- Container Networking Is Simple!
- What Actually Happens When You Publish a Container Port
- How To Publish a Port of a Running Container
- Multiple Containers, Same Port, no Reverse Proxy...
- Service Proxy, Pod, Sidecar, oh my!
- Service Discovery in Kubernetes: Combining the Best of Two Worlds
- Traefik: canary deployments with weighted load balancing
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
Before jumping to any Kubernetes specifics, let's talk about the service discovery problem in general.
What is Service Discovery
In the world of web service development, it's a common practice to run multiple copies of a service at the same time. Every such copy is a separate instance of the service represented by a network endpoint (i.e. some IP and port) exposing the service API. Traditionally, virtual or physical machines have been used to host such endpoints, with the shift towards containers in more recent times. Having multiple instances of the service running simultaneously increases its availability and helps to adjust the service capacity to meet the traffic demand. On the other hand, it also complicates the overall setup - before accessing the service, a client (the term client is intentionally used loosely here; oftentimes a client of some service is another service) needs to figure out the actual IP address and the port it should use. The situation becomes even more tricky if we add the ephemeral nature of instances to the equation. New instances come and existing instances go because of the non-zero failure rate, up- and downscaling, or maintenance. That's how a so-called service discovery problem arises.
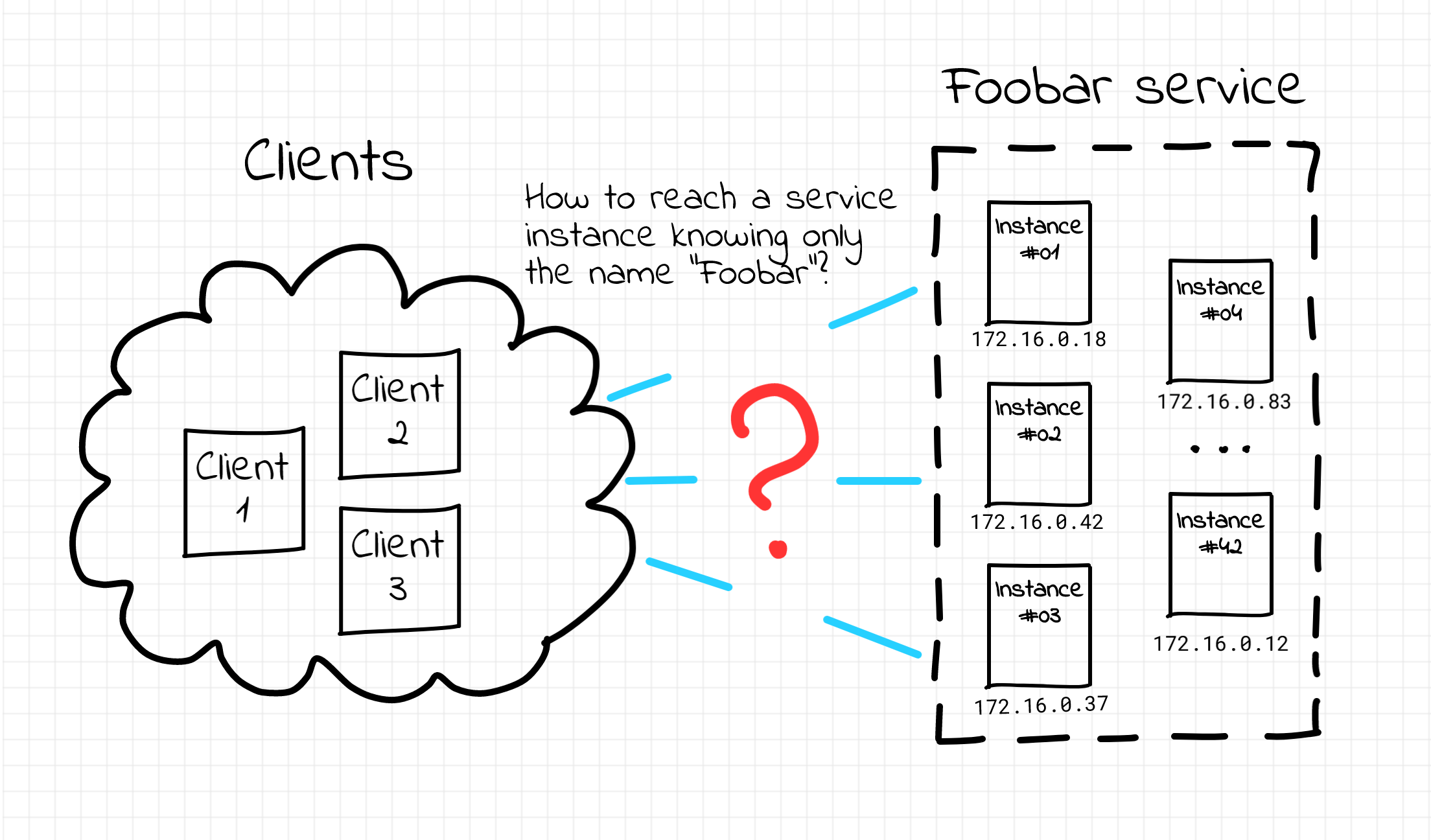
Service discovery problem.
Server-Side Service Discovery
A pretty common way of solving the service discovery problem is putting a load balancer aka reverse proxy (e.g. Nginx or HAProxy) in front of the group of instances constituting a single service. An address (i.e. DNS name or less frequently IP) of such a load balancer is a much more stable piece of information. It can be communicated to the clients on development or configuration stages and assumed invariable during a single client lifespan. Then, from the client standpoint, accessing the multi-instance service is no different from accessing a single network endpoint. In other words, the service discovery happens completely on the server-side.
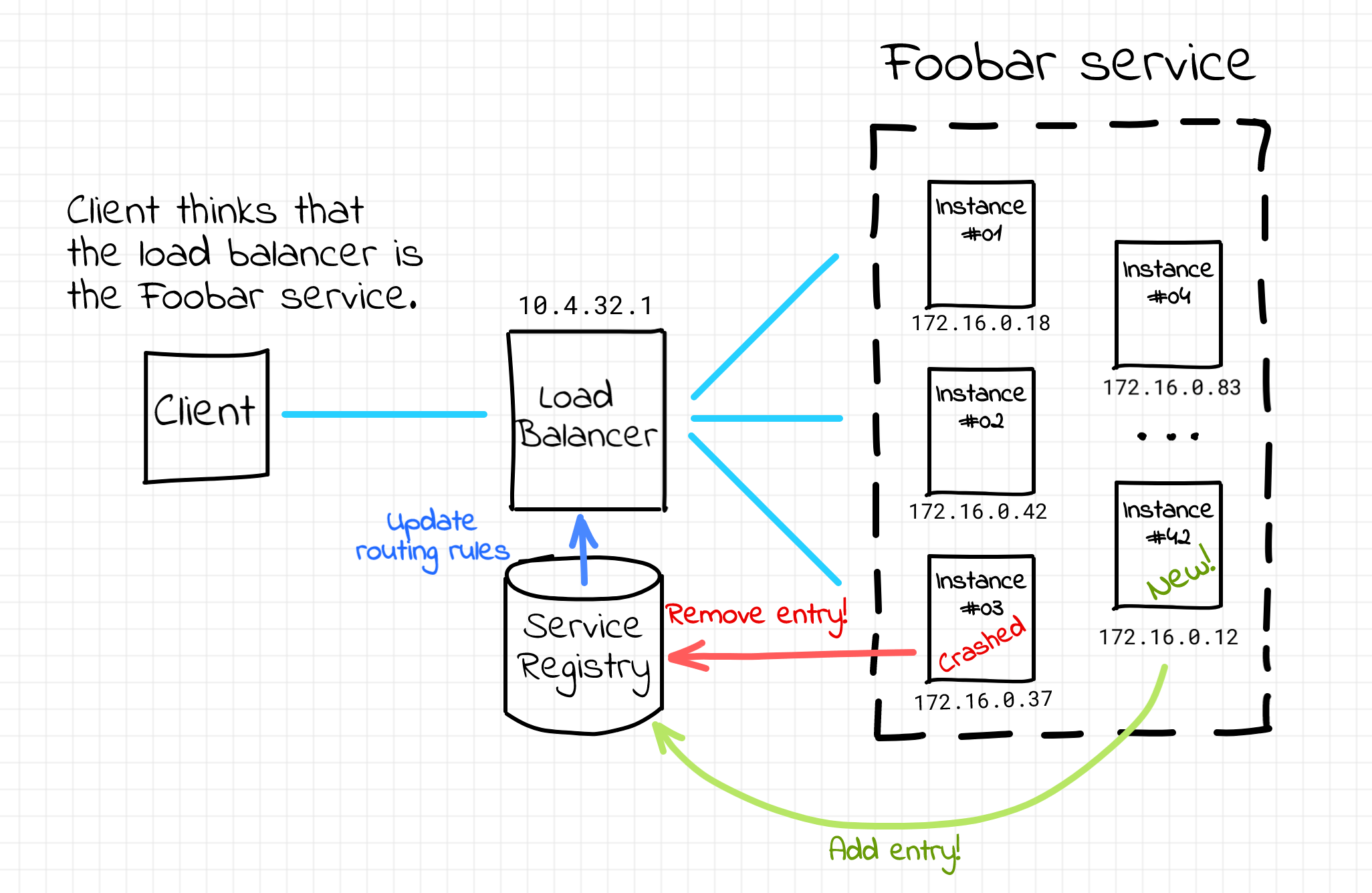
Server-side service discovery.
The load balancer abstracts the volatile set of service instances away from the clients. However, the load balancer itself needs to be aware of the up to date state of the service fleet. This can be achieved by adding a service registry component. On the startup, an instance needs to be added to the registry database. Upon the termination, the instance needs to be removed from it. One of the main tasks of the load balancer is to dynamically update its routing rules based on the service registry information.
While it looks very appealing from the client standpoint, the server-side service discovery may quickly reveal its downsides, especially in highly-loaded environments. The load balancer component is a single point of failure and a potential throughput bottleneck. To overcome this, the load balancing layer needs to be designed with a reasonable level of redundancy. Additionally, the load balancer may need to be aware of all the communication protocols used between services and clients and there will be always an extra network hop on the request path.
Client-Side Service Discovery
Can we solve the service discovery problem without introducing the centralized load balancing component? Sure! If we keep the service registry component around, we can teach the clients to look up the service instance addresses in the service registry directly. After fetching the full list of IP addresses constituting the service fleet, a client could pick up an instance based on the load balancing strategy at its disposal. In such a case, the service discovery would be happening solely on the client-side. Probably the most prominent real-world implementation of the client-side service discovery is Netflix Eureka and Ribbon projects.
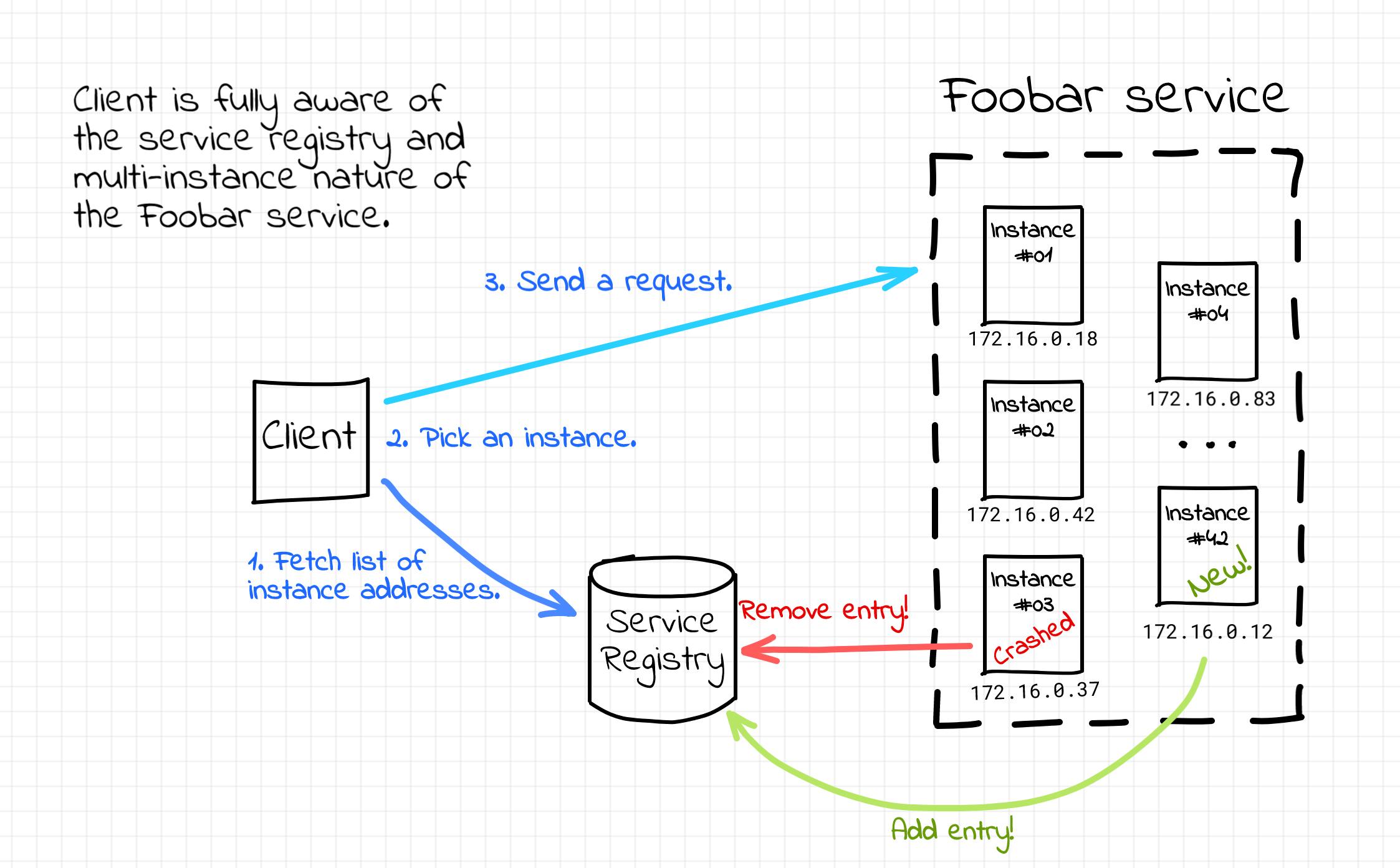
Client-side service discovery.
The benefits of the client-side approach mostly come from the absence of the load balancer. There is neither a single point of failure nor a potential throughput bottleneck in the system design. There is also one less moving part which is usually a good thing and no extra network hops on the packet path.
However, as with the server-side service discovery, there are some significant drawbacks as well. Client-side service discovery couples clients with the service registry. It requires some integration code to be written for every programming language or framework in your ecosystem. And obviously, this extra logic complicates the clients. There seem to be an effort to offload the client-side service discovery logic to the service proxy sidecars but that's already a different story...
DNS and Service Discovery
Service discovery can be implemented in more than just two ways. There is a well-known DNS-based service discovery (DNS-SD) approach that actually even predates the massive spread of microservices. Quoting the Wikipedia, "a client discovers the list of available instances for a given service type by querying the DNS PTR record of that service type's name; the server returns zero or more names of the form <Service>.<Domain>, each corresponding to a SRV/TXT record pair. The SRV record resolves to the domain name providing the instance..." and then another DNS query can be used to resolve a chosen instance's domain name to the actual IP address. Wow, so many layers of indirection, sounds fun 🙈
I never worked with DNS-SD, but to me, it doesn't sound like full-fledged service discovery. Rather, DNS is used as a service registry, and then depending on the dislocation of the code that knows how to query and interpret DNS-SD records, we can get either a canonical client-side or a canonical server-side implementation.
Alternatively, Round-robin DNS can be (ab)used for service discovery. Even though it was originally designed for load balancing, or rather load distribution, having multiple A records for the same hostname (i.e. service name) returned in a rotating manner implicitly abstracts multiple replicas behind a single service name.
In any case, DNS has a significant drawback when used for service discovery. Updating DNS records is a slow procedure. There are multiple layers of caches, including the client-side libraries, and historically record's TTL isn't strictly respected. As a result, propagating the change in the set of service instances to all the clients can take a while.
Service Discovery in Kubernetes
First, let's play an analogy game!
If I were to draw some analogies between Kubernetes and more traditional architectures, I'd compare Kubernetes Pods with service instances. Pods are many things to many people, however, when it comes to networking the documentation clearly states that "...Pods can be treated much like VMs or physical hosts from the perspectives of port allocation, naming, service discovery, load balancing, application configuration, and migration."
If Pods correspond to individual instances of a service, I'd expect a similar analogy for the service, as a logical grouping of instances, itself. And indeed there is a suitable concept in Kubernetes called... surprise, surprise, a Service. "In Kubernetes, a Service is an abstraction which defines a logical set of Pods and a policy by which to access them (sometimes this pattern is called a micro-service)."
Strengthening the analogy, the set of Pods making up a Service should be also considered ephemeral because neither the Pods' headcount nor the final set of IP addresses is stable. Thus, in Kubernetes, the problem of providing a reliable service discovery remains actual.
While creating a new Service, one should choose a name that will be used to refer to the set of Pods constituting the service. Among other things, the Service maintains an up to date list of IP addresses of its Pods organized as an Endpoints (or EndpontSlice since Kubernetes 1.17) object. Citing the documentation one more time, "...if you're able to use Kubernetes APIs for service discovery in your application, you can query the API server for Endpoints, [I guess using the Service name] that get updated whenever the set of Pods in a Service changes." Well, sounds like an invitation to implement a cloud native Kubernetes-native client-side service discovery with the Kubernetes control plane playing (in particular) the role of the service registry.
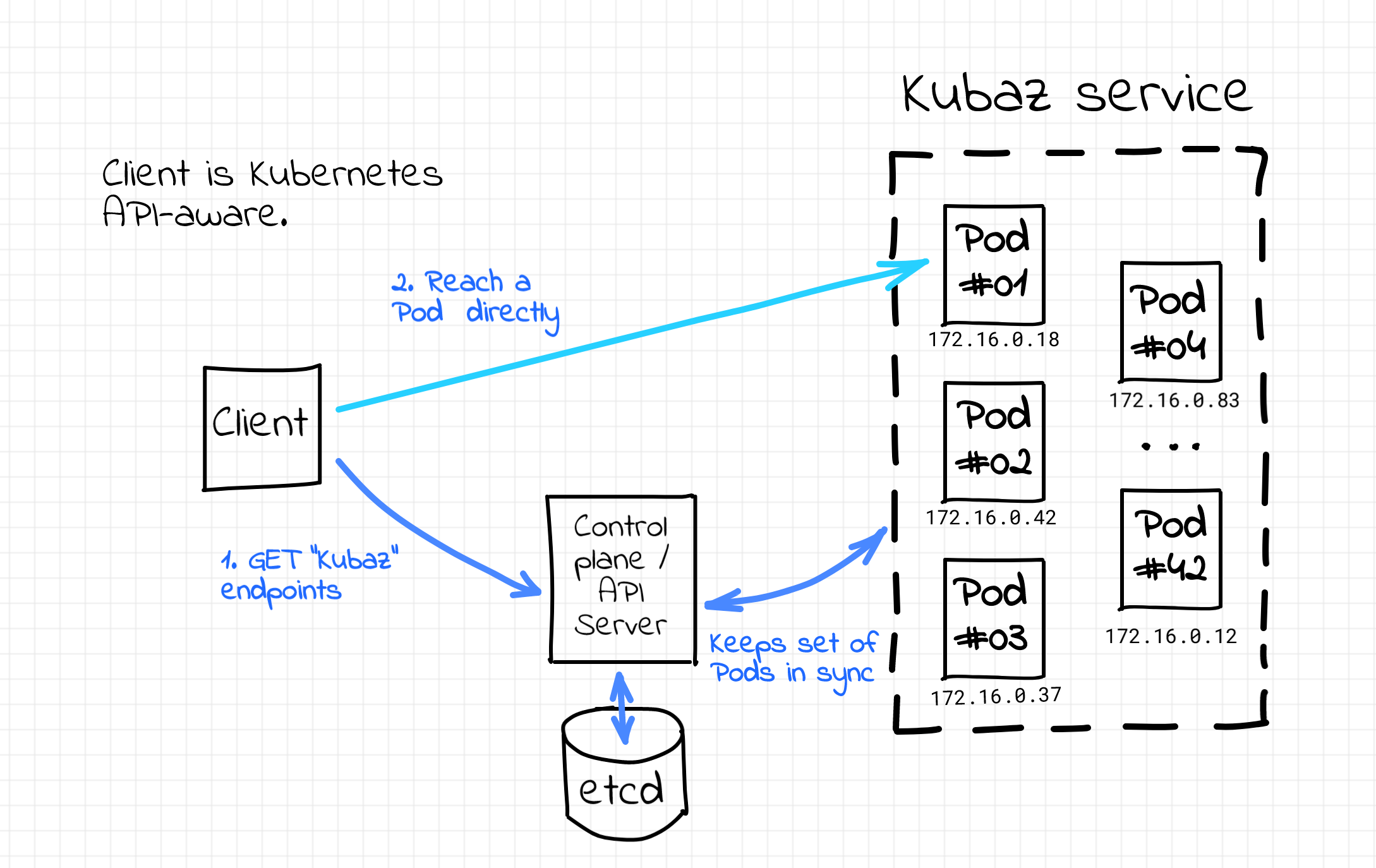
Kubernetes-native client-side service discovery.
However, the only real-world usage of this mechanism I've stumbled upon so far was in the service mesh kind of software. It's a bit unfair to mention it here though because service mesh itself is needed to provide, in particular, the service discovery mechanism for its users. So, if you're aware of the client-side service discovery implementations leveraging Kubernetes Endpoints API please drop a comment below.
Luckily, as with many other things in Kubernetes, there's more than one way to skin a cat to get the service discovery done. And the applications that weren't born Cloud Native (i.e. 99% of them) will likely find the next service-discovery mechanism much more appealing.
Network-Side Service Discovery
Disclaimer: I've no idea if there is such thing as network-side service discovery in other domains and I've never seen the usage of this term in the microservices world. But I find it funny and suitable for the purpose of this paragraph.
In Kubernetes, the name of a Service object must be a valid DNS label name. It's not a coincidence. When the DNS add-on is enabled (and I guess it's almost always the case), every Service gets a DNS record like <service-name>.<namespace-name>. Obviously, this name can be used by applications to access the service and it simplifies the life of the clients to the highest possible extent. A single well-known address behind every Service eradicates the need for any service discovery logic on the client-side.
However, as we already know, DNS is often ill-suited for service discovery and the Kubernetes ecosystem is not an exception. Therefore, instead of using round-robin DNS to list Pods' IP addresses, Kubernetes introduces one more IP address for every service. This IP address is called clusterIP (not to be confused with the ClusterIP service type). Similar to the DNS name, this address can be used to transparently access Pods constituting the service.
There is actually no hard dependency on DNS for Kubernetes applications. Clients can always learn a clusterIP of a service by inspecting their environment variables. Upon a pod startup for every running service Kubernetes injects a couple of env variables looking like <service-name>_SERVICE_HOST and <service-name>_SERVICE_PORT.
Ok, here is one more analogy. The resulting (logical) setup looks much like a load balancer or reverse proxy sitting in front of the set of virtual machines.
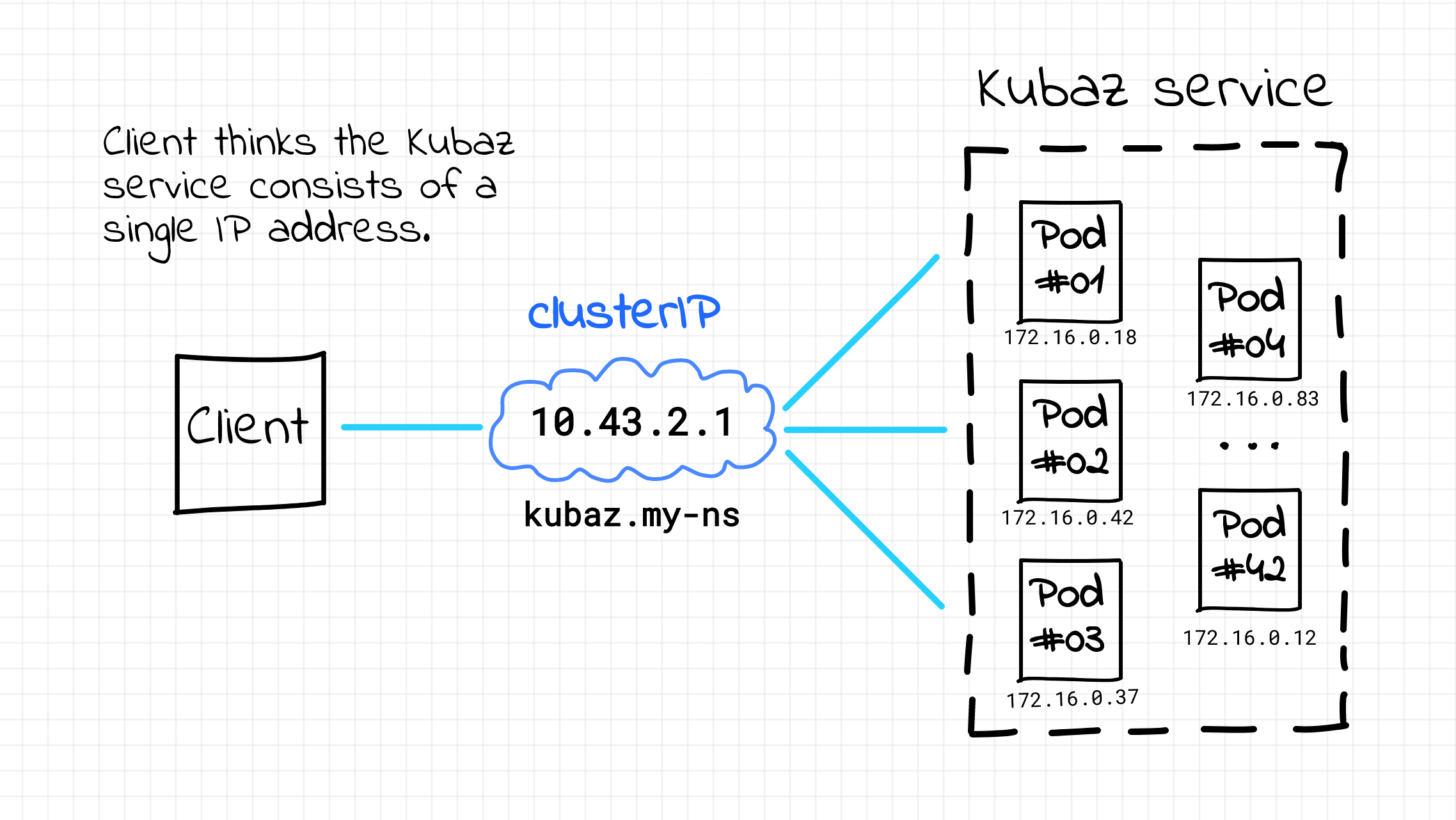
Server-side (logically) service discovery in Kubernetes.
But there is more to it than just that. This clusterIP is a so-called virtual address. When I stumbled upon the concept of the virtual IP for the first time it was a real mind-bender.
A virtual IP basically means that there is no single network interface in the whole system carrying it around! Instead, there is a super-powerful (and likely underappreciated) background component called kube-proxy that magically makes all the Pods (and even Nodes) thinking the Service IPs do exist: "Every node in a Kubernetes cluster runs a kube-proxy. kube-proxy is responsible for implementing a form of virtual IP for Services of type other than ExternalName."
Funnily enough, the kube-proxy component is actually a misnomer. I.e. it's not really a proxy anymore, although it was born as a true user space proxy. I'm not going to dive into implementation details here, there is plenty of information on the Internet including the official Kubernetes documentation and this great article of Arthur Chiao. Long story short - kube-proxy operates on the network layer using such Linux capabilities as iptables or IPVS and transparently substitutes the destination clusterIP with an IP address of some service's Pod. Thus, kube-proxy is one of the main implementers of the service discovery and load balancing in the cluster.
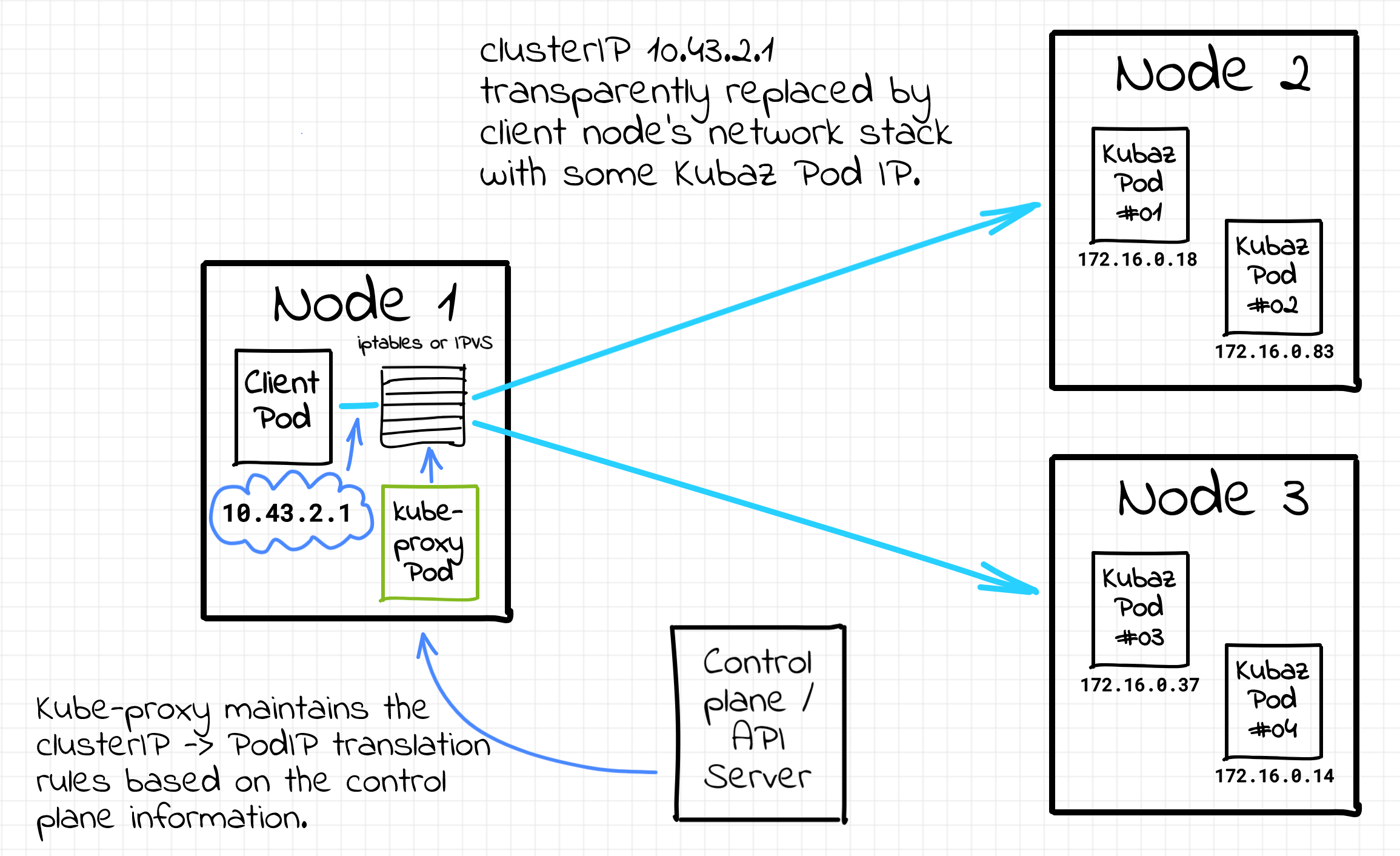
Kube-proxy implements service discovery in Kubernetes.
The kube-proxy component turns every Kubernetes node into a service proxy (just another fancy name for a client-side proxy) and all pod-to-pod traffic always goes through its local service proxy.
🤓 Going through a proxy here doesn't necessary mean packets physically passing through the proxy process on their way to the destination. There are many ways to implement a client-side proxy, and kube-proxy support several of them: userspace (older, packets do pass through the kube-proxy process), iptables (faster, kube-proxy only configures iptables rules of the host node), or ipvs (similar to iptables but using another kernel mechanism). Interesting, that kube-proxy is not even a mandatory component. While the logical model stays unchanged, cilium offers an eBPF-based kube-proxy replacement.
Now, let's see what does it mean from the service discovery standpoint. Since there are as many self-sufficient proxies as the number of nodes in the cluster, there is no single point of failure when it comes to load balancing. Unlike the canonical server-side service discovery technique with the centralized load balancer component, kube-proxy-based service discovery follows the decentralized approach with all the nodes sharing a comparable amount of traffic. Hence, the probability of getting a throughput bottleneck is also much lower. On top of that, there is no extra network hop on the packet's path because every Pod contacts its node-local copy of proxy.
Thereby, Kubernetes takes the best of both worlds. As with the server-side service discovery, clients can simply access a single endpoint, a stable Service IP address, i.e. there is no need for advanced logic on the application side. At the same time, physically the service discovery and load balancing happen on every cluster node, i.e. close to the client-side. Thus, there are no traditional downsides of the server-side service discovery.
Since the implementation of the service discovery in Kubernetes heavily relies on the Linux network stack, I'm inclined to call it a network-side service discovery. Although, the term service-side service discovery might work as well.
Conclusion
Kubernetes tries hard to make the transition from more traditional virtual or bare-metal ecosystems to containers simple. Kubernetes NAT-less networking model, Pods, and Services allow familiar designs to be reapplied without significant adjustments. But Kubernetes goes even further and provides a very reliable and elegant solution for the in-cluster service discovery and load balancing problems out of the box. On top of that, the provided solution turned out to be easy to extend and that gave birth to such an amazing piece of software as a Kubernetes-native service mesh.
Disclaimer: This article intentionally omits the questions of external service (Service type ExternalName) discovering and discovering of the Kubernetes services from the outside world (Ingress Controller). These two deserve a dedicated article each.
Further reading
- Pattern: Server-side service discovery
- Pattern: Client-side service discovery
- Pattern: Service registry
- Service Discovery in a Microservices Architecture
- Microservices: Client Side Load Balancing
- Kubernetes Podcast from Google: Linkerd, with Thomas Rampelberg
- Baker Street: Avoiding Bottlenecks with a Client-Side Load Balancer for Microservices
- Tracing the path of network traffic in Kubernetes
- Container Networking Is Simple!
- What Actually Happens When You Publish a Container Port
- How To Publish a Port of a Running Container
- Multiple Containers, Same Port, no Reverse Proxy...
- Service Proxy, Pod, Sidecar, oh my!
- Service Discovery in Kubernetes: Combining the Best of Two Worlds
- Traefik: canary deployments with weighted load balancing
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
