A Visual Guide to SSH Tunnels: Local and Remote Port Forwarding
SSH is yet another example of an ancient technology that is still in wide use today. It may very well be that learning a couple of SSH tricks is more profitable in the long run than mastering a dozen Cloud Native tools destined to become deprecated next quarter.
One of my favorite parts of this technology is SSH Tunnels. With nothing but standard tools and often using just a single command, you can achieve the following:
- Access internal VPC endpoints through a public-facing EC2 instance.
- Open a port from the localhost of a development VM in the host's browser.
- Expose any local server from a home/private network to the outside world.
And more 😍
But despite the fact that I use SSH Tunnels daily, it always takes me a while to figure out the right command. Should it be a Local or a Remote tunnel? What are the flags? Is it a local_port:remote_port or the other way around? So, I decided to finally wrap my head around it, and it resulted in a series of labs and a visual cheat sheet 🙈
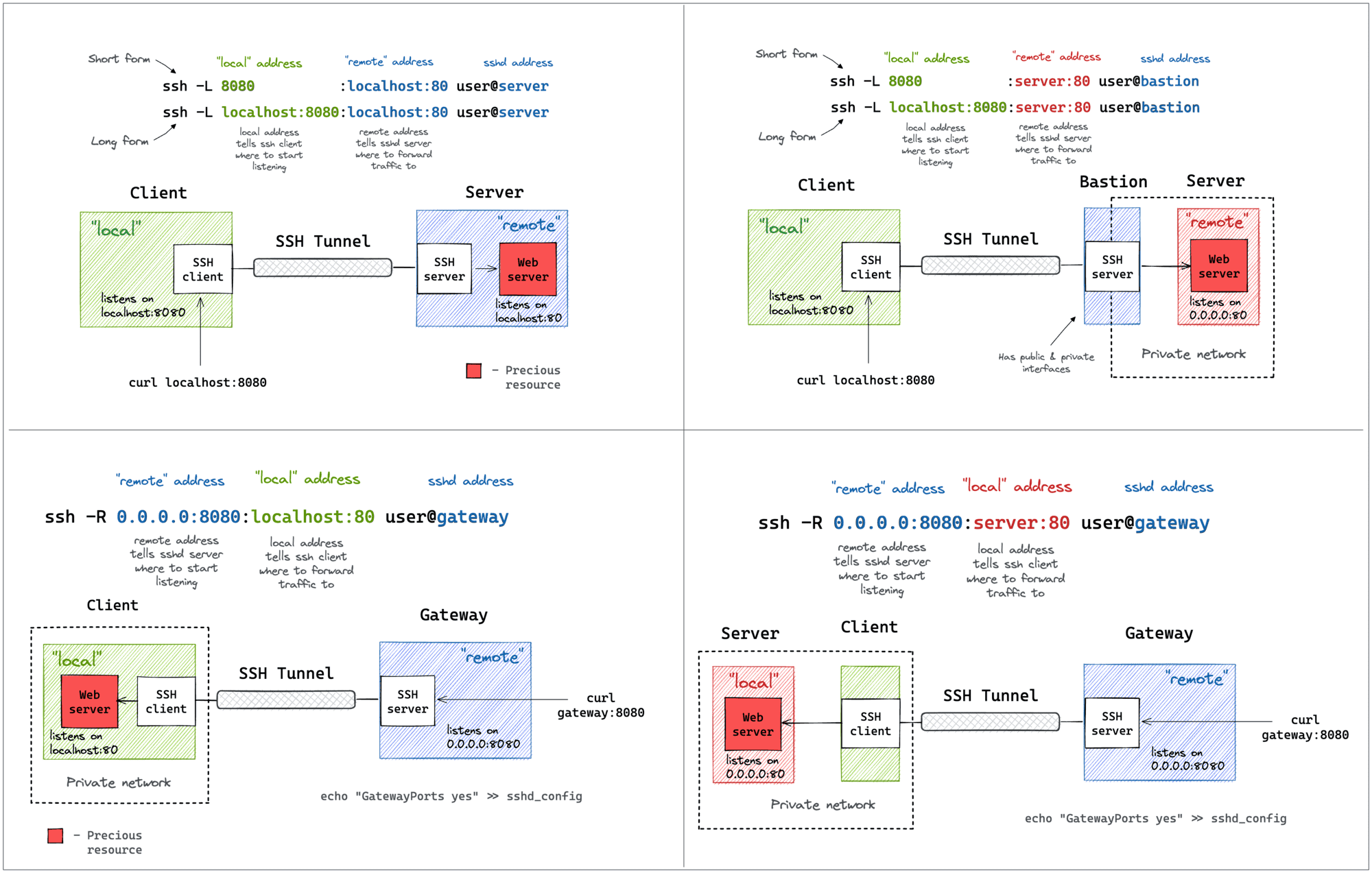

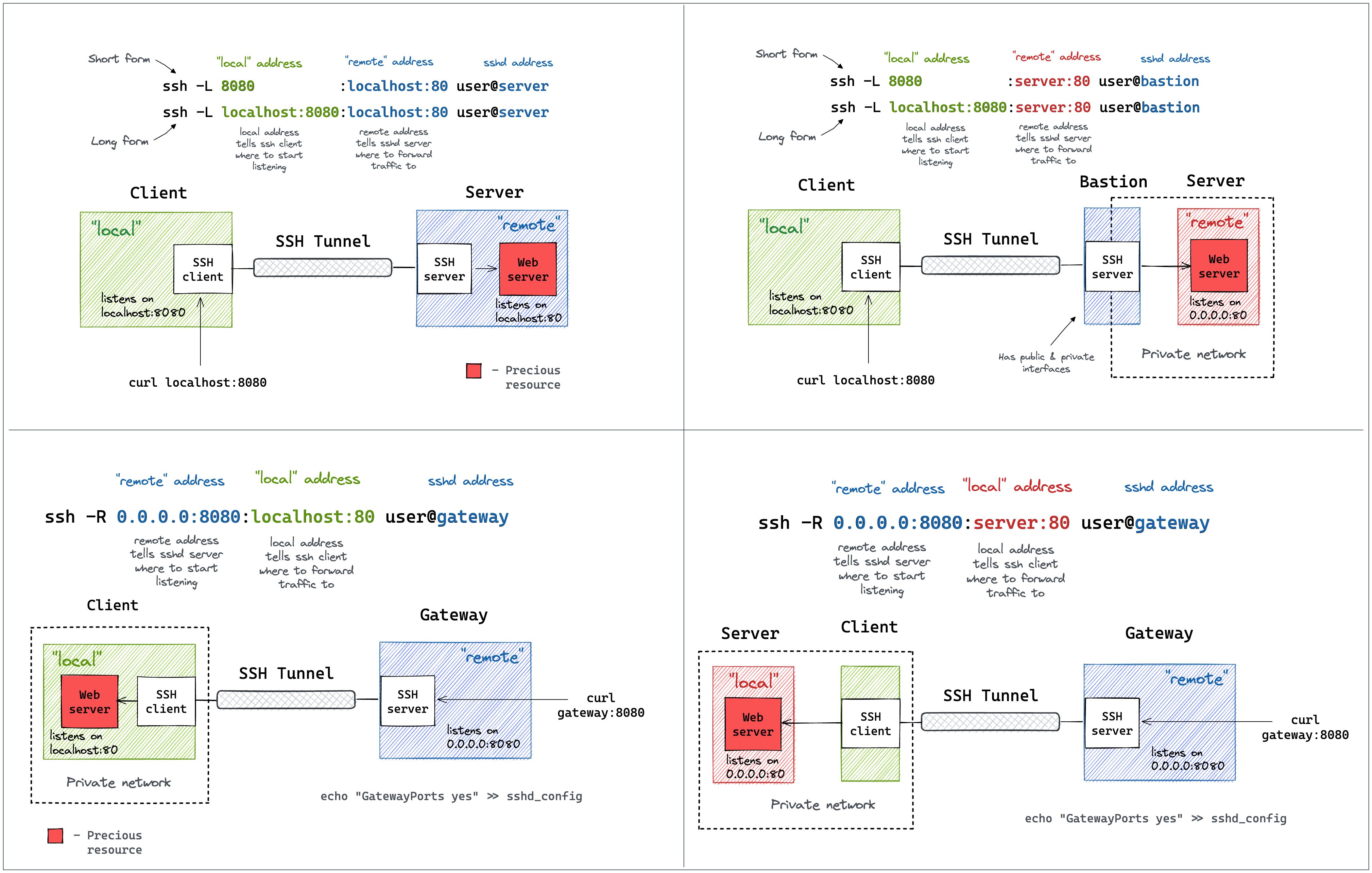{kind=link}