There are lots of posts trying to show how simple it is to get started with Kubernetes. But many of these posts use complicated Kubernetes jargon for that, so even those with some prior server-side knowledge might be bewildered. Let me try something different here. Instead of explaining one unfamiliar matter (how to run a web service in Kubernetes?) with another (you just need a manifest, with three sidecars and a bunch of gobbledygook), I'll try to reveal how Kubernetes is actually a natural development of the good old deployment techniques.
If you already know how to run services using virtual machines, hopefully, you'll see that there's not much of a difference in the end. And if you're totally new to operating services at scale, following through the evolution of the technology might help you as well with the understanding of contemporary approaches.
As usual, this article is not meant to be comprehensive. Rather it's an attempt to summarize my personal experience and how my understanding of the domain has been forming over the years.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
How to Deploy Services With Virtual Machines
Back in 2010, when I had just started my career as a software engineer, it was pretty common to deploy applications using virtual (or, sometimes, bare-metal) machines.
You'd take a scratch Linux VM, drop your PHP web app in there, put Nginx or Apache reverse proxy in front of it, and run a bunch of secondary daemons and cronjobs next to it.
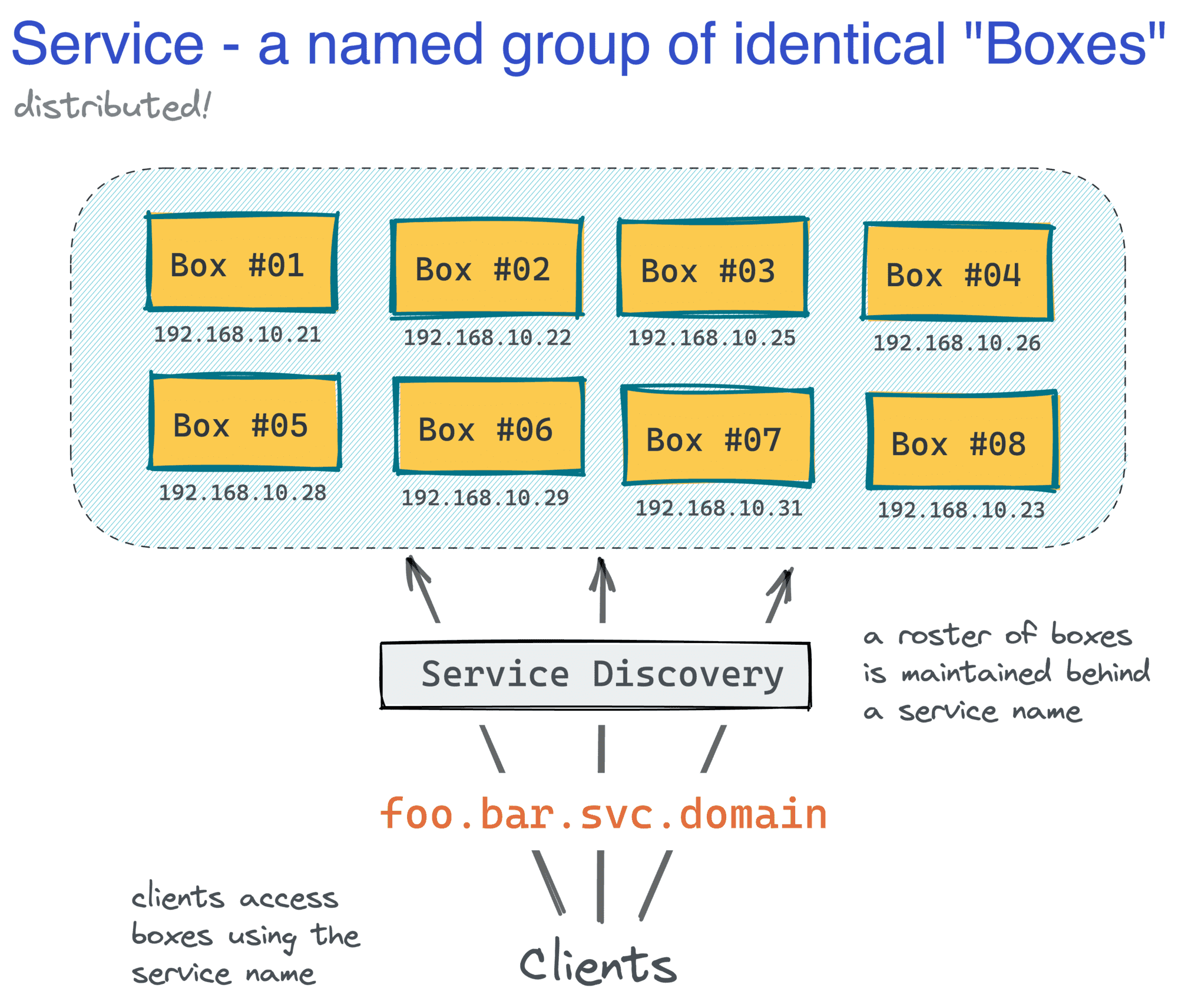
Such a machine would represent a single instance of a service, or a box for brevity, and the service itself would be just a named group of identical machines distributed over a network. Depending on the scale of your business, you could have just a few, some tens, hundreds, or even thousands of boxes spread across multiple services serving production traffic.
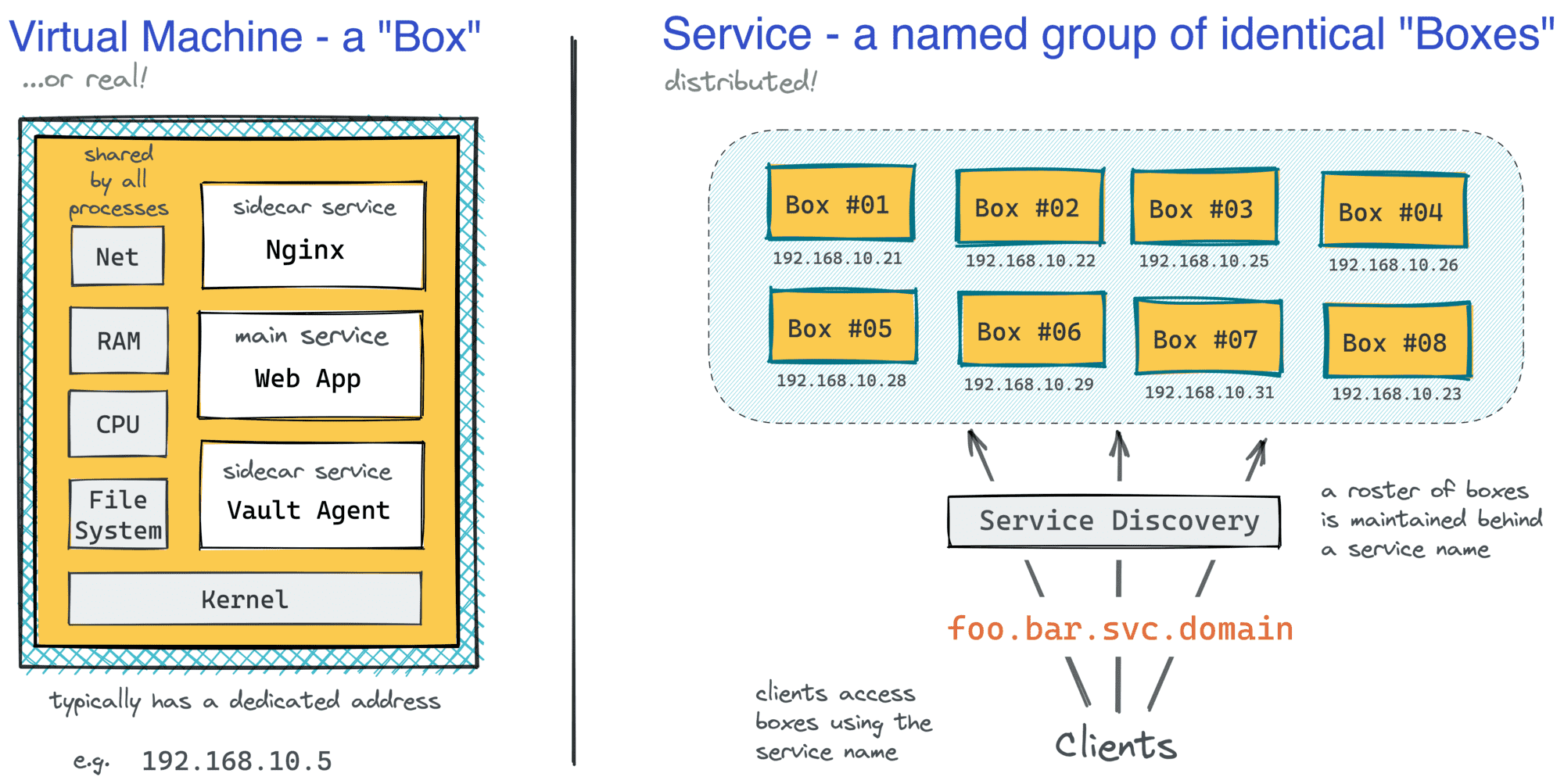
A service's abstraction hides the app's complexity behind a single entrypoint.
Challenges of Deploying Services With Virtual Machines
Often, the size of the machine fleet would define the ways provisioning (installing an OS and packages), scaling (spawning identical boxes), service discovery (hiding a pool of boxes behind a single name), and deployment (shipping new versions of code to boxes) were done.
If you were a small and brave company with just a few pet-like boxes, you might find yourself provisioning new boxes seldomly and semi-manually. This would typically mean a low bus factor (due to the lack of automation), a poor security posture (due to the lack of periodic patches), and potentially long(er) disaster recovery. On the bright side, the administration costs would be quite low because scaling wouldn't be needed, your deployments would be simple (it's just a few boxes to deliver the code to), and the service discovery would rather be trivial (due to quite static pools of addresses).
For a company with a large herd of boxes, the reality would be somewhat different. A high number of machines would typically lead to a more frequent need to provision new boxes (more boxes simply means more breakage). You'd invest in automation (the ROI would be quite high) and end up with many cattle-like boxes. As a by-product of boxes being constantly recreated, you'd increase the bus factor (a script cannot be hit by a bus) and improve the security posture (updates and patches would be applied automatically). On the darker side, inefficient scaling (due to uneven daily/yearly traffic distribution), overly complicated deployments (delivering code to many boxes quickly is hard), and fragile service discovery (have you tried running consul or zookeeper at scale?) would lead to higher operational costs.
The early cloud offerings like Amazon Elastic Compute Cloud (EC2) allowed spinning up (and down) machines faster; machine images made with packer and customized with cloud-init made the provisioning slightly easier; automation tools like puppet and ansible enabled applying infrastructure changes and delivering new versions of software at scale. However, there was still plenty of room for improvement.
What Problems Docker Containers Solve
Back in the day, it was pretty common to have different production and development environments. That would lead to situations when an app might work locally on your stuffed Debian machine but fail to start on vanilla CentOS in production due to a missing dependency. Conversely, you may have quite some trouble installing the app's dependencies locally, but running a pre-provisioned virtual machine per service for development would be infeasible due to high resource requirements.
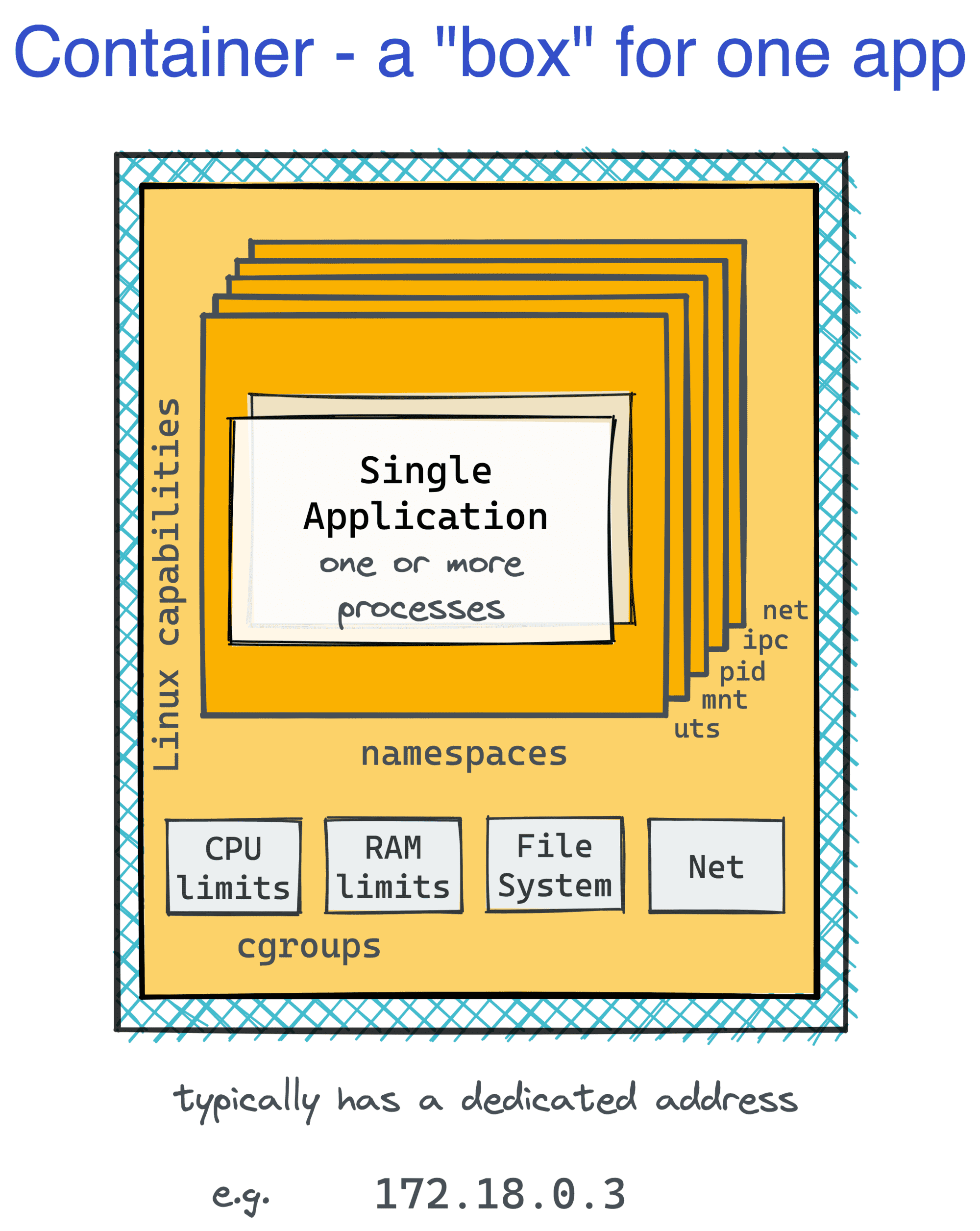
The massiveness of virtual machines was a problem even in production. Having a virtual machine per service might lead to lower than optimal resource utilization and/or sizable storage and compute overhead, but putting multiple services into one box could make them conflict. The multi-minute startup time could also use some improvement.
The world obviously needed a more lightweight version of the box.
And that's where The Containers came in. Much like VMs that allowed slicing a bare-metal server into several smaller (and cheaper) machines, containers split a single Linux box into tens or even hundreds of isolated environments.
From within a container, it may feel like you've got a virtual machine of your own, with your favorite Linux distro. Well, at least at first sight. And from the outside, containers were just regular processes running on the host operating system and sharing its kernel.
👉 Further reading: Not Every Container Has an Operating System Inside.
The ability to pack an application with all its dependencies, including a certain version of the OS userland and libraries, ship it as a container image, and run in a standardized execution environment wherever Docker (or alike) is installed greatly improved the reproducibility of workloads.
Due to the lightweight implementation of the container boundaries, the computational overhead got significantly reduced, allowing a single production server to run tens of different containers potentially belonging to several (micro)services. At the expense of the reduced security, of course.
The image storage and distribution also became more efficient, thanks to the immutable and shared image layers.
👉 Further reading: You Don't Need an Image To Run a Container.
To an extent, containers also changed the way provisioning was done. With (carelessly written) Dockerfiles and (magical) tools like ko and Jib, the responsibility greatly shifted toward developers, simplifying the requirements for production VMs - from the developer standpoint, you'd just need a Docker- (or later OCI-) compatible runtime to run your app, so you wouldn't annoy your sysadmin friends with asks to install a certain version of Linux or system packages anymore.
On top of that, containers accelerated the development of alternative ways to run services. There is 17 ways to run containers on AWS now, with the better part of them being fully serverless, and in simple enough cases, you could just go with Lambda or Fargate and benefit from cattle-like boxes! 🎉
What Problems Containers Don't Solve
Containers turned out to be quite a handy dev tool. It was also simpler and faster to build a container image than to build a VM. Combined with the old organizational problem of how to separate responsibilities between teams efficiently, it led to a significant increase in the average number of services a typical enterprise would have and a similar increase in the number of boxes per service.
And for those of us who didn't jump on the Fargate/Lambda train, it complicated scaling, service discovery, and deployments even further...
The form of containers popularized by Docker was actually pretty deceptive. At first sight, it may look like you got a cheap dedicated VM per instance of your service. However, if such an instance required sidecars (like a local reverse proxy running in front of your web app to terminate TLS connections or a daemon loading secrets and/or warming up caches), you'd instantly feel the pain difference of containers from the virtual machines.
Docker containers have been deliberately designed to contain just one application. One container - one Nginx; one container - one Python web server; one container - one daemon. The lifecycle of a container would be bound to the lifecycle of that application. And running an init process like systemd as a top-level entrypoint was specifically discouraged.
So, to recreate a VM-box from the diagram at the beginning of this article, you'd need to have three coordinated container-boxes with a shared network stack (well, at least the localhost needs to be the same). And to run two instances of the service, you'd need six containers in two groups by three!
From the scaling standpoint, it means we would need to scale up (and down) some containers together. Deployment also would need to happen synchronously. The new version of the web app container simply may start using a new port number and become incompatible with the old version of the reverse proxy container.
We clearly missed an abstraction here that would be as lightweight as containers but as expressive as the original VM boxes.
Additionally, containers per se also didn't provide any means to group boxes into services. But they contributed to the increase in the headcount of boxes! Docker raced to solve these problems with its Swarm product, but another system won...
Kubernetes Solved It All... Or Not?
Instead of inventing new ways to run containers, Kubernetes designers apparently decided to recreate the good old VM-based service architecture but using containers as building blocks for that. Well, at least this is my take on it.
YMMV, of course, but to me, as someone with prior VM experience, many initial Kubernetes ideas would start looking familiar as soon as I'd get through the new terminology and figure out the analogous concepts.
Kubernetes Pods Are The New Virtual Machines
Let's start with the Pod abstraction. A Pod is the smallest thing you could run in Kubernetes. The simplest Pod definition would look as follows:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.1
ports:
- containerPort: 80
At first sight, the above manifest just says what image to run (and how to name it). But notice how the containers attribute is a list! Now, getting back to that nginx + web app example, in Kubernetes, instead of running an extra Pod for the web app container, you can simply put the reverse proxy and the app itself in one box:
apiVersion: v1
kind: Pod
metadata:
name: foo-instance-1
spec:
containers:
- name: nginx # <-- sidecar container
image: nginx:1.20.1
ports:
- containerPort: 80
- name: app # <-- main container
image: app:0.3.2
Pods, however, aren't just groups of containers. The isolation borders between containers in a Pod are weakened. Much like regular processes running on a VM, containers in a Pod can communicate freely over localhost or using traditional IPC means. At the same time, each container still has an isolated root filesystem keeping the benefits of packaging apps with their dependencies. To me, it looks like an attempt to take the best parts of the VM- and container- worlds at the same time:
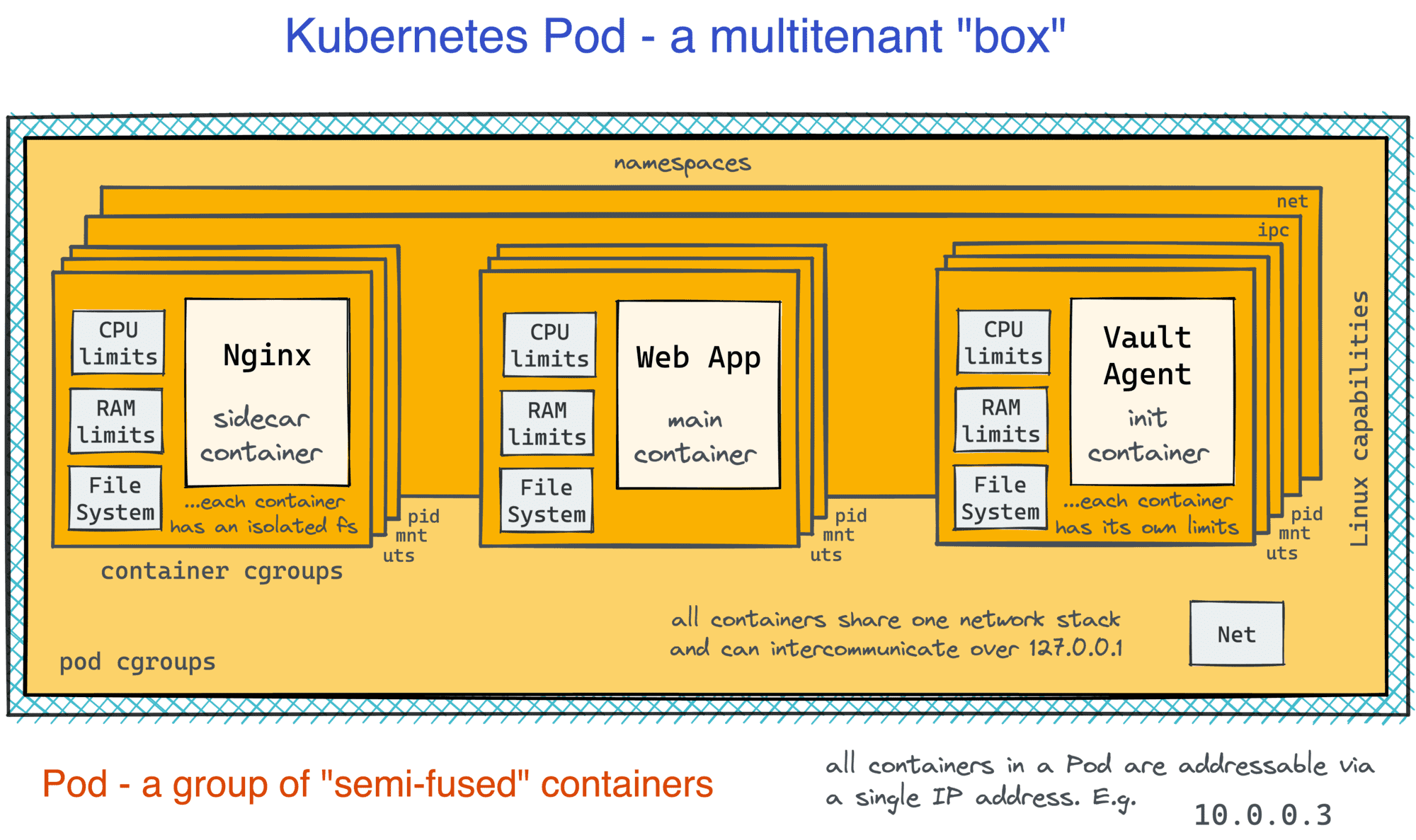
👉 Further reading: Containers vs. Pods - Taking a Deeper Look.
Scaling and Deploying Pods Is Simple
Now, when we got the new box, how can we run multiple of them to make up a service? In other words, how to do scaling and deployment in Kubernetes?
Turns out, it's pretty simple, at least in the basic scenarios. Kubernetes introduces a handy abstraction called Deployment. A minimal Deployment definition consists of a name and a Pod template, but it's also very common to specify the desired number of Pod copies:
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment-1
labels:
app: foo
spec:
replicas: 10
selector:
matchLabels:
app: foo
template:
metadata:
labels:
app: foo
spec:
<...Pod definition comes here>
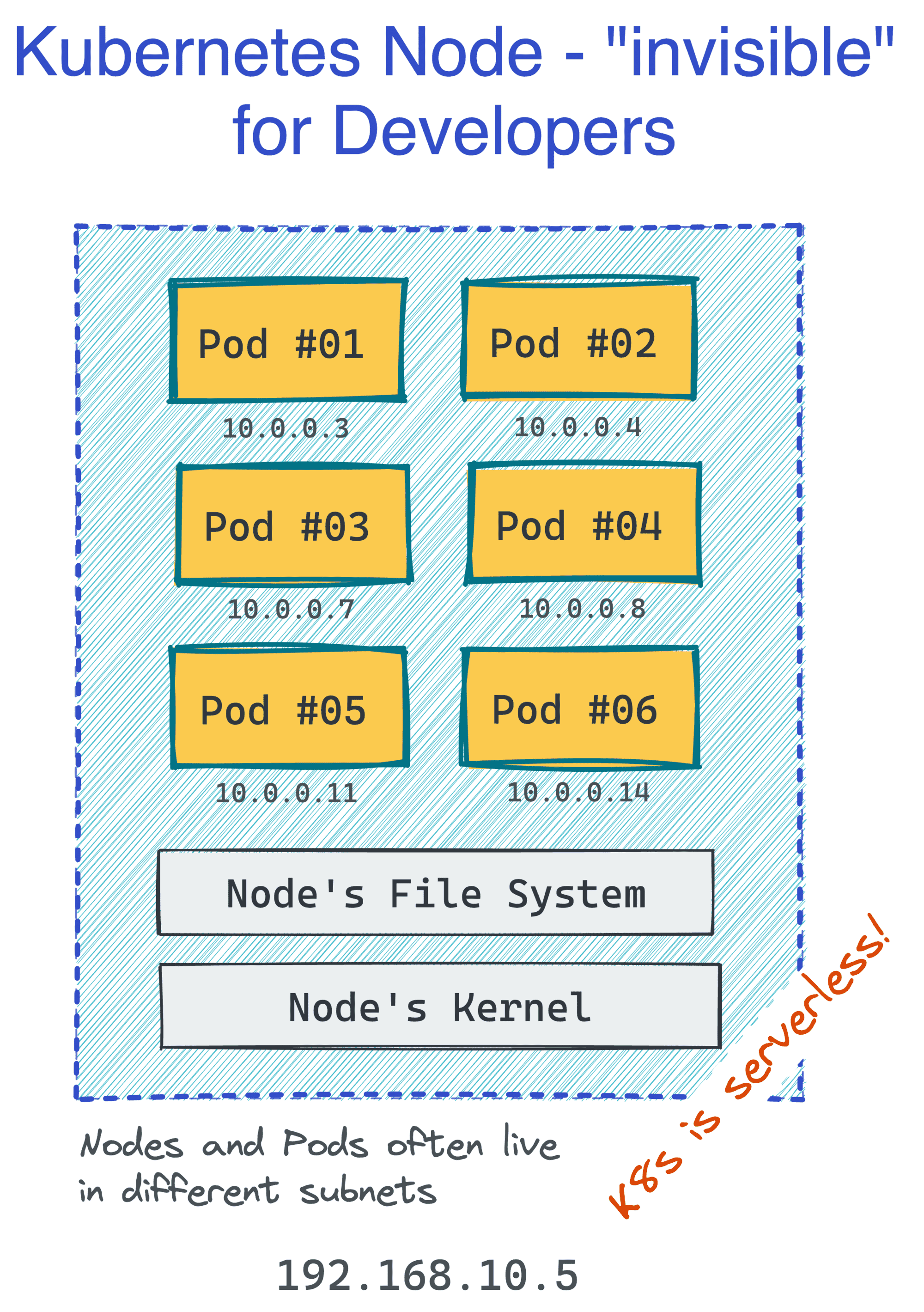
The great part about Kubernetes is that as a developer, you don't care about servers (or, Nodes in Kubernetes' terminology). You think and operate in terms of groups of Pods, and they get distributed (and redistributed) across the cluster Nodes automatically:
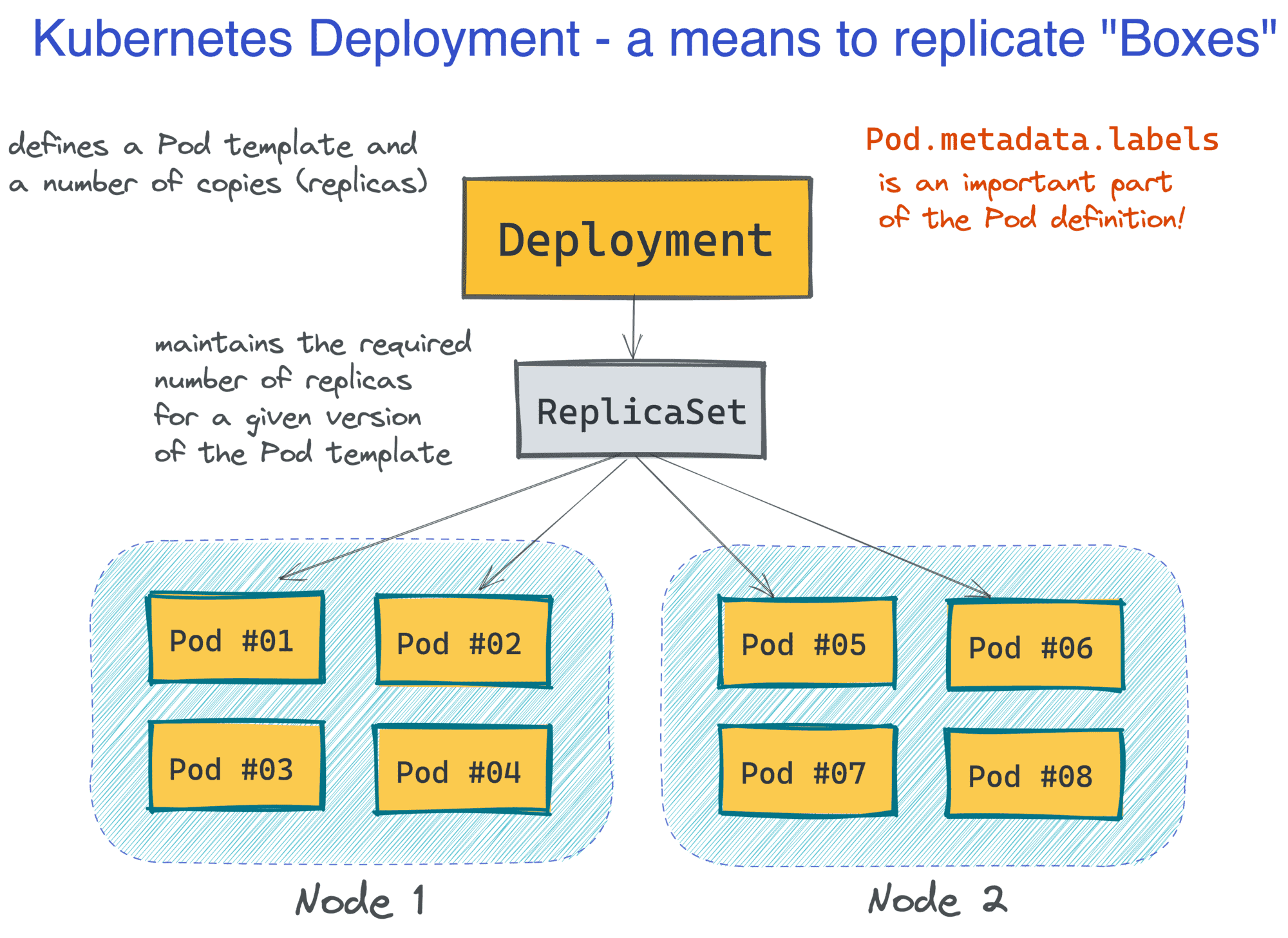
This makes Kubernetes rather a serverless piece of technology. But at the same time, Pods look and behave much like the familiar VMs from the past (except that you don't need to manage them), so you can design and reason about your applications in familiar abstractions:
Built-In Service Discovery Rocks
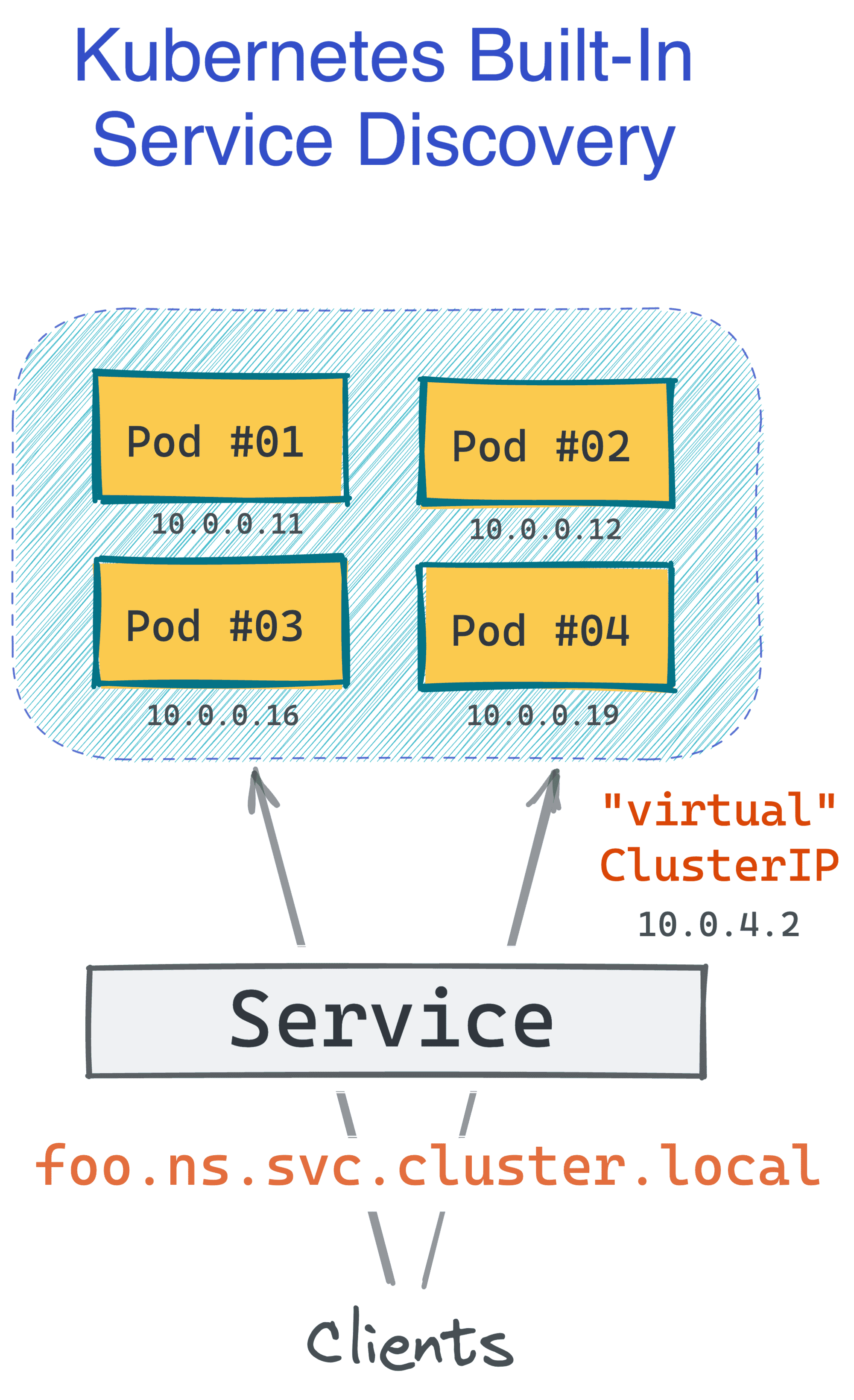
Kubernetes designers definitely knew that it's not enough to just spin up N copies of a box and call it a service. Clients should be able to access the service using a single (potentially logical) name, and the service discovery system should be able to translate this name into a certain IP address (be it a load balancer fencing the boxes or a certain instance of the service).
In the past, you'd need a separate (and quite demanding) solution for that. However, Kubernetes has this functionality built in, and the default implementation is decent! It can also be extended with a service mesh like Linkerd or Istio, making it even more powerful.
👉 Further reading: Service Discovery in Kubernetes.
The only thing you need to turn a group of Pods into a service is to create a Service object (no pun intended).
Here is what a simple Kubernetes Service definition could look like:
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
selector:
app: foo
ports:
- protocol: TCP
port: 80
The above manifest allows accessing any Pods labeled as app=foo (and running in the default namespace) using a DNS name like foo.default.svc.cluster.local. And it's all without any extra piece of software installed in the cluster!
Notice how the Service definition doesn't mention Deployments anywhere. Much like Deployment itself, it operates in terms of Pods and labels, and this makes it quite powerful! For instance, good old blue/green or canary deployments in Kubernetes could be achieved by having two Deployment objects running a different version of the app image behind a single Service selecting Pods with a common label:
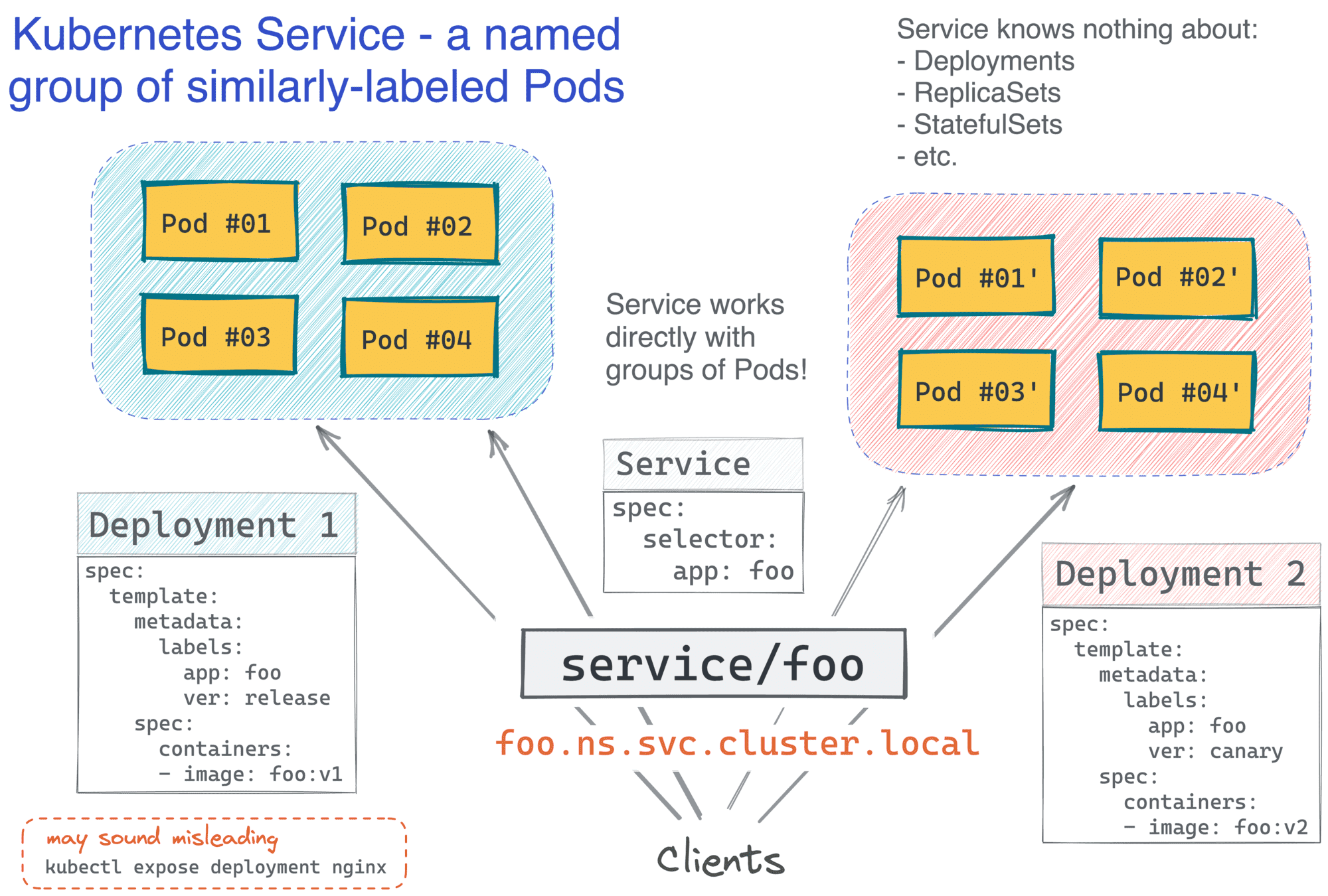
And now, the funniest part - have you noticed how Kubernetes services are indistinguishable from our old VM-based services? I'm pretty sure it was done intentionally to leverage the existing institutional knowledge, with the whole industry being the institution in this case:
Kubernetes as a Service
So, is Kubernetes just like VMs, but simpler? Well, yes and no. Paraphrasing Kelsey Hightower, we should differentiate between the complexity of driving a car and the complexity of repairing it. Many of us can drive cars, but very few are good at fixing engines. Luckily, there are dedicated shops for that! The same is applicable to Kubernetes.
Running a service using a managed Kubernetes offering like EKS or GKE is indeed similar but much simpler than using VMs. But if you have to maintain the actual servers behind Kubernetes clusters, it becomes a totally different story...
Or maybe you don't need Kubernetes yet?
Summarizing
Trying to improve the experience of running services on VMs, containers changed the way we package our software, drastically reduced requirements for server provisioning, and enabled alternative ways to deploy our workloads. But on their own, containers didn't become a solution for running services at scale. An extra layer of orchestration would still be required on top.
Kubernetes, as one of the container-native orchestration systems, recreated the familiar architectural patterns of the past using containers as basic building blocks. Kubernetes also smoothed some of the traditionally rough edges by providing built-in means for scaling, deployment, and service discovery. If you use Kubernetes today, you essentially rely on the same abstractions (instances and services) you'd rely back in the days when VMs were mainstream.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox:
