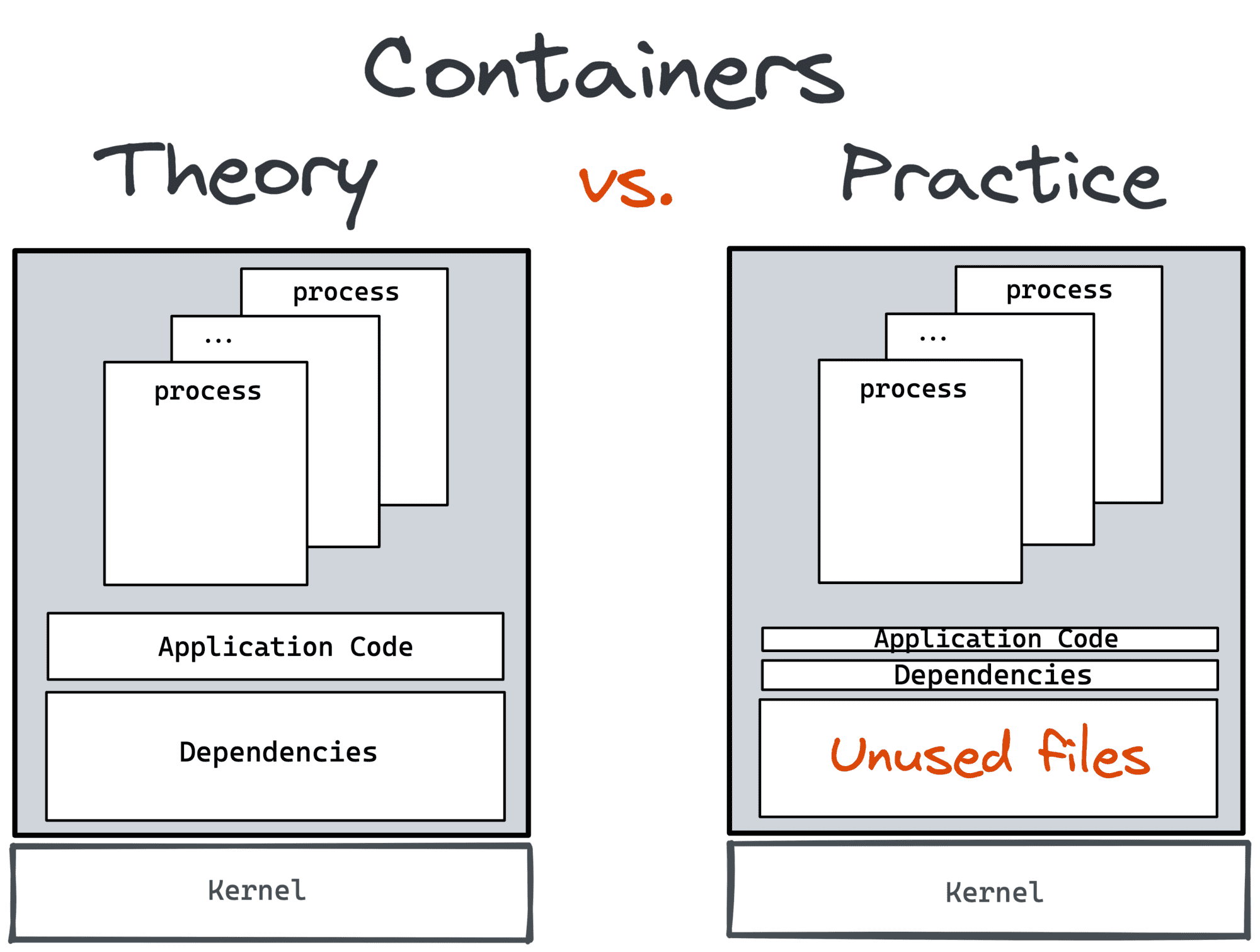
Containers could have become a lightweight VM replacement.
However, the most widely used form of containers, standardized by Docker/OCI, encourages you to have just one process service per container.
Such an approach has a bunch of pros -
increased isolation, simplified horizontal scaling, higher reusability, etc.
However, there is a big con - in the wild, virtual (or physical) machines rarely run just one service.
While Docker tries to offer some workarounds to create multi-service containers,
Kubernetes makes a bolder step and chooses a group of cohesive containers,
called a Pod, as the smallest deployable unit.
When I stumbled upon Kubernetes a few years ago,
my prior VM and bare-metal experience allowed me to get the idea of Pods pretty quickly.
Or so thought I... 🙈
Starting working with Kubernetes,
one of the first things you learn is that every pod gets a unique IP and hostname and that within a pod,
containers can talk to each other via localhost.
So, it's kinda obvious - a pod is like a tiny little server.
After a while, though, you realize that every container in a pod gets an isolated filesystem and that from inside one container,
you don't see processes running in other containers of the same pod.
Ok, fine! Maybe a pod is not a tiny little server but just a group of containers with a shared network stack.
But then you learn that containers in one pod can communicate via shared memory!
So, probably the network namespace is not the only shared thing...
This last finding was the final straw for me. So, I decided to have a deep dive and see with my own eyes:
- How Pods are implemented under the hood
- What is the actual difference between a Pod and a Container
- How one can create Pods using Docker.
And on the way, I hope it'll help me to solidify my Linux, Docker, and Kubernetes skills.
Read more