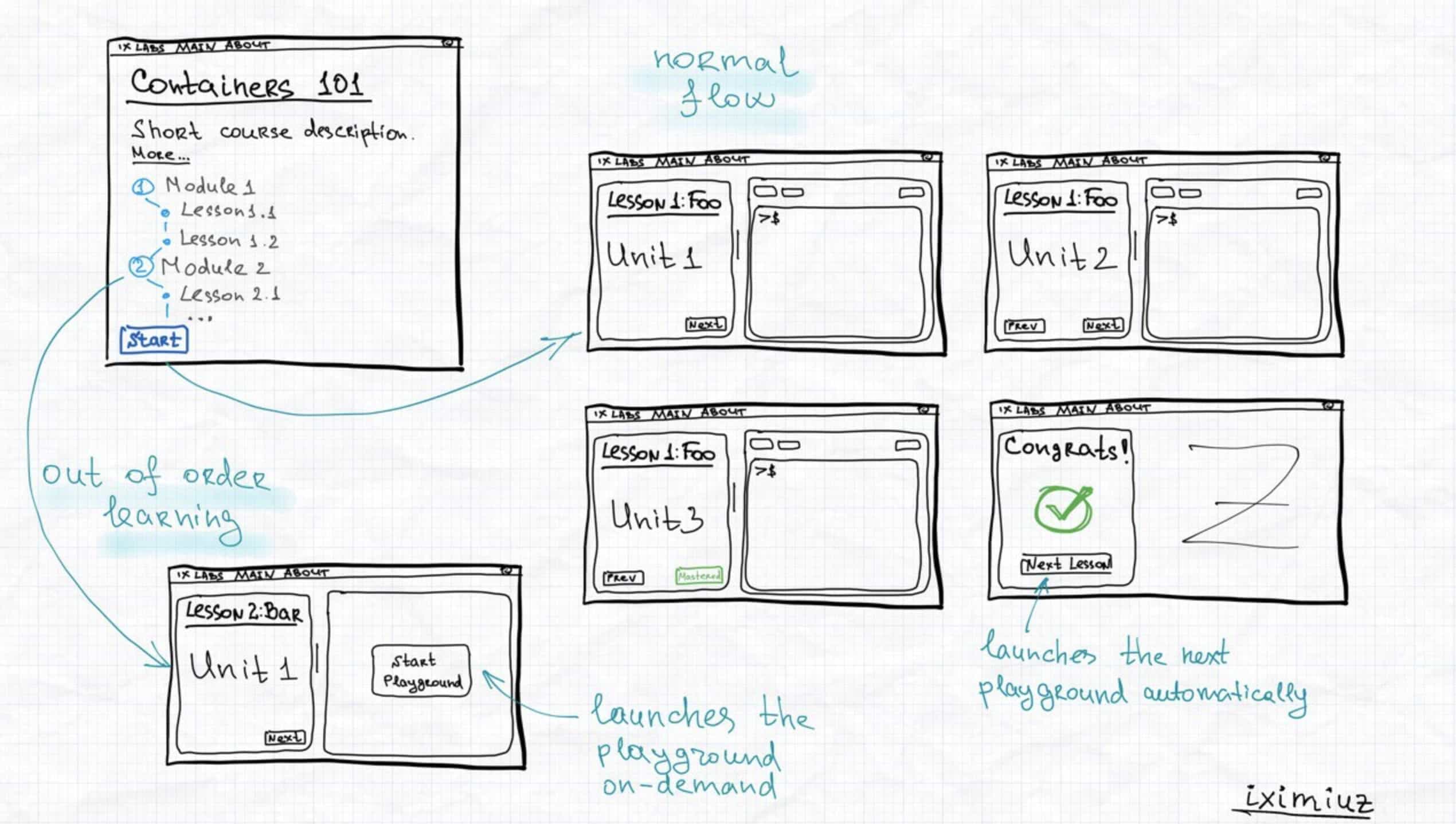
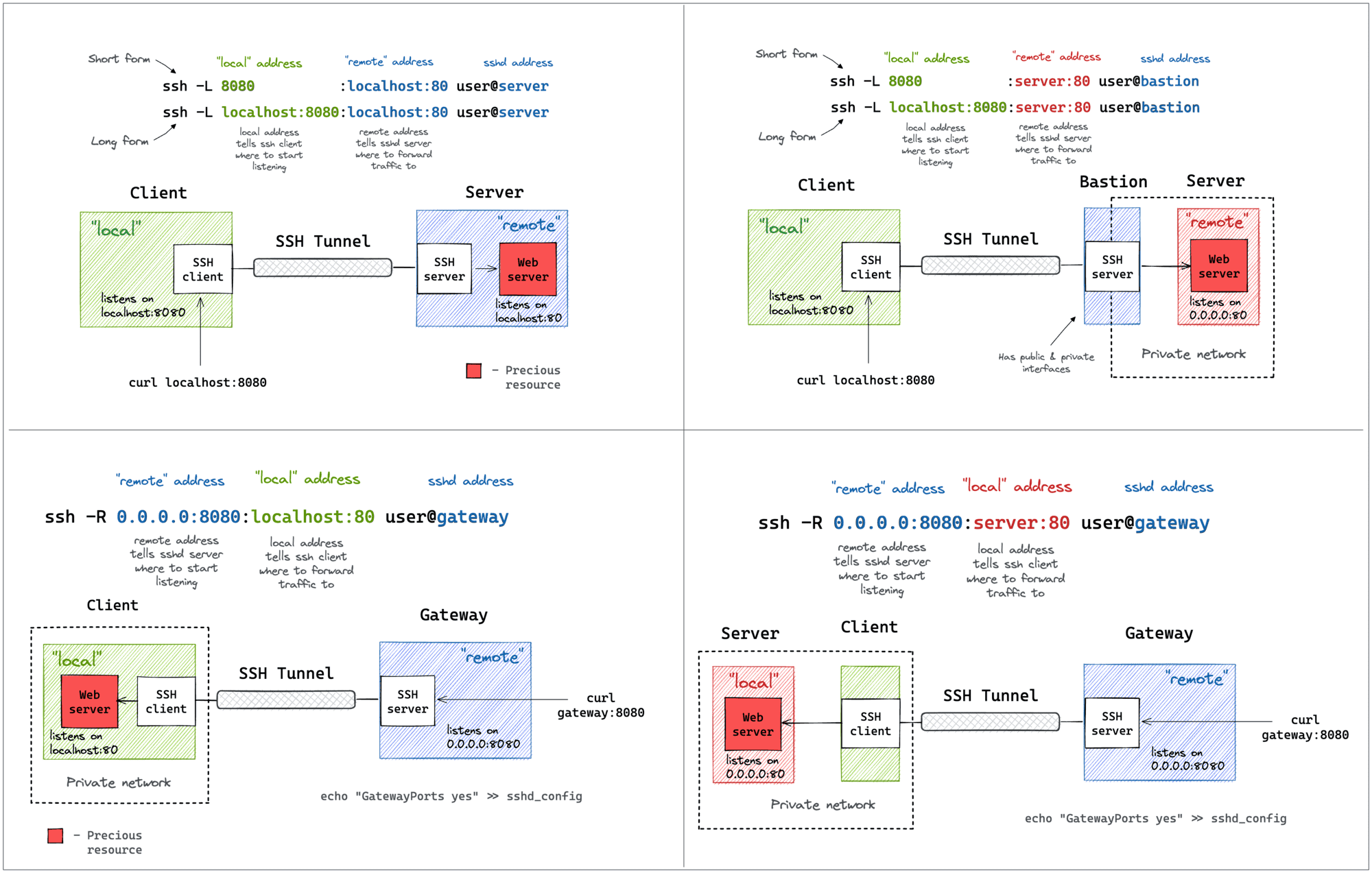
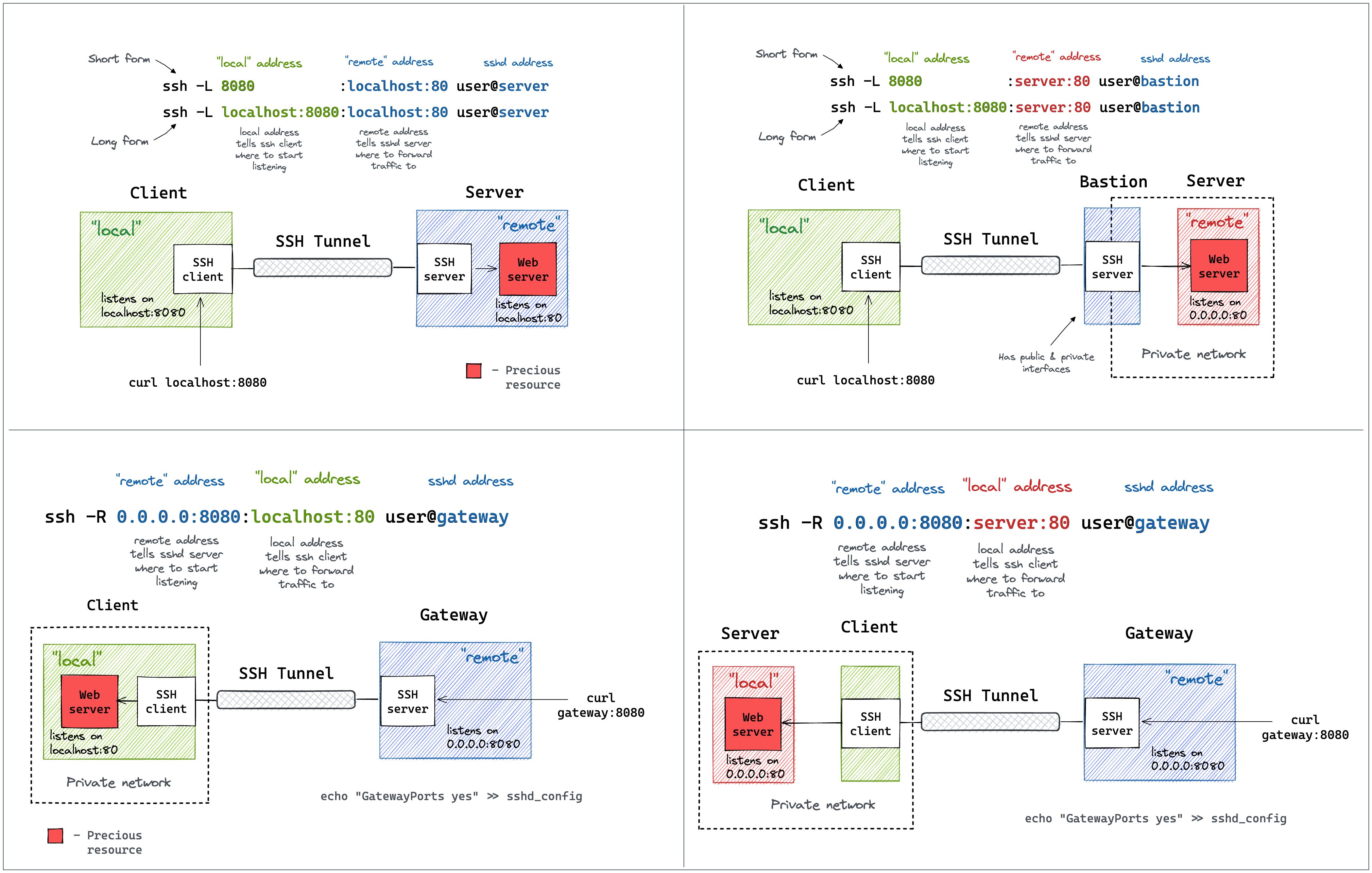
Building a Firecracker-Powered Course Platform To Learn Docker and Kubernetes
This is a long overdue post on iximiuz Labs' internal kitchen. It'll cover why I decided to build my own learning-by-doing platform for DevOps, SRE, and Platform engineers, how I designed it, what technology stack chose, and how various components of the platform were implemented. It'll also touch on some of the trade-offs that I had to make along the way and highlight the most interesting parts of the platform's architecture. In the end, I'll, of course, share my thoughts on what's next on the roadmap. Sounds interesting? Then brace for a long read!

{kind=link}