This is a long overdue post on iximiuz Labs' internal kitchen. It'll cover why I decided to build my own learning-by-doing platform for DevOps, SRE, and Platform engineers, how I designed it, what technology stack chose, and how various components of the platform were implemented. It'll also touch on some of the trade-offs that I had to make along the way and highlight the most interesting parts of the platform's architecture. In the end, I'll, of course, share my thoughts on what's next on the roadmap. Sounds interesting? Then brace for a long read!
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
Why my own online playgrounds?
Before I decided to go all-in with iximiuz Labs, I'd already been blogging producing technical educational content for a few years.
My primary means of expression were plain writing and (quite a lot of) drawing.
However, there was one more, often overlooked but important, part - providing reproducible instructions on how to repeat the experiments from my articles to help students gain their own hands-on experience.
Instead of just reading about a technology, I wanted the student to try it out, play with it, and see how it works first-hand. This, in particular, required me to spend a non-trivial amount of time per article to come up with a set of steps to set up a lab environment... But the harsh reality is that regardless of how big my effort was, there would always be people lacking the right hardware, software, and/or skills to actually run these instructions. So, I always felt that it could be done more efficiently.
A pretty common solution for this problem is to provide a web terminal connected to a pre-configured environment right on the article's page. It definitely eliminates a great deal of the obstacles for the students. They no longer need to install anything on their machines, and it becomes possible to follow the instructions in the article without leaving the browser.
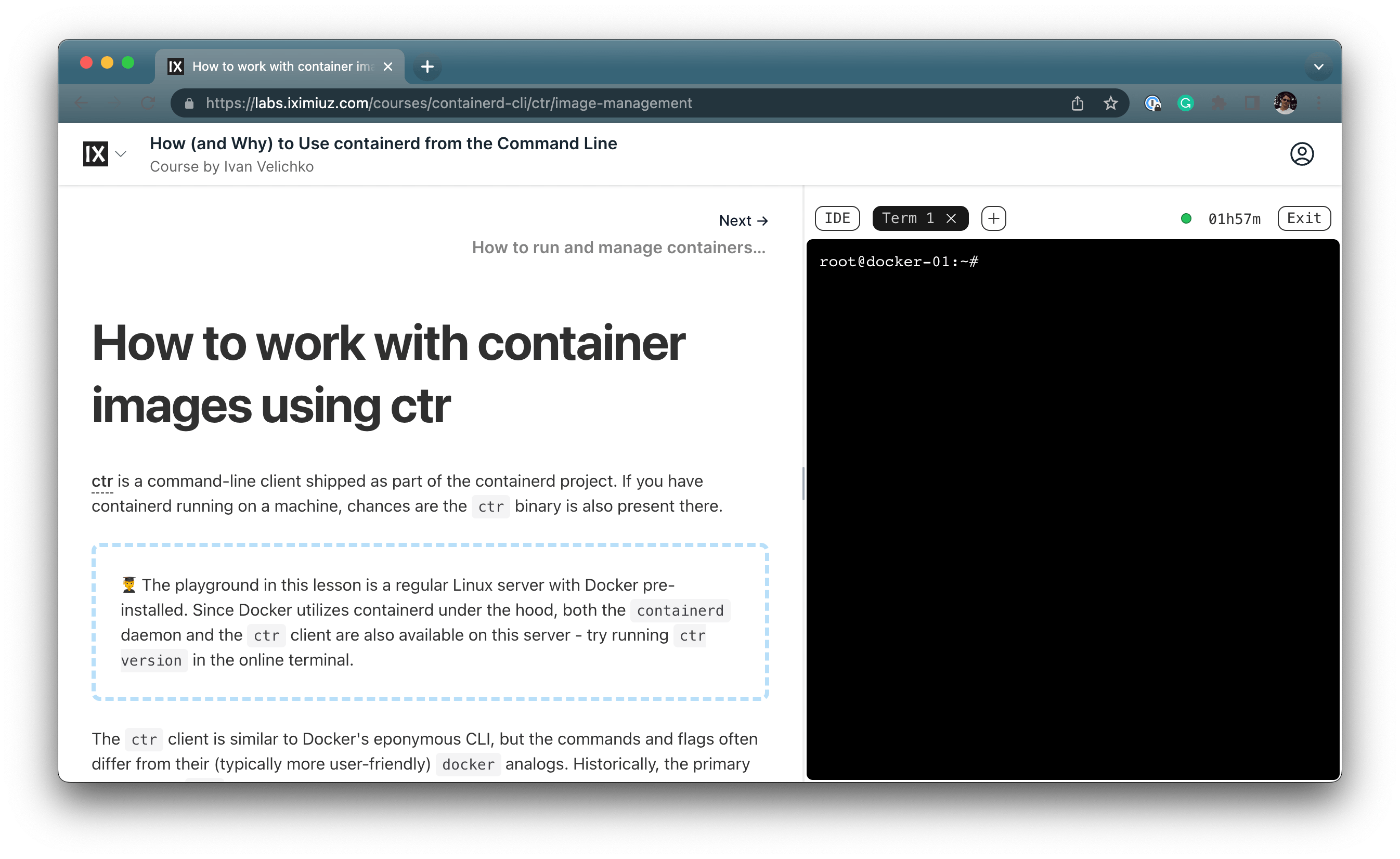
However, my personal experience with platforms providing such UX was not very positive.
I've tried a few of them, with Katacoda being the most notable one, but I was not impressed.
In the examples I've come across, the main focus would usually be on the playground capabilities and not on the educational content.
Students would often be provided with humdrum text materials on the left, from where they would have to copy-paste commands into the terminal on the right making it not very different from a regular blog post accompanied by a cloud VM.
I wanted to do better! 🤪
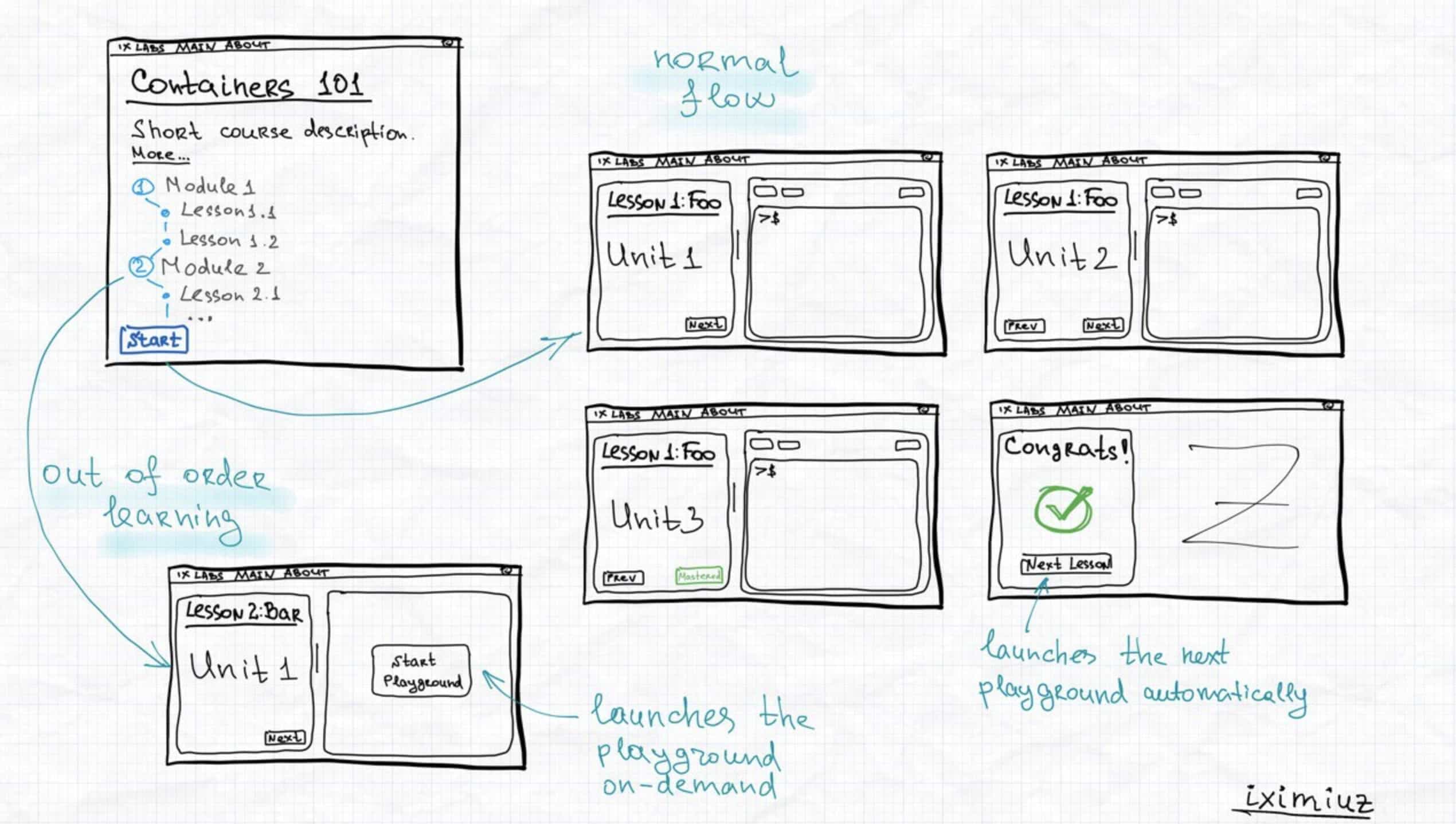
If I were to enhance my articles with playgrounds (not an easy undertaking for me at all), I wanted them to be a true integral part of the learning experience, not just a sidekick on my blog.
For me, the ultimate goal of tech education is to prepare the student to solve problems in real production environments where there is often no instructor to guide them through the process. Thus, efficient playgrounds should be designed in a way that would allow the student to learn by doing on their own, not by simply following instructions. However, if the gap between the student's current skills and the skills required to solve the problem is too big, the student would likely get stuck and give up. It meant that I had to come up with a hybrid approach allowing the student to learn the theory in a structured (by the content author) way and then giving them a chance to apply what they've just learned on practice in a less-guided production-like environment.
On my ideal learning-by-doing platform, students would be walked through the theoretical part of the content first, where they can learn the concepts and get familiar with the tools and techniques required to solve the problem. And then, they would be presented with a set of exercises to try out and better internalize their newly acquired skills.
You can think of the first, theoretical, part as my traditional deep-dive blog post, where the main focus is on the text and visuals, and the terminal on the side is just an addition (so, not very different from a proverbial KataCoda). The second, practical, part though, is meant to be something that I haven't seen in the wild much - think of LeetCode- or even CodinGame-styled exercises (with interactive solution checking, gamification elements, and whatnot) but for Docker, Kubernetes, and other typical tools and technologies used by DevOps, SRE, or Platform engineers.
Interesting that as a student, I would probably be more looking forward to the new capabilities the playgrounds give me during the practical phase of learning. However, as a teacher, I'm excited about the new possibilities that the playgrounds unlock for both, practical and theoretical, parts of education.
For the content authors, the playgrounds in the theoretical part become a new means of expression - for instance, the instructor can use the playground to animate the processes and concepts from the lesson. Just look at this PoC of a visualizer that I've come up with to explain how Kubernetes works - it utilizes the playground to run a Kubernetes cluster and render its state changes on a web canvas as the student interacts with it, all in real-time:
All this combined, it sounded like it was worth giving a shot - if I were to try, I wouldn't be building yet another KataCoda but rather a new type of educational platform that I haven't seen before and which I would enjoy using myself as a student and as a teacher.
High-level design goals
The rant above was inexcusably long, but I hope it gives you a better idea of what I'm trying to achieve with the platform as well as justifies some of the design decisions that I'm going to describe below.
As usual with system design, there's (way) more than one way to skin a cat. My main goal was to ship something that would be good enough to start with, given the very limited resources I had to dedicate to the project. My guiding principles were (and still are):
- Keep it simple - no
Kubernetesfancy tech, no large-scale cloud providers, no complex architecture. - Keep it reliable - no single point of failure and minimal probability of data loss.
- Keep it secure - limited attack surface and low incentives for the attackers.
- Keep it cheap - the main cost factor (besides my time investment) should be the servers with playground VMs and not the management infrastructure.
- Keep it realistic - the first version of the platform should scale to 100-200 active playgrounds without any major redesign, and it's fine to rewrite it from scratch if it ever needs to scale beyond that.
- Keep it productive - use only programming languages and infra components that I'm already fluent in to avoid fighting multiple battles at once.
Here is a high-level design of the platform that I came up with given the above constraints:
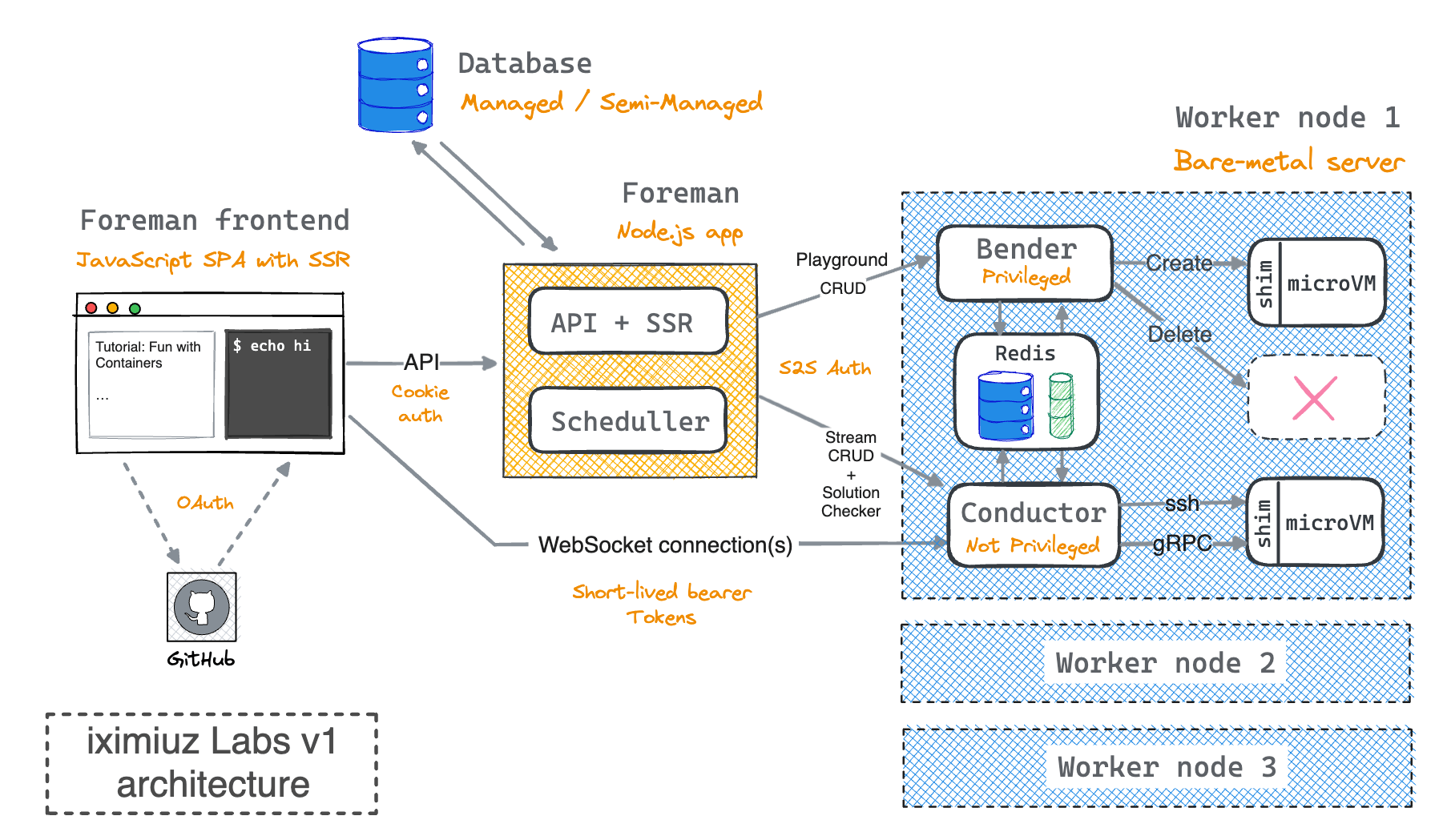
The high-level idea is that there is a (static) web application, a central component called Foreman, concerned with everything but the playgrounds, and a fleet of horizontally scalable bare-metal servers (workers) behind it, each running a number of microVMs.
Foreman component
The kitchen-sink Foreman component includes a frontend application, a backend service for it, and a number of background jobs for various bookkeeping tasks. It's by no means the most elegant approach, but it's not uncommon to structure things this way either, and since there is just a single developer (me) working on the platform, there is absolutely no need to split it into microservices just yet.
The main responsibilities of Foreman are:
- Serve the (static) frontend JavaScript application, including the server-side rendering (SSR) of some pages for better SEO.
- Implement authentication and authorization flows for end users (OAuth via GitHub at the moment).
- Provide a simple REST API for the frontend app to start and stop courses, lessons, and freeform playgrounds.
- Manage the fleet of workers and microVMs (pick the right worker server to start a new microVM on, monitor the health of the worker servers, update the status of the microVMs in the database, etc.).
- Handle basic content management tasks (create, update, delete courses, lessons, playgrounds, etc).
All Foreman's subsystems are stateless, and their operations are mostly idempotent. Even when I deploy multiple instances of Foreman, they can all work with the same database without (m)any conflicts.
From the security perspective, Foreman is likely the most sensitive component of the platform. Gaining access to it would allow the attacker to mess with the content and the users' data, and also start any number of playgrounds. However, it's not as bad as it sounds.
Messing with the content is not nice, but the mitigation is simple - I can always wipe it out and restore it from the source (all content lives in a Git repo). The user data is somewhat more concerning, but the only thing the platform collects at the moment is the user's GitHub profile ID (for authentication purposes), which is public information anyway, and the rest of the data, like the status of microVMs or users' course progress, is not so valuable outside of the platform's context. Starting an arbitrary number of playgrounds is not a big deal either - the platform is designed to run only allowed microVM images, and Foreman doesn't have control over what's allowed and what's not. So the attacker would be able to start a bunch of microVMs, but so is any other (premium) user of the platform.
Fleet of workers
This is where I had to be the most creative. Unlike Foreman, which is a pretty typical piece of software, the workers are much more exotic and required quite a bit of experimentation and prototyping to get right.
Each worker server is a bare-metal machine (because it needs to run Firecracker, and nested virtualization isn't fun) with a bunch of daemons controlling various aspects of the worker's and microVM's lifecycle.
The worker servers are meant to be horizontally scalable and independent from each other. They are also, in a way, stateless - the only state they maintain is the state of the microVMs they are running at the moment. While it may cause some temporary inconvenience for the users, if something goes wrong with the worker server (including the server being compromised), it can be simply wiped out and replaced with a new one without a ripple effect on the rest of the platform.
Bender daemon
The key component on a worker server is a daemon called Bender. It's responsible for the following:
- Pulling the template microVM rootfs and kernel images.
- Preparing student-customized Firecracker drive images.
- Configuring system resources (networking, temporary users, etc.) for microVMs.
- Launching microVMs (including maintaining a warm pool of configured but not yet started playgrounds).
- Monitoring microVMs' health and terminating failed or expired ones.
- Exposing a simple REST API for Foreman to start and stop microVMs.
In other words, Bender to microVMs is what Docker or containerd is to containers - it's a single-host container microVM management daemon with a REST API.
Due to its nature, Bender is a highly privileged component (it runs as root directly on the host 🙈), so my goal is to keep it as simple and focused as possible to minimize the attack surface. Bender is also not exposed to end users directly (ideally, I'd not even expose it to the Internet, but currently, there is no LAN between Foreman and the workers due to my choice of the hosting providers).
Luckily, Bender is the only component that needs to run as root on the worker server.
Firecracker microVMs
Every playground on iximiuz Labs consists of one or more microVMs. The goal is to give the student shell access to an ephemeral Linux machine or a group of machines connected into a virtual network.
The multi-node nature of the playgrounds, plus various security and performance considerations, made me write quite a bit of custom code on top of Firecracker:
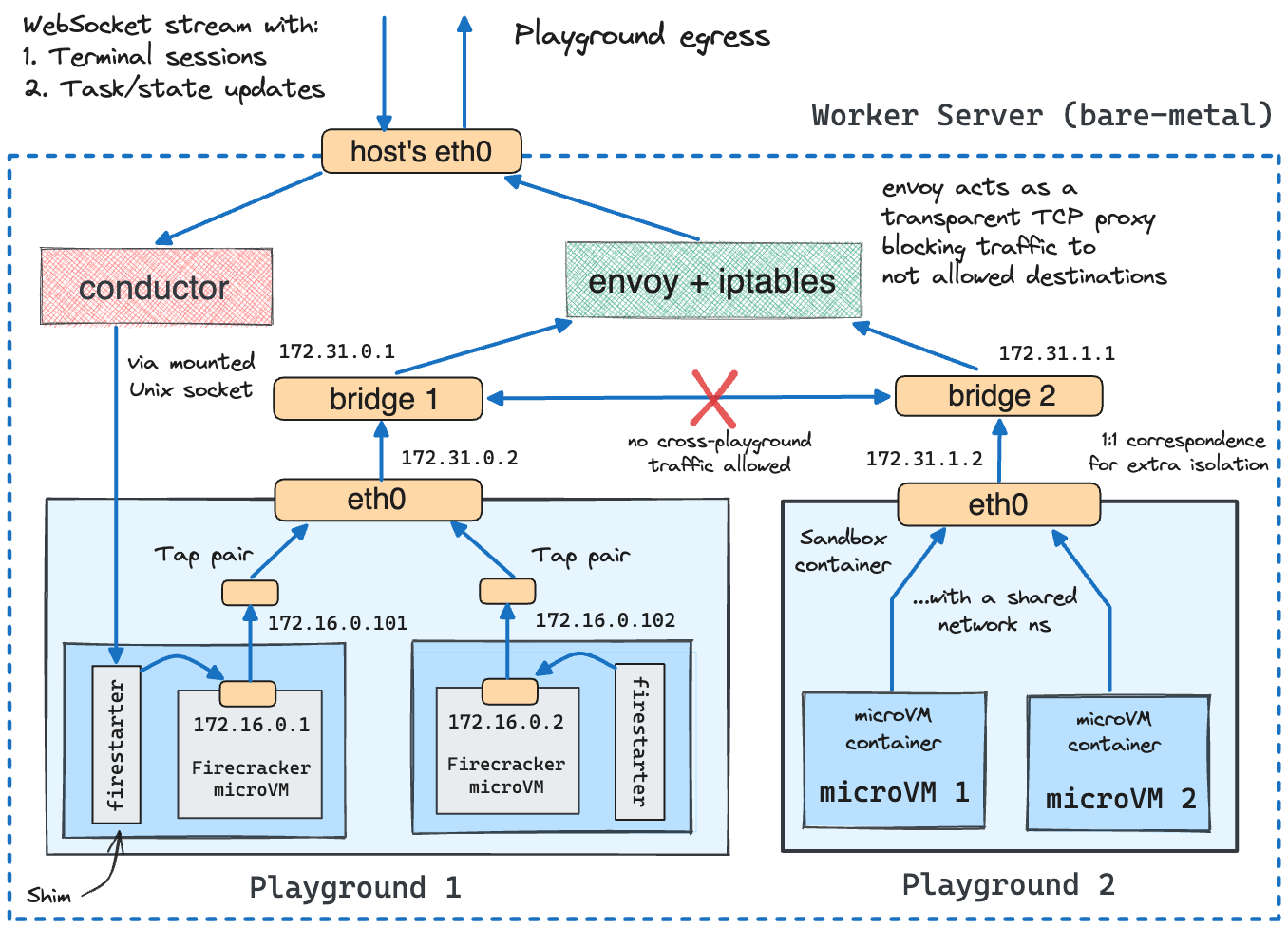
The design of the playgrounds is highly influenced by Weave Ignite and Kubernetes.
Weave Ignite taught me to run Firecracker microVMs in Docker containers - it helps a lot with network management and also simplifies the cleanup logic. To configure networking for a microVM, one needs to create a tun/tap device on the host, attach it to the microVM, and add a bunch of iptables rules to route the traffic to/from the microVM. Alex Ellis has a great GitHub project demonstrating how to do that. It's not too complicated, but when it needs to be done for tens of microVMs on a single host, and combined with the egress and side- traffic filtering, it becomes a bit of a pain to manage. However, most of the networking trickery, including the creation of tun/tap devices, can be done in an isolated network namespace of a Docker container. And when the VM is terminated, the container is terminated as well, so the cleanup is automatic (well, Docker will do it for you).
And Kubernetes inspired me to take the idea of running Firecracker microVMs in containers even further. In Kubernetes, Pods are essentially groups of semi-fused containers that share some of their namespaces, most notably the network namespace. But it sounds pretty much what I needed for my multi-node playgrounds - a group of microVMs that can communicate with each other over a virtual network can be represented as a group of containers that share the same network namespace. And every such group gets its own Docker network (with a bunch of extra firewall rules) to isolate it from the other groups.
From the security standpoint, Firecracker microVMs are the most exposed part of the platform - I give Internet strangers direct shell access to them! But they are also the most limited and isolated part of the system - each microVM gets an ephemeral non-privileged user assigned, then jailed and containerized on top of that. Even breaking out of the VM would still require the attacker to gain root access to the host. Nothing is impossible, but I personally don't know how to do that, and I'm doing my best to keep the system up-to-date with the latest security patches.
MicroVMs are resource- and rate-limited, and they are automatically terminated after a certain period of time. The egress traffic from the free-tier microVMs is not just rate-limited but also restricted to DNS and HTTP(S) and only to an allow-listed set of hosts (this part was a bit tricky to implement, but thanks to my extensive experience with Envoy and Istio, I got it seemingly right after a few iterations).
Conductor daemon
As it was supposed to be clear from its name, the Conductor daemon is concerned with passing the commands from the student to the microVMs and back. At the moment, it includes the following:
- Terminal session(s) - a bidirectional stream of bytes between the student's browser and the microVM's shell.
- Tasks - a set of commands to be executed on the microVM in accordance with the lesson's instructions.
When a browser tab is about to make a new Conductor connection, it claims a connection slot sending an authenticated request to Foreman. Foreman then issues a unique short-lived token for the connection and registers it in the corresponding Conductor instance before returning the token to the browser. Once the browser receives the token, it can establish a WebSocket connection directly to the Conductor instance on the worker server with the target microVM.
The web terminal in the browser is implemented using Xterm.js, and Conductor uses a similar to yudai/gotty approach to proxy a TTY-controlled shell session to the browser. The shell session itself is a good old SSH connection over a Unix socket which is mounted into the microVM's container and then proxied by the Firestarter shim component to the microVM's tap interface.
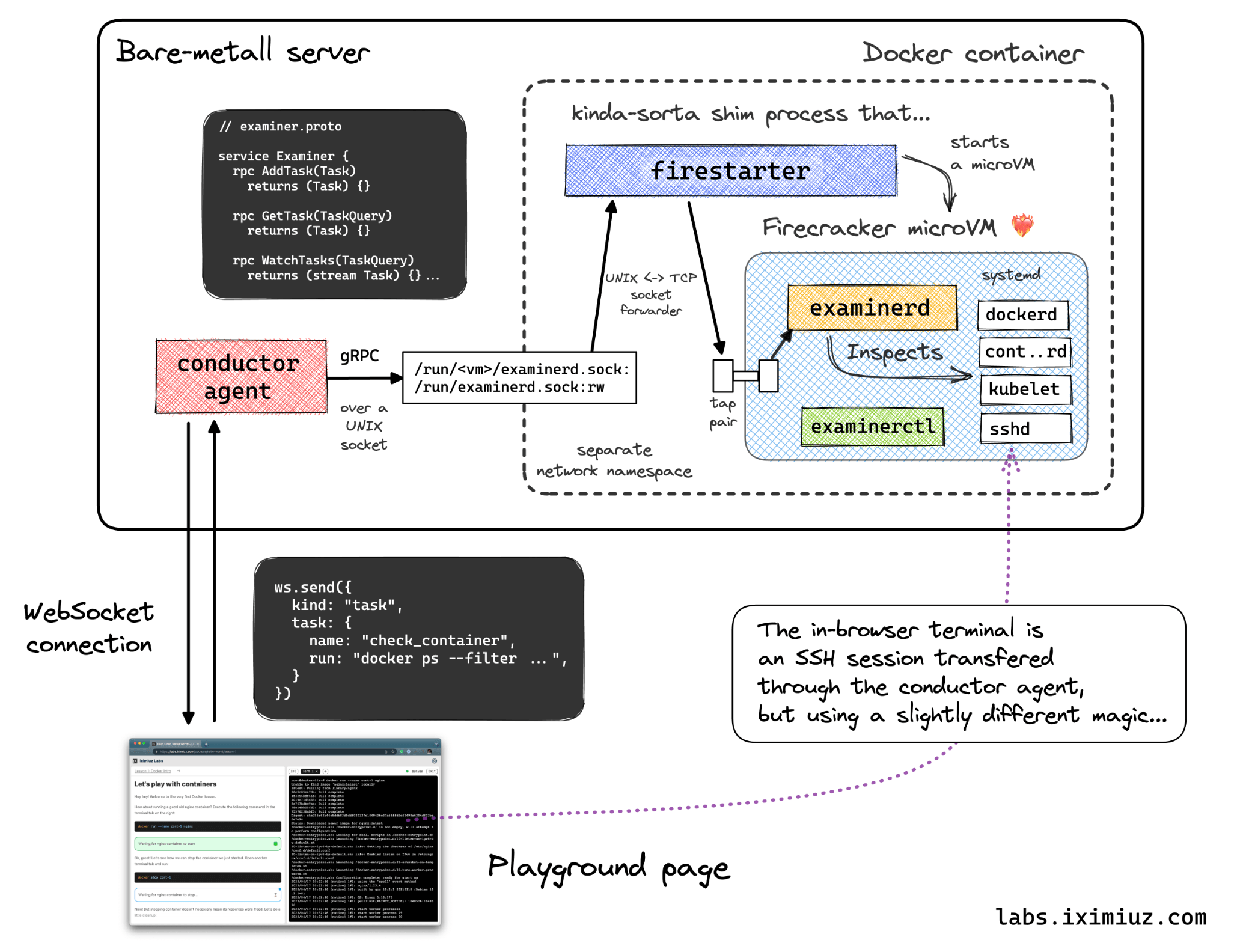
The tasks are also passed to the playground via a WebSocket connection to Conductor. I'll touch on the tasks in more detail in the next section, but for now, it's enough to know that they are just a set of commands authored by the lesson's author and executed on the microVM in a predefined order. When a task changes its state (e.g., from pending to running or from running to finished), Conductor notifies the browser page about it via a WebSocket message. This is how the student's progress is tracked and visualized in the browser.
Automatic solution-checking subsystem
The automatic solution checking is one of the most interesting parts of iximiuz Labs. Even more, it's likely the key differentiator at the moment. The subsystem deserves a separate blog post, which I should definitely write one day, but for now, I'll just give you a high-level overview and highlight the most interesting technical challenges I had to overcome.
The automatic solution-checking subsystem is based on the concept of tasks. Tasks are low-level building blocks behind the content's interactive elements and the exercises in the practice sections. The content author can define a set of commands, in a similar way GitHub Actions pipelines are written, that will be sent to the playground microVMs upon starting the lesson (or the exercise).
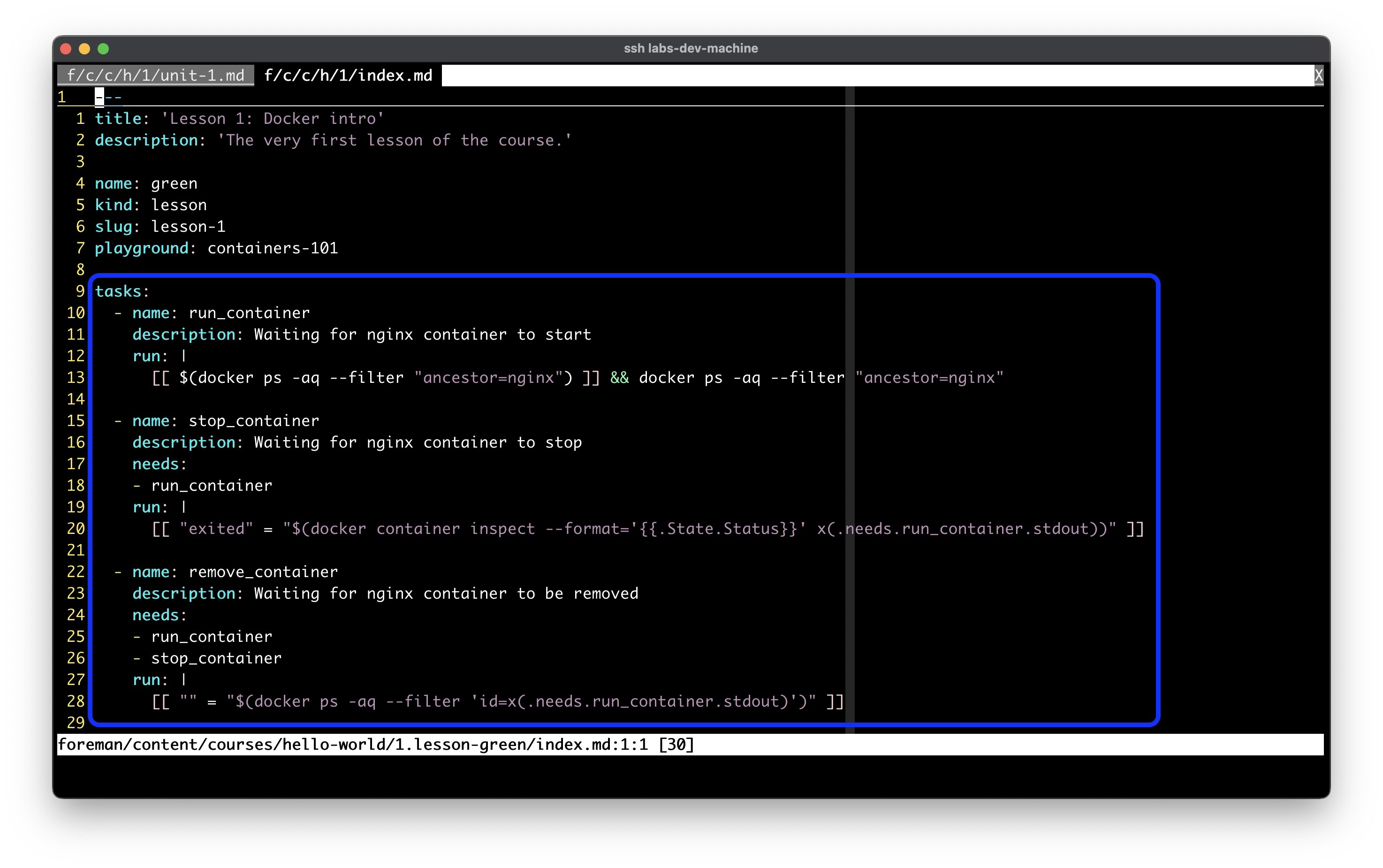
On the microVM side, the commands are organized in a directed acyclic graph (DAG) and then periodically executed by a special daemon called Examiner. If the task's command terminates with a non-zero exit code or times out, it's (almost) immediately retried. And when a command finally finishes successfully, the browser page gets notified about it via a WebSocket message passed through Conductor.
The original idea was to (re-)use the SSH sessions (from the web terminal implementation) to pass the commands from Conductor to Examiner daemons:
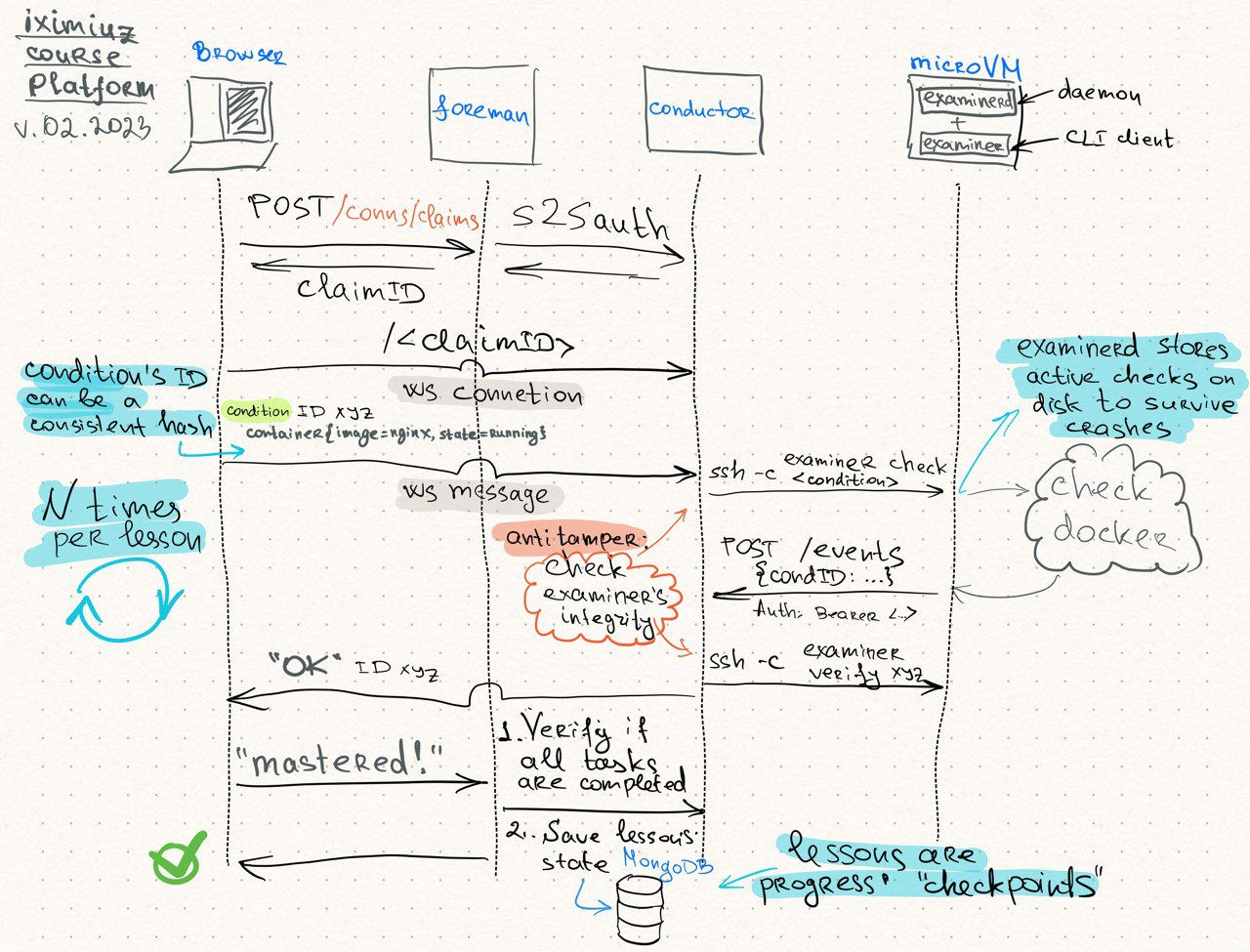
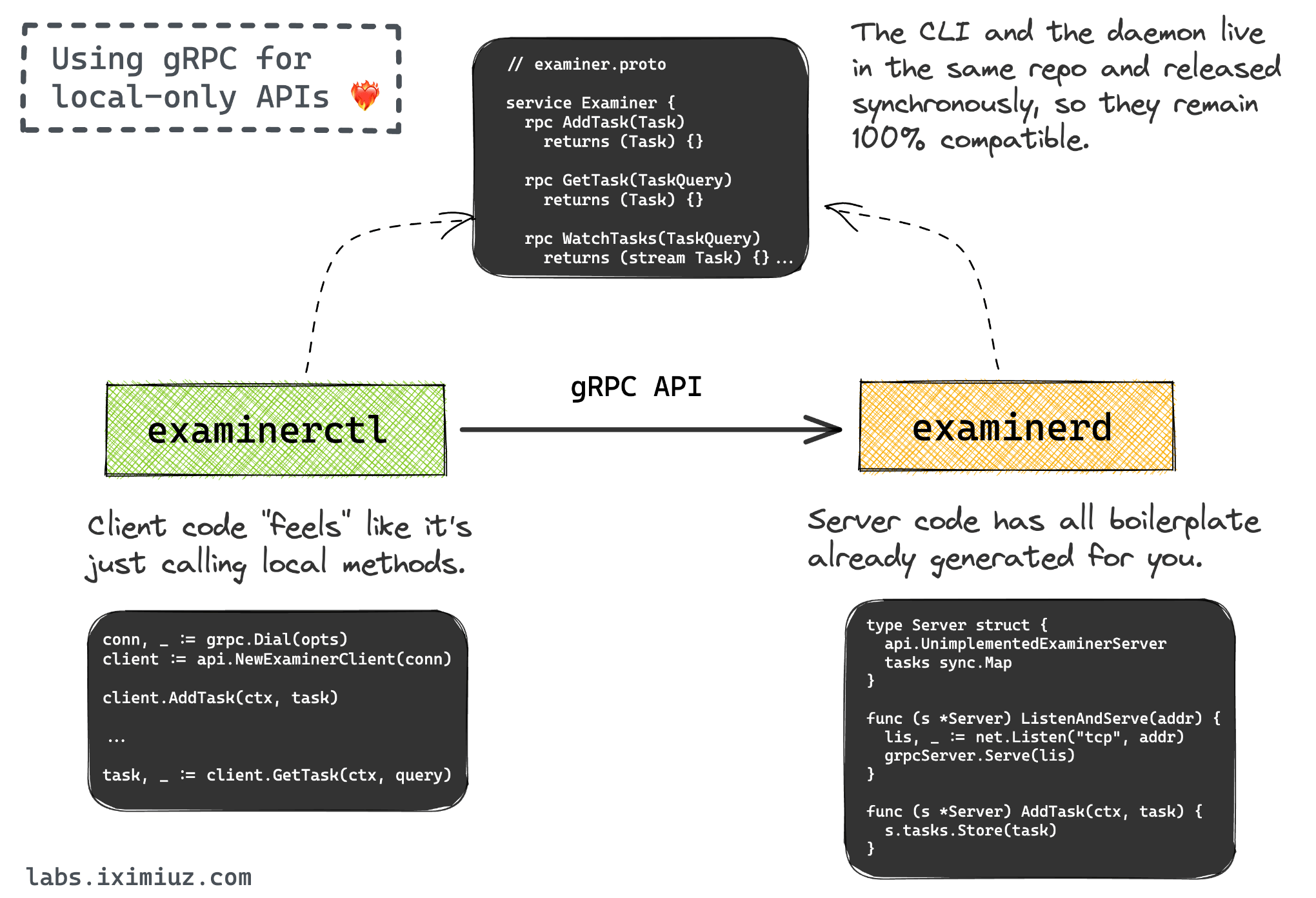
However, the implementation turned out to be too complex and unreliable, especially when it came to timely reporting the task's state changes to the browser. Surprisingly, the help came from the most unexpected place - gRPC! gRPC is a perfect fit for the local communication between a daemon and its CLI client - different projects, including containerd, use it for that purpose. The Examiner daemon had already been using gRPC for the communication with its CLI client, examinerctl, meaning:
- Conductor could use the same gRPC client directly to pass the commands to the Examiner daemon instead of executing them via examinerctl over SSH.
- gRPC streams could be used to notify Conductor, and transitively the browser, about the task's state changes in a timely and reliable manner.
Choosing the technology stack
It's not hard to notice that the above components are very diverse in their nature. Thus, picking a single programming language or a framework for the whole platform was not an option. However, since the toolchain sprawl is a real problem, I tried to minimize the number of technologies involved as much as possible.
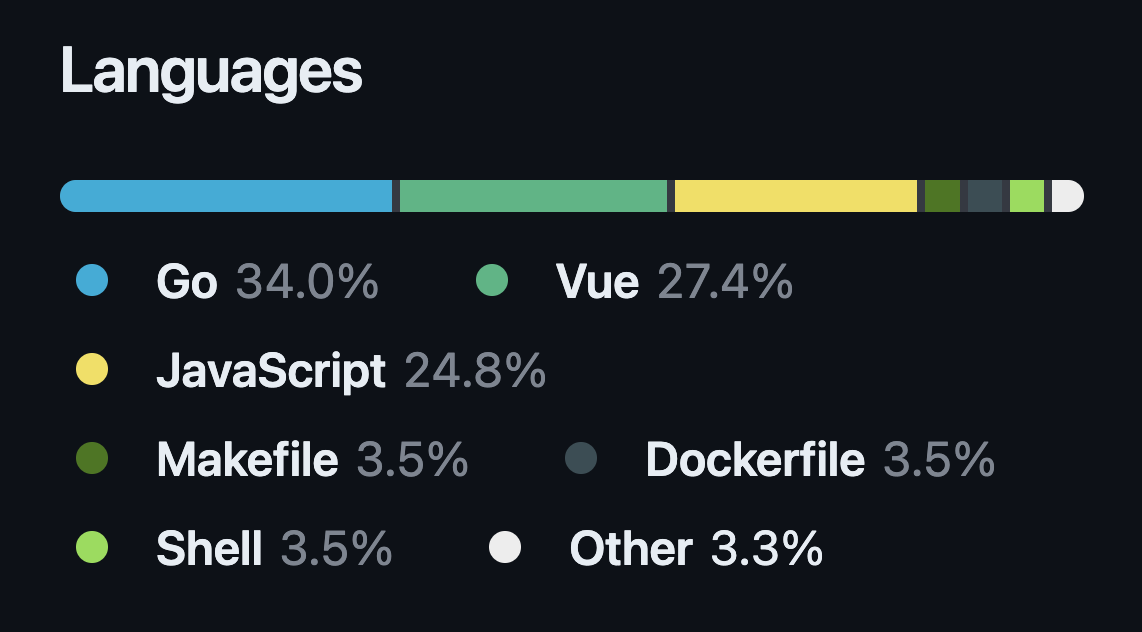
The need for developing a frontend app made the choice of JavaScript (or TypeScript) a no-brainer. Hypothetically, I could have used Node.js for system daemons as well, but most of the projects in the Cloud Native space are written in Go, and I didn't want to fight the ecosystem. So, Go it was. But that's where I stopped. Despite my warm feelings towards Python and Rust, I didn't want to introduce yet another language into the mix. The tandem of Go and JavaScript is not my favorite, but it covers all the bases, and historically I've been pretty productive with it.
Frontend app and API layer
Initially, I thought I'd use Vue.js for the frontend app (the only web framework I'm more or less fluent in) and put an API server behind it written in Go. However, I soon realized that I'd need to implement the server-side rendering (SSR) for SEO purposes - after all, that's one of the main traffic sources for my blog at the moment. So it made me try Nuxt 3, and rather unexpectedly, I liked it! Nuxt 3 was just released out of beta, still a bit rough around the edges, and with very limited documentation, but nevertheless, I managed to bootstrap a simple app with SSR and a REST API in a matter of hours. Six months later, I'm still using Nuxt 3, and I'm even happier with my choice now.
To avoid dealing a lot with the basic UI components, I bought the Tailwind UI kit and befriended it with daisyUI - the Frankenstein's monster I'm not proud of, but it worked! Overall, I was pleasantly surprised by how much a hardcore backend engineer can achieve with the modern frontend stack these days:
I've been solo-building a pet project for a few months, and I'm pleasantly surprised by how much a hardcore backend engineer can achieve with the modern frontend stack! 💪
— Ivan Velichko (@iximiuz) March 27, 2023
A thread on tools and tricks that helped me to develop a Web UI for iximiuz Labs 🧵 pic.twitter.com/nrpVLUVe1T
The built-in API layer in Nuxt 3 turned out to be so handy, that I decided not to implement a separate API server in Go, at least for now. But if there is no separate API server, why not to try putting the background jobs into the Nuxt app as well? That's how the main business logic of the platform ended up being implemented in JavaScript 🙈
Backend worker servers and infra glue
Two main daemons that live on the worker servers are written in Go. One of them is launched as a systemd service, and the other one runs in a Docker container. Both daemons expose HTTP APIs (via chi), and one of the daemons also has a built-in WebSocket server (via the archived gorilla/websocket package).
Docker is heavily (ab)used all over the platform:
- For development purposes - various dev tools are containerized.
- As a means to package and deploy the daemons, microVM rootfs and kernel images, etc.
- As a runtime for one of the daemons and surrounding infrastructure (Redis, Nginx, Envoy, etc.).
- As a runtime for playgrounds - Firecracker microVMs are launched inside Docker containers.
Interesting that playgrounds at the moment are also described in Dockerfiles, then built as Docker images, and stored in a private Docker registry. When the playground management daemon needs to start a new playground, it pulls the image from the registry, extracts it into a directory, and creates a Firecracker drive image from its contents.
Other notable technologies used on worker servers are:
- Nginx - as a reverse-proxy in front of the backend daemons.
- Envoy - as a transparent TCP egress proxy for the microVMs.
- Redis - as a storage for daemons' state and as a message broker between them.
Hosting and data storage providers
I've considered quite a few options for hosting the platform, and it wasn't an easy choice. The goals were:
- Keep the costs as low as possible.
- Avoid managing some pieces (e.g., frontend ingress, databases, etc.).
- ...but retain the ability to manage the others (e.g., the frontend app itself, the worker servers, etc).
- Choose a geographically scalable solution (students' proximity to the VMs is important).
For the frontend app, I honestly tried to stay open-minded and considered all the fancy serverless-ish and edge-y solutions - Vercel, Netlify, Firebase, to name a few.
However, I ended up using good old cloud VMs more traditional fly.io Machines.
The amount of control over the frontend app Fly Machines give me is close to ideal - I can package in a container whatever (and however) I want and deploy it to a bunch of cheap VMs in a bunch of regions in a matter of seconds.
The ingress (including TLS termination and load balancing) and the automatic restarts on failure will be managed by fly.io.
The only thing that is not covered by fly.io yet is (more or less advanced) observability, but I'm hoping it'll be addressed soon.
For the storage layer, I tried to be open-minded again (considered Supabase, Fauna, Xata, Upstash...), but in the end, I decided to go with the most boring option - MongoDB Atlas (with point-in-time backups). I almost chose Fly's (semi-managed) Postgres offering, but at the time, the failback (after a failover) was not working as expected, and I didn't want to deal with it. I should probably give it another try, though, because MongoDB is great for production but not so great for analytics and reporting (at least in my experience).
The choice for the worker servers was much easier - Hetzner Auction is the cheapest bare-metal hosting I've ever known (I currently pay ~$40/mo for a server with 128GB RAM and 6 cores), on which I can fit tens of concurrent playgrounds. And if I ever need to expand to other regions, I'll likely try finding a similar hosting provider in the Americas and/or Asia.
The total monthly infra bill is currently around $100, where 80-90% of it is the cost of the worker servers.
What's next on the roadmap?
Content, of course! I've already finished the first module (with two solid lessons) of my course on containerd, but after blogging about containers for almost five years, I've accumulated soooo many content ideas... Now I finally have a platform to implement them on!
On the feature side, things that I'm planning to add next are:
- IDE integration (Eclipse Theia or the like) - apparently, not everyone is a Vim fan 🤷♂️
- Multi-node playgrounds - the engine is already there, but the UI needs to catch up 👷♂️
- Kubernetes visualizer from the video at the beginning of the article ❤️🔥
One of the dream goals is to open-source Bender and the Firecracker rootfs generation tooling. However, before I can find a sustainable way to fund the work on the platform, I'm not sure if I can afford to spend time on it.
Of course, the users should have control over the roadmap too, not just me. And speaking of the users, I'm staying open-minded - initially, I built the platform for myself (as an author) and for the readers of my blog (as students), but I can see it being used by other educators and/or the students themselves to create and share their own labs. Companies can use it to train their employees or conduct automated job interviews - something similar to HackerRank but for DevOps topics. And universities can potentially use it to teach CS students. The possibilities are endless (tm) 🚀
Acknowledgments
I want to thank a few amazing people who helped me a lot on my journey to build iximiuz Labs:
Nuno do Carmo and Slavina Stefanova - for the tremendous QA work you've done for the platform and for all the invaluable feedback you've provided.
Alex Ellis - for being the inspiration (in particuar, with your Firecracker-powered GitHub Actions runners) and for the awesome tools and content you've been creating for the community (some of them, like arkade power the labs).
All my Patrons - for your financial support and patience while I was working on the platform instead of writing blog posts.
P.S. If you liked this blog post and want to see iximiuz Labs evolve, please consider supporting my work on Patreon - it'll help me to dedicate more time to the platform and to write more blog posts like this one. Patrons get premium access to the platform, of course! 😉
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox:
