Server-Side Playgrounds Reimagined: Build, Boot, and Network Your Own Virtual Labs
After a long break from posting on this blog, I'm happy to share the continuation of the iximiuz Labs story. This time, I'm going to cover the recent overhaul of the playground engine, which I like to call Playgrounds 2.0:
- Quick recap: iximiuz Labs playgrounds - what are they, really?
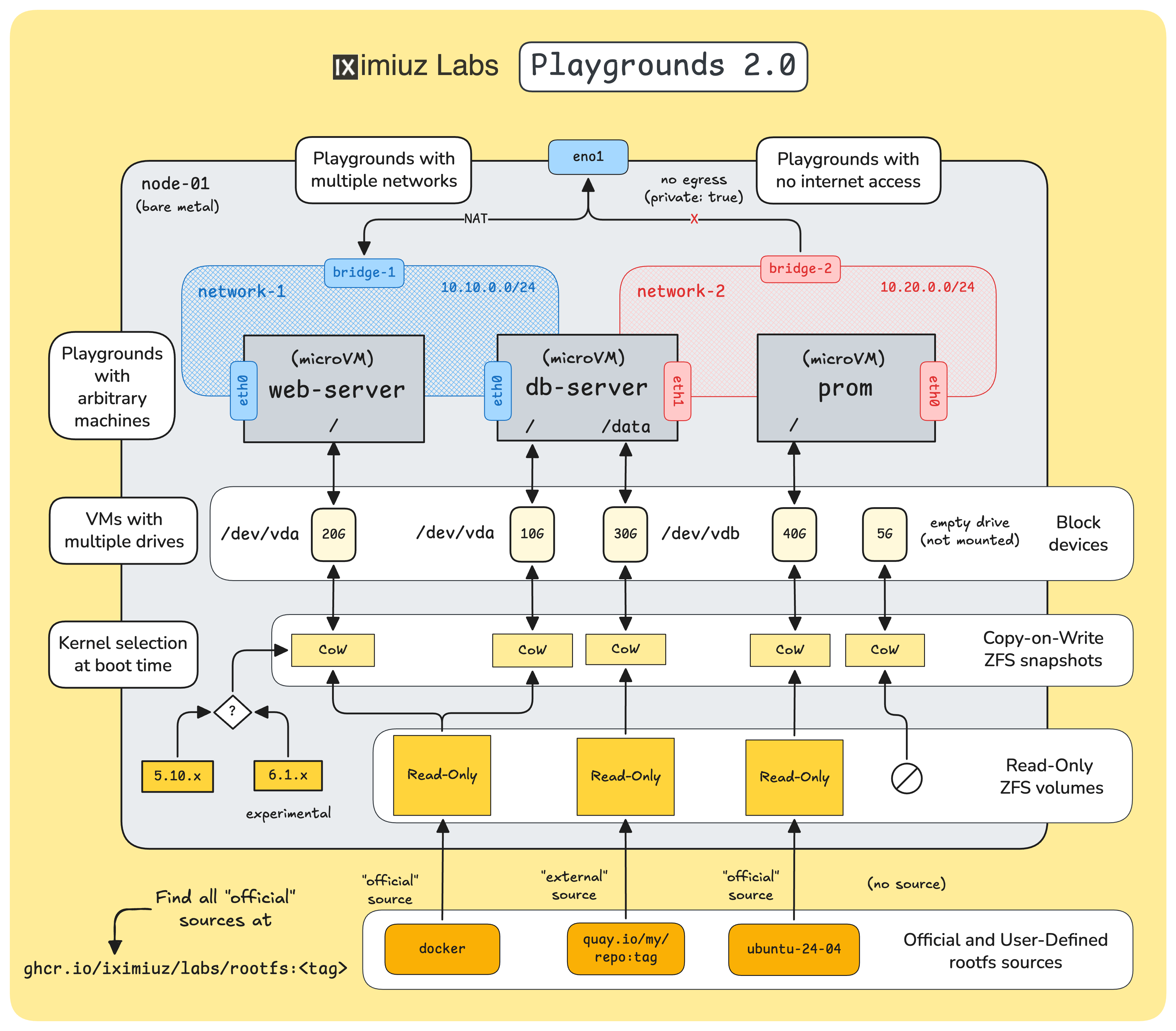
- How VMs are constructed by mixing the rootfs and the kernel
- How to run custom playgrounds with simple YAML manifests
- How to bake and use custom VM rootfs images
- How to create multi-network playgrounds
- Why you should start creating Linux playgrounds today