How HTTP Keep-Alive can cause TCP race condition
These mysterious HTTP 502s happened to me already twice over the past few years. Since the amount of service-to-service communications every year goes only up, I expect more and more people to experience the same issue. So, sharing it here.
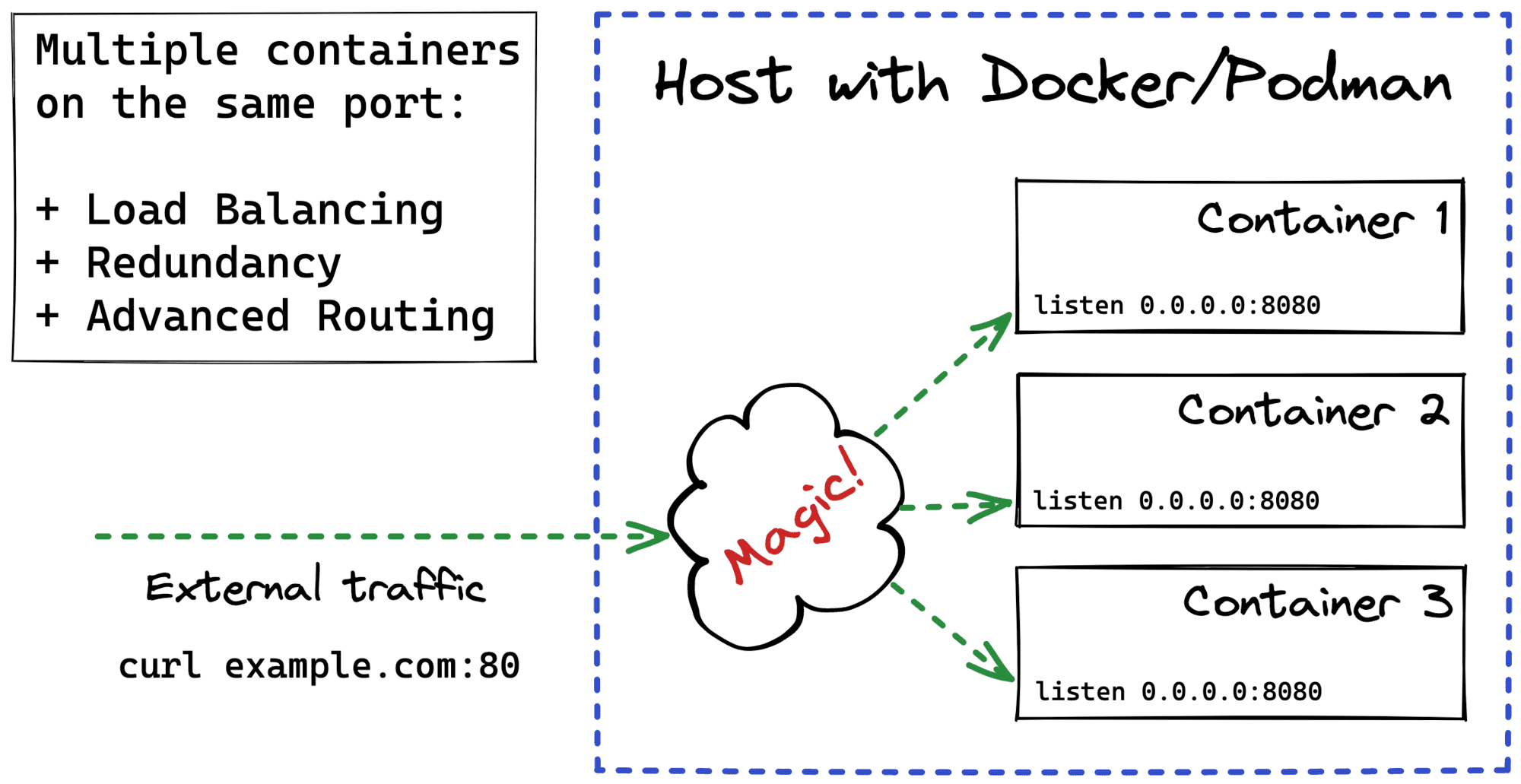
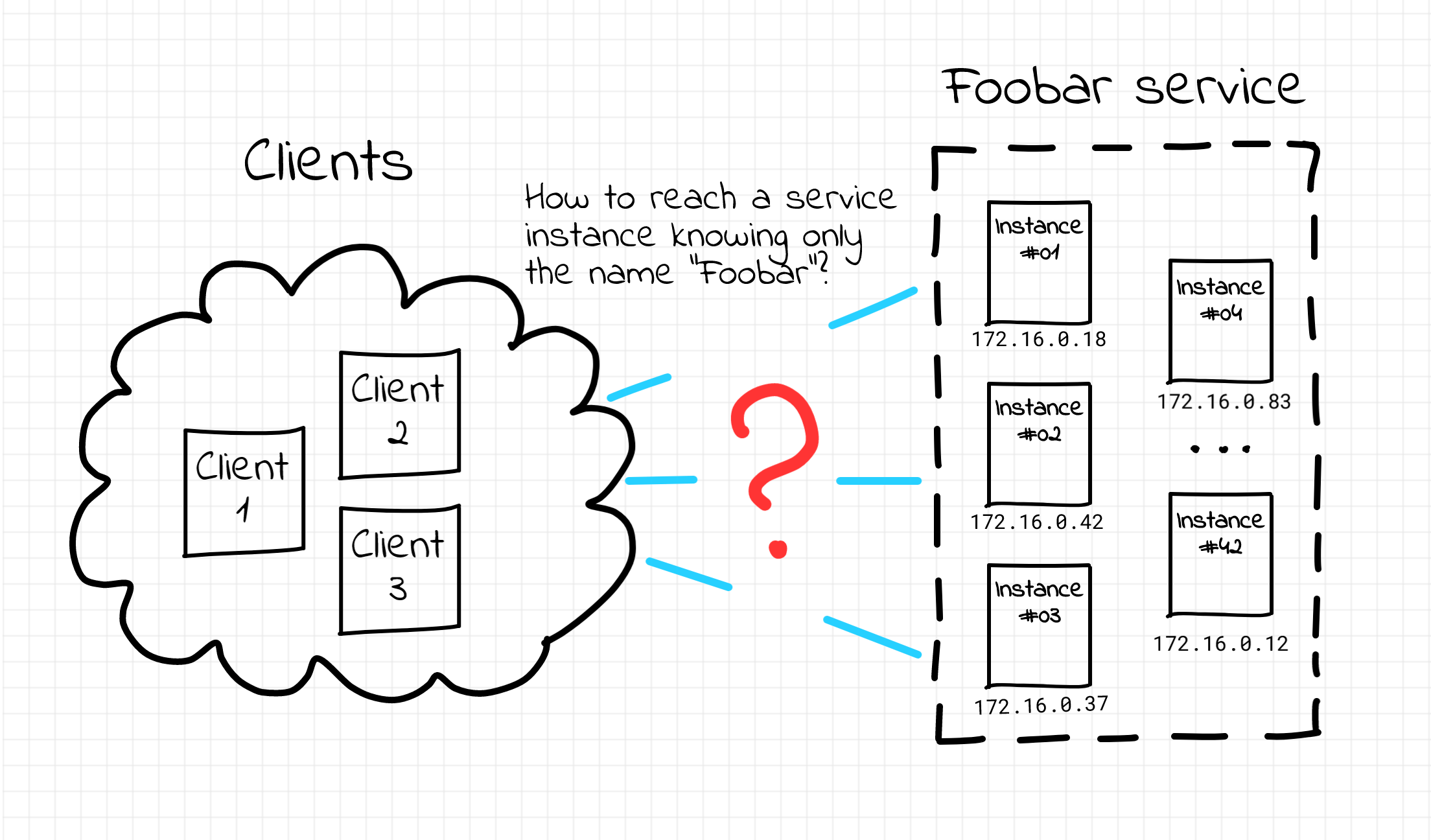
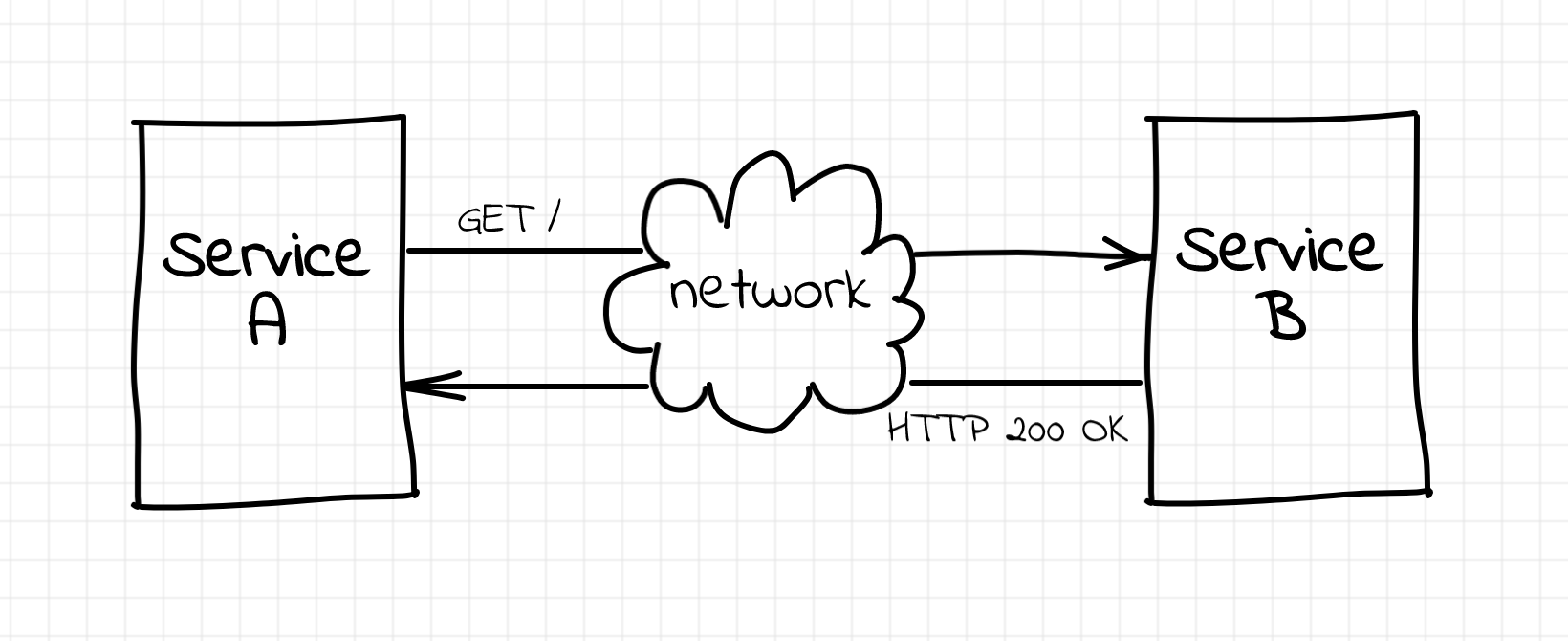
TL;DR: HTTP Keep-Alive between a reverse proxy and an upstream server combined with some misfortunate downstream- and upstream-side timeout settings can make clients receiving HTTP 502s from the proxy.