Writing Web Server in Python: sockets
What is a web server?
Let's start by answering the question: What is a web server?
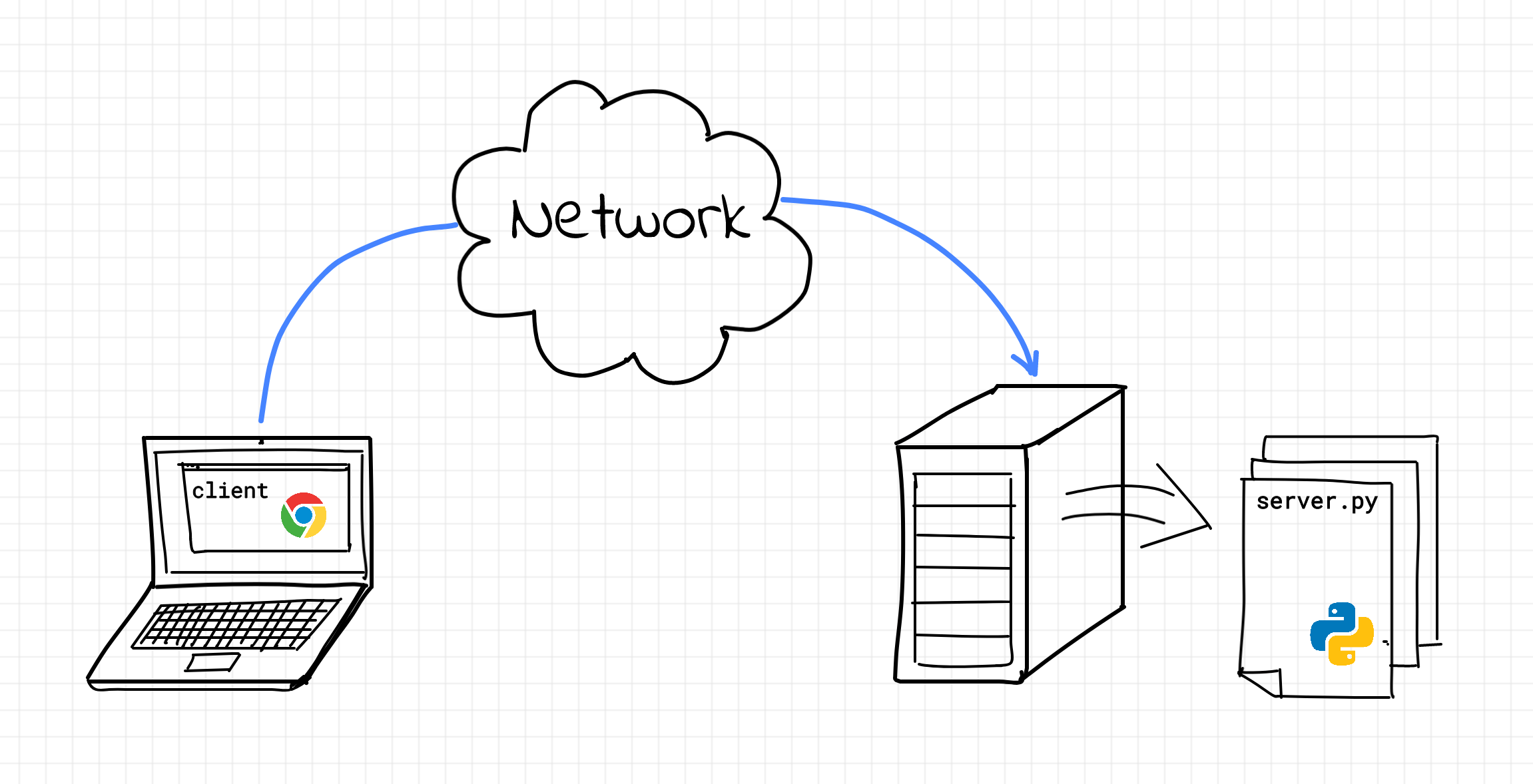
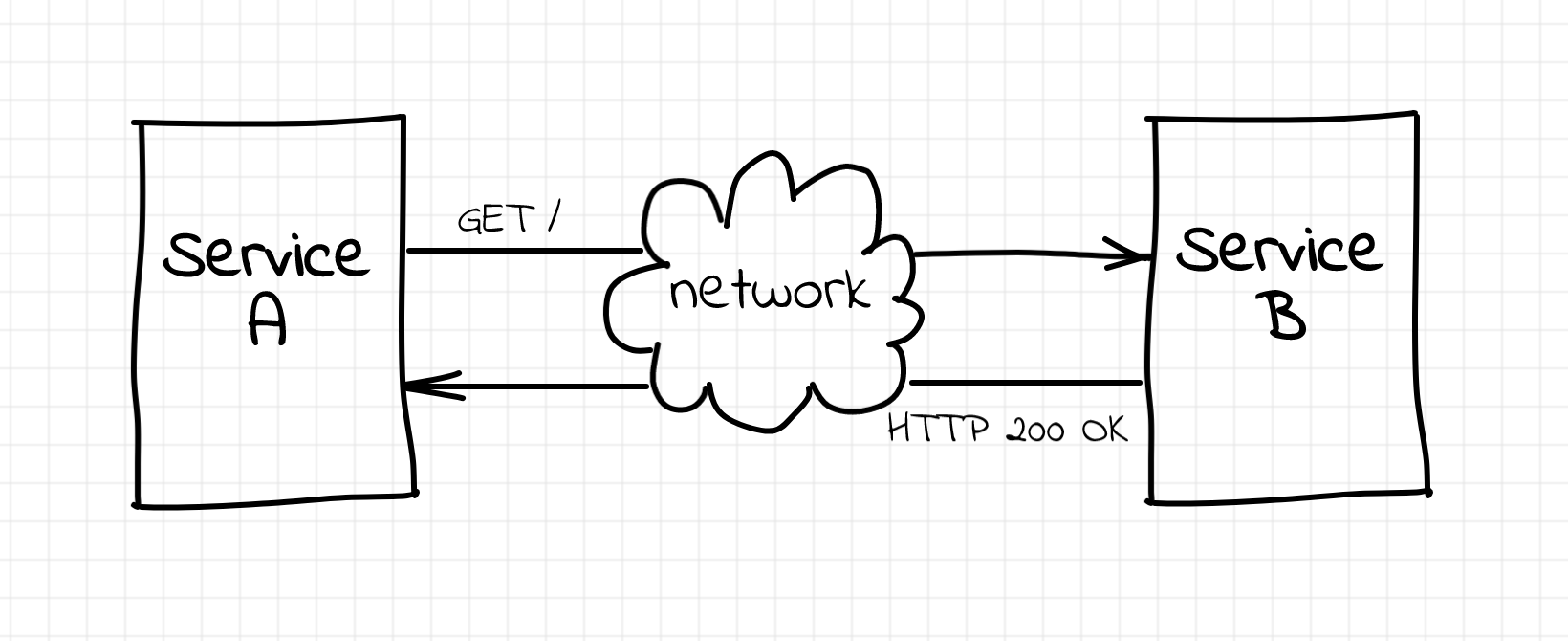
First off, it's a server (no pun intended). A server is a process [sic] serving clients. Surprisingly or not, a server has nothing to do with hardware. It's just a regular piece of software run by an operating system. Like most other programs around, a server gets some data on its input, transforms data in accordance with some business logic, and then produces some output data. In the case of a web server, the input and output happen over the network via Hypertext Transfer Protocol (HTTP). For a web server, the input consists of HTTP requests from its clients - web browsers, mobile applications, IoT devices, or even other web services. And the output consists of HTTP responses, oftentimes in form of HTML pages, but other formats are also supported.