Making Sense Out Of Cloud Native Buzz
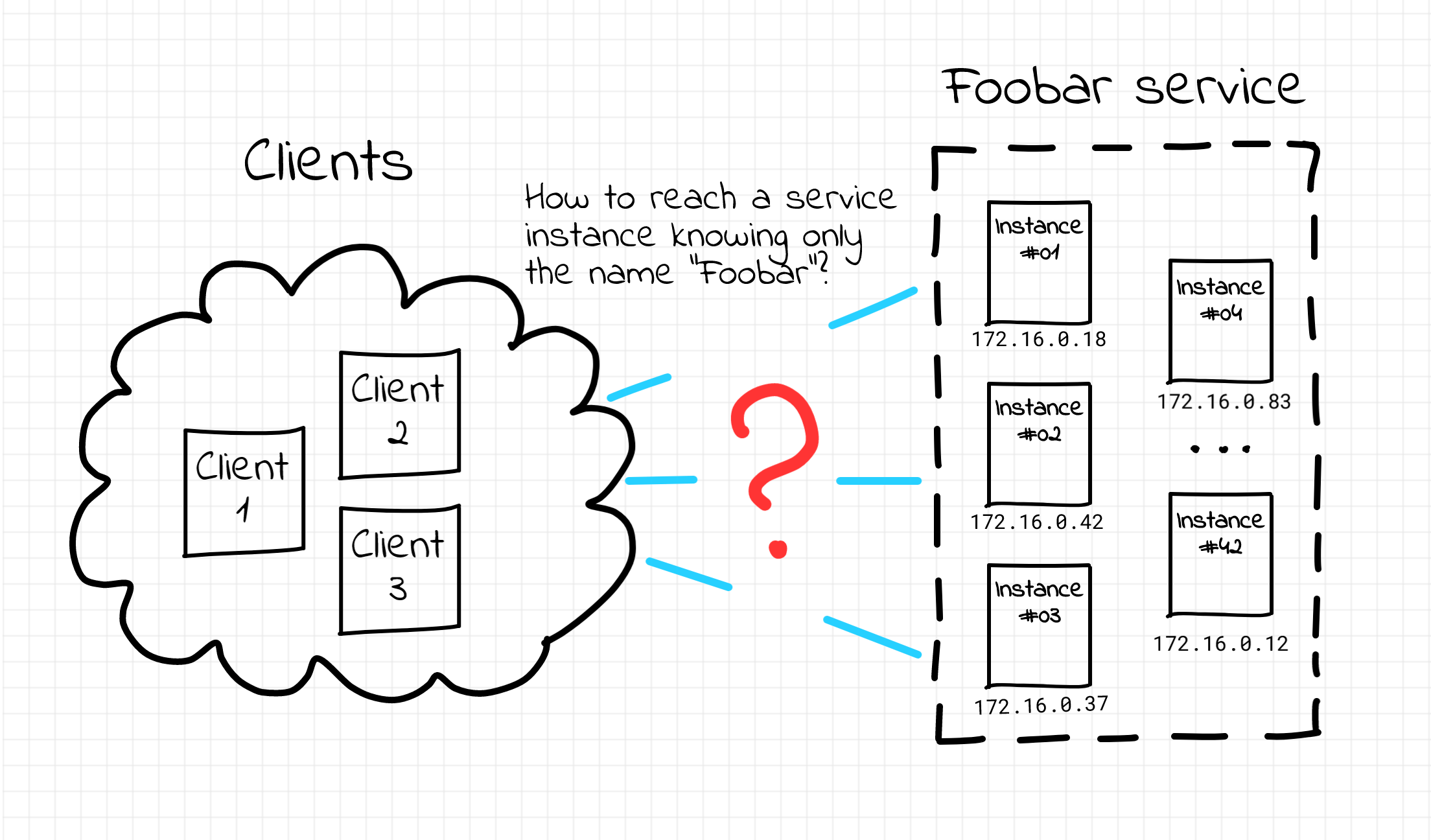
I've been trying to wrap my head around the tremendous growth of the Cloud Native zoo for quite some time. But recently I was listening to a wonderful podcast episode with the Linkerd creator Thomas Rampelberg and he kindly reminded me one thing about... microservices. Long story short, despite the common belief that microservices solve technical problems, the most appealing part of the microservice architecture apparently has something to do with solving organisational problems such as allocating teams to development areas or tackling software modernisation campaigns. And on the contrary, while helping with the org problems, microservices rather create new technical challenges!
Disclaimer: This article is not about Microservices vs Monolith.
That made me rethink the need for all those projects constituting the Cloud Native landscape. From now on I can't help but see an awful load of projects solving all kinds of technical problems originated by the transition to the microservice paradigm.