- conman - [the] Container Manager: Inception
- Implementing Container Runtime Shim: runc
- Implementing Container Runtime Shim: First Code
- Implementing Container Runtime Shim: Interactive Containers
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
Scope of article
Well, at this moment we already know what we need to deal with. In order to use runc from code we need to implement our shim as a daemon and this daemon has to be as long-lived as the underlying container process. In this article, we will try to develop a minimum viable runtime shim and integrate it with our experimental container manager.
The minimal shim implementation takes as its input a path to the container bundle (with the config.json) as well as the list of the predefined locations (for the container log file, container pidfile, container exit status file, etc). The shim needs to create a container by executing runc with the provided parameters and then serve the container process until its termination. The planned functionality of this shim version includes:
- Detaching the shim from the container manager process.
- Launching runc and handling container creation errors.
- Reporting the status of the container creation back to the manager.
- Streaming container's stdout and stderr to the log file.
- Tracking and reporting the exit code of the container.
Surprisingly or not, from the container manager standpoint, there will be almost no observable difference after the integration with the basic shim. Since conman is targeting CRI-compatibility, handling of the logs lies out of its scope. But still, two noticeable improvements will be introduced: the container manager will gain an ability to report container creation errors synchronously (i.e. during conmanctl container create execution) and the exit code of a container will appear in the container status report (conmanctl container status).
Let's the coding begin!
Shim design
As I already mentioned, the shim needs to be a daemon. This implies a very short-lived foreground process performing the fork of the daemon process itself and exiting. The forked process, let's call it a shim daemon process, or just a shim process has to detach its stdio streams from the parent and start a new session:
int main() {
if (int pid = fork()) {
// write pid to file
exit(0)
}
// redirect stdio streams to /dev/null
// create a new session
// ... run the actual shim payload ...
}
In this case, the consequent startup of the shim will be happening asynchronously with regard to its parent (i.e. the container manager process). However, it's nice to have startup errors still reported synchronously to the container manager. We will see later how this problem can be easily addressed by supplying to the shim an extra file descriptor for a write-only pipe.
The foremost task of the shim daemon process is to create a new container by executing runc create with the given bundle. The only way to execute a new command without replacing the current process image is to use the fork-exec technique. Thus, the shim process needs to fork another process, the predecessor of the container process. Let's call this process runtime process. The main responsibility of this process is exec-ing runc create with the provided bundle. However, as we know from the previous article, runc duplicates its stdio streams over the parent process' file descriptors 0, 1, and 2 (i.e. over the parent's stdio). Even more, later on, in case of the successful container creation and a consequent start, the same file descriptors will become container's stdio streams.
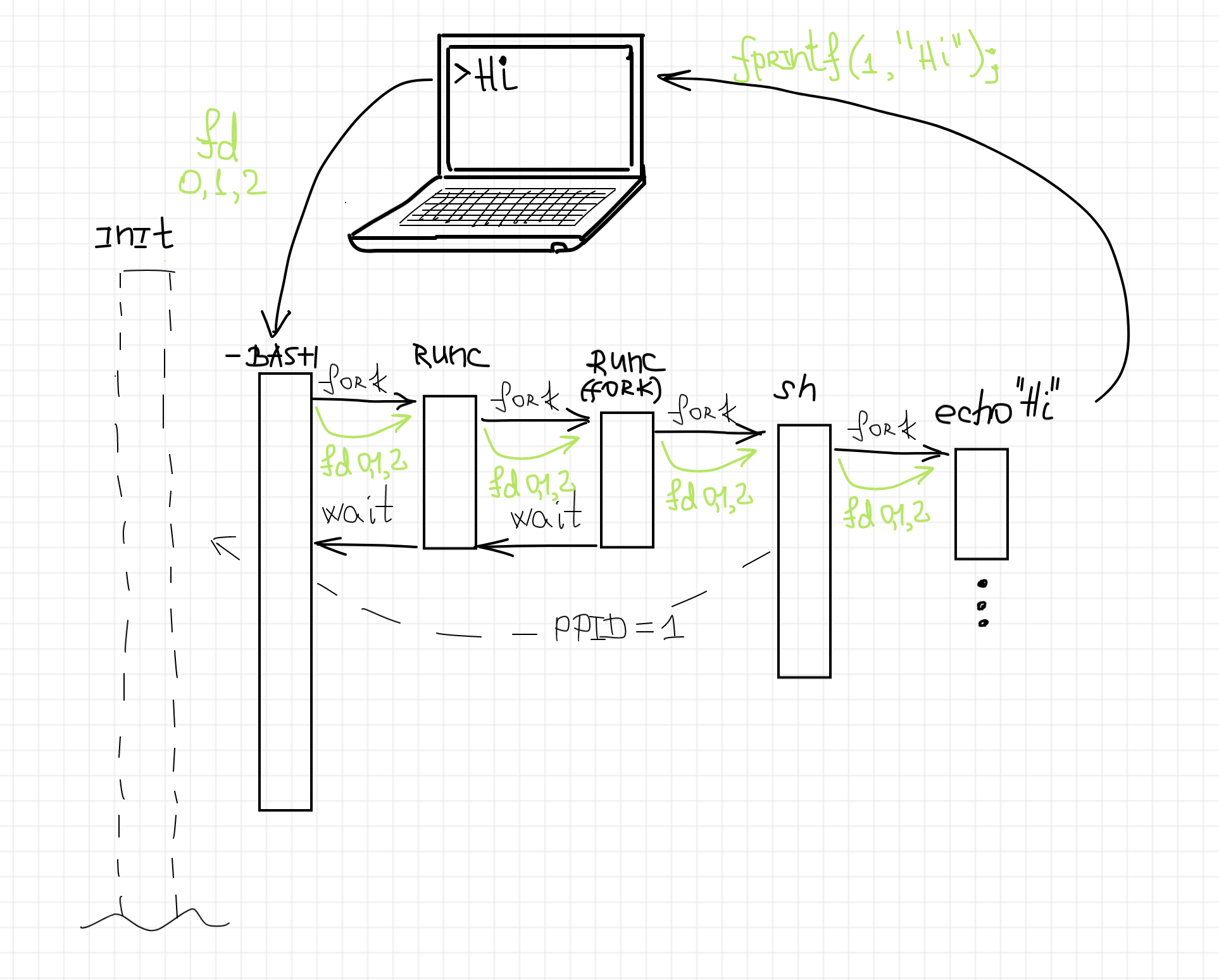
And since the stdio of the runc and container processes is the primary concern of the shim, we have to prepare a bunch of Linux pipes before forking the predecessor runtime process. In this case, it will be able to duplicate the pipes over its stdio streams wiring the shim process with the future runc and container's output.
int main() {
if (int shim_pid = fork()) {
// write shim_pid to file
exit(0)
}
// redirect shim stdio to /dev/null
dup2("/dev/null", STDIN_FILENO)
dup2("/dev/null", STDOUT_FILENO)
dup2("/dev/null", STDERR_FILENO)
// create a new session
setsid()
// prepare pipe_out and pipe_err
pipe_out = pipe()
pipe_err = pipe()
int runtime_pid = fork()
if (runtime_pid == 0) {
// redirect runc stdion to pipes
dup2("/dev/null", STDIN_FILENO)
dup2(pipe_out, STDOUT_FILENO)
dup2(pipe_err, STDERR_FILENO)
exec("runc create --bundle <...>")
}
// wait for the runtime process termination:
waitpid(runtime_pid)
// ... start serving container process ...
}
A few more things left uncovered...
First, I hope you remember, that runc create is a so-called detached mode of runc. I.e. execution of the runc start command will lead to the container process forked from the runc process and then reparented to the closest subreaper (or Linux init process) due to runc process termination.
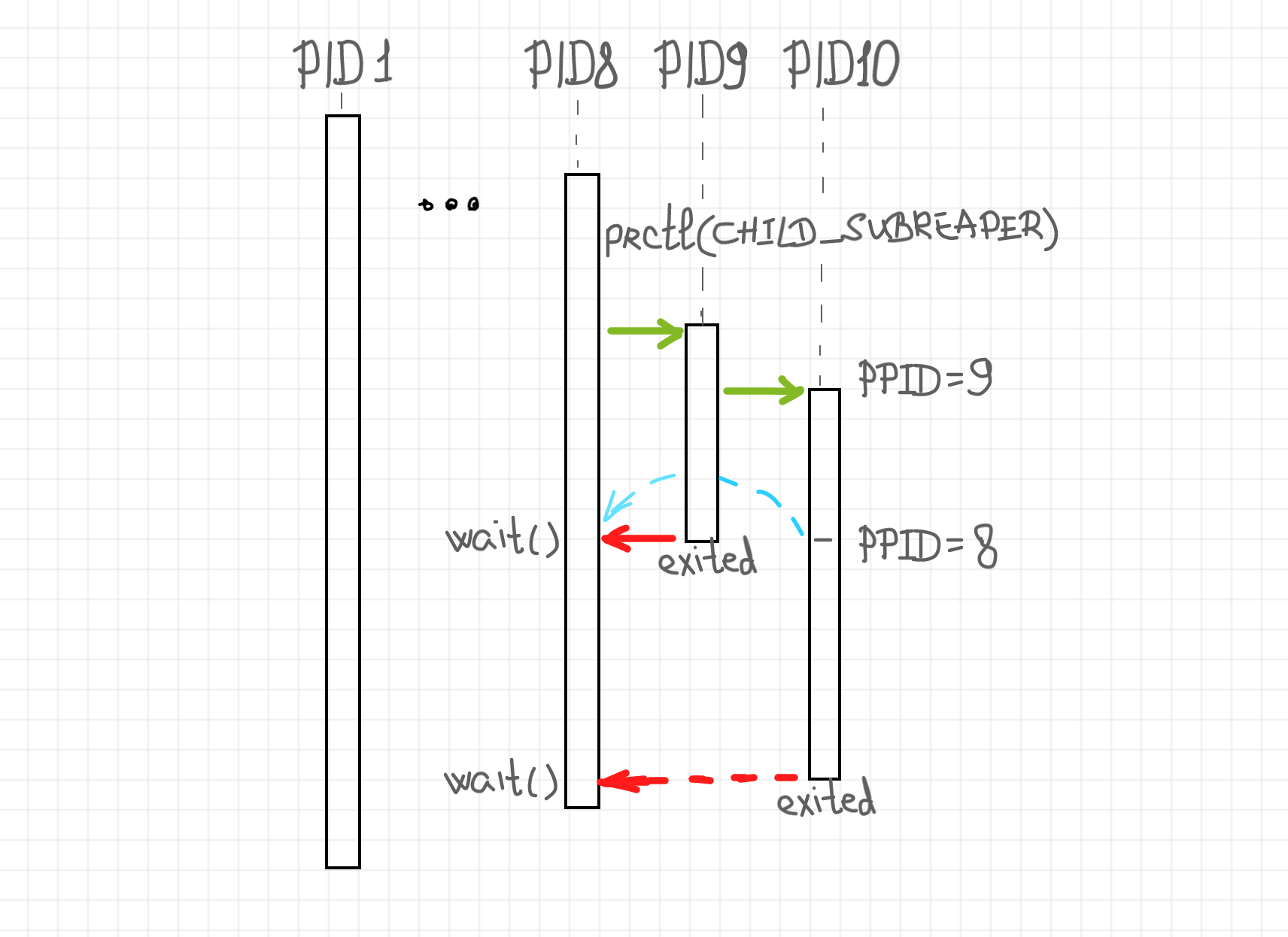
Thus, we need to declare the shim process a subreaper. Actually, this should be done even before the fork of the runtime process. Having the shim process a subreaper is a manifold goal. It will not only allow us to track the termination of the container process but also give us a way to learn about the exit of the runc command, whether it's was a successful attempt or not.
The next piece of functionality is related to the synchronous reporting of the container creation status back to the container manager. In case of a broken bundle, runc writes the error to its stderr and then terminates with non-zero exit code. Since the shim process is going to be the closest subreaper, we need to track the termination of the runtime process and then examine the exit code. If it's not equal to 0, we need to read the pipe corresponding to its stderr and report the failure back to the container manager. But how can we report it? For that, the container manager can supply one extra file descriptor at the start of our shim. This file descriptor has to be a unidirectional pipe used solely for the synchronization problem, i.e. reporting of the status of the container creation from the shim to the container manager. The same sync pipe can be used to report the PID of the container process on the successful container creation.
Finally, when the termination status of the runtime process is obtained by the shim and its exit code is 0, we can start serving the container. After runc create the container is in the suspended state. All the resources have been preallocated, and the only missed part is the runc start <container>. The shim process has to monitor 3 things now: stdout pipe of the container becomes readable, stderr pipe of the container becomes readable, or the SIGCHLD signal is received. In the first two cases, the content of the streams needs to be forwarded to the container logs file (the path to the file is provided during the start of the shim). In case of the signal being received, the shim process needs to check the status of the container. If the container process exited, the shim has to write its exit code to the exit file (once again, the path has been provided at the startup) and finish execution.
I tried to make a semi-dynamic diagram with the shim structure:
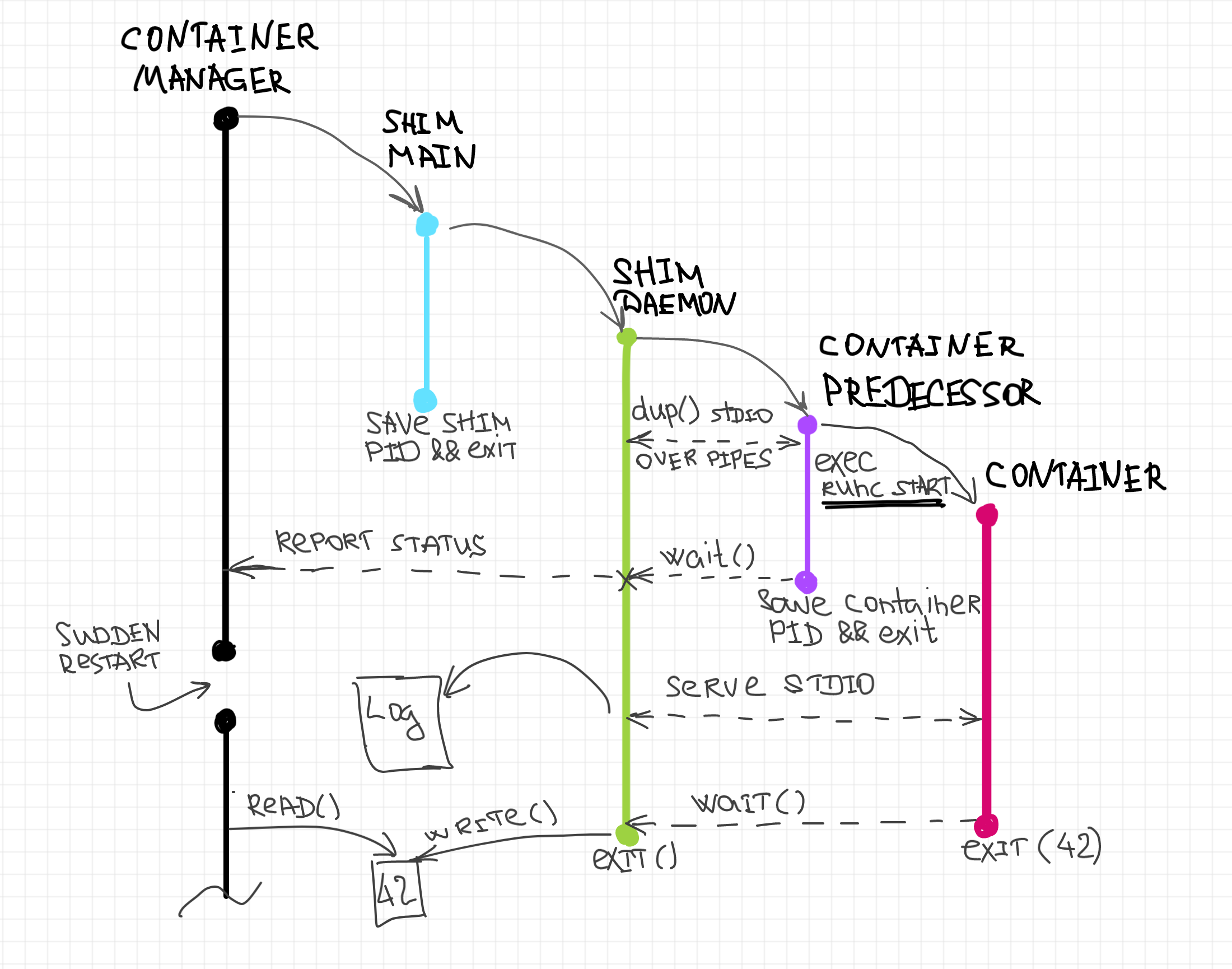
There is a couple of minor implementation details not covered by this rather higher-level design description. The most prominent is probably the termination signal handling. Since there are not many reasons for the container processes to stay alive without the corresponding shim process, it's a good idea to catch signals like SIGINT, SIGQUIT, and SIGTERM sent to the shim process and propagate them to the underlying container (or runtime if it's still alive) instead.
Shim implementation
We will be writing the shim in Rust 'cause I love it since it's a new C. The code of the shim can be found on my GitHub. The implementation is rather straightforward and follows the design from above, but I'd like to cover some interesting (or controversial) parts here.
Сrates used
One of the superpowers of Rust comes from its crates ecosystem. With cargo, it's so much easier to pull in dependency and start using it right away in your code than messing up with all these Makefiles...
The most widely used crate in the shim is nix - a safe wrapper of the Unix-specific parts of libc. This makes perfect sense, because most of the time the code communicates with the system, using one or another system calls. However, for some parts that aren't still covered by nix, I use libc directly.
The shim needs to have extensive logging for both the debug and operational purposes. Luckily, Rust has a generic log crate with some useful backends like syslog.
We also need to deal with I/O a lot, including handling of the Linux signals. At some points the execution of the shim becomes completely I/O driven, meaning the shim hanging on a set of file descriptors awaiting the next bit of data (or a signal) to process. However, this I/O is still blocking, mostly for the sake of simplicity. Even though the famous tokio crate features the non-blocking asynchronous I/O, its low-level component called mio is a nice I/O multiplexer capable to work with the blocking file descriptors as well.
The handling of the command-line parameters can become messy very fast, but thanks to the lovely structopt crate, it's done in the shim in a declarative way.
The shim also uses chrono and serde crates to deal with time and JSON correspondingly, but this is rather overkill and is there for the sake of development velocity.
Error handling
The error handling in Rust is a hot topic. Since Rust doesn't support exceptions, usually, errors need to be propagated explicitly up to a level when an actionable decision can be made. However, in the shim I use except(), unwrap(), and panic() extensively. Even though in general it's an anti-pattern, most of the time errors in the shim are syscall errors. There is not much one can do even if such an error would be propagated up to the main() function. So the strategy is: just let it die and don't pollute the code with the error propagation noise.
Signal handling
The shim process needs to deal with two kinds of signals. First of all, we need to react on SIGCHLD coming from the runtime and container processes. Not every SIGCHLD means the child process termination though and multiple SIGCHLD can also coalesce, so we need to be careful. We can implement the SIGCHLD handling using waitpid() with WNOHANG flag:
pub enum TerminationStatus {
Exited(Pid, ExitCode),
Signaled(Pid, Signal),
}
pub fn get_child_termination_status() -> Option<TerminationStatus> {
match waitpid(Pid::from_raw(-1), Some(WaitPidFlag::WNOHANG)) {
Ok(WaitStatus::Exited(pid, code)) => Some(TerminationStatus::Exited(pid, code)),
Ok(WaitStatus::Signaled(pid, sig, ..)) => Some(TerminationStatus::Signaled(pid, sig)),
Ok(_) => None, // non-terminal state change
Err(nix::Error::Sys(Errno::ECHILD)) => None, // no children left
Err(err) => panic!("waitpid() failed with error {:?}", err),
}
}
fn get_termination_statuses(
runtime_pid: Pid,
) -> (
Option<ProcessTerminationStatus>,
Option<ProcessTerminationStatus>,
) {
let mut runtime: Option<ProcessTerminationStatus> = None;
let mut container: Option<ProcessTerminationStatus> = None;
while let Some(status) = get_child_termination_status() {
if status.pid() == runtime_pid {
assert!(runtime.is_none());
runtime = Some(status);
} else {
assert!(container.is_none());
container = Some(status);
}
}
(runtime, container)
}
The second kind of signals we need to deal with are the deadly ones: SIGINT, SIGQUIT, and SIGTERM. In case the shim got one of these signals, it needs to forward it to the container (or runtime) process and hope for its soon termination. But what if the shim receives such a signal when the runtime process just has exited, but the PID of the container process is not known yet? Seems like we need to memorize this inflight signal to deliver it to the container when its PID is finally picked up from the pidfile:
sig if [SIGINT, SIGQUIT, SIGTERM].contains(&sig) => {
debug!("[shim] {} received, propagating to runtime", sig);
match kill(runtime_pid, sig) {
Ok(KillResult::Delivered) => (), // Keep waiting for runtime termination...
Ok(KillResult::ProcessNotFound) => {
// Runtime already has exited, keep the signal
// to send it to the container once we know its PID.
inflight = Some(sig);
}
Err(err) => panic!("kill(runtime_pid, {}) failed: {:?}", sig, err),
}
}
Regardless of the type, handling of the Linux signals is tricky. Signals happen asynchronously to the main execution flow and can interrupt the code in any arbitrary state. This includes two different complexities. The first one is related to the safety of the signal handlers. If we use callbacks for signal handlers, only the async-signal-safe functions can be used in the callbacks' code. This is tedious but doable. But there is the second type of complexity, related to the non-linear code execution. The business logic of the program becomes event-driven and race-condition-prone. Luckily, for a long time, Linux provides the signalfd feature - a special type of file descriptor that can be used to pull in pending signals once we are ready to process them. However, before using it the signal delivery should be blocked first. For instance, using blocked signals and the signal file descriptor allows us to implement the code waiting for the runtime termination in the following manner:
pub fn signals_block(signals: &[Signal]) -> SigSet {
let mut oldmask = SigSet::empty();
sigprocmask(
SigmaskHow::SIG_BLOCK,
Some(&sigmask(signals)),
Some(&mut oldmask),
)
.expect("sigprocmask(SIG_BLOCK) failed");
return oldmask;
}
// signals_block(&[SIGCHLD, SIGINT, SIGQUIT, SIGTERM]);
// let mut sigfd = Signalfd::new(&[SIGCHLD, SIGINT, SIGQUIT, SIGTERM]);
pub fn await_runtime_termination(
sigfd: &mut Signalfd,
runtime_pid: Pid,
) -> TerminationStatus {
debug!("[shim] awaiting runtime termination...");
let mut container: Option<ProcessTerminationStatus> = None;
let mut inflight: Option<Signal> = None;
loop {
match sigfd.read_signal() {
SIGCHLD => {
debug!("[shim] SIGCHLD received, querying runtime status");
match get_termination_statuses(runtime_pid) {
// ...
}
}
sig if [SIGINT, SIGQUIT, SIGTERM].contains(&sig) => {
debug!("[shim] {} received, propagating to runtime", sig);
match kill(runtime_pid, sig) {
// ...
}
}
sig => panic!("unexpected signal received {:?}", sig),
};
}
}
Reactor pattern and mio
The inspiration for this project has been taken from another shim called conmon. This is a production-ready shim used by cri-o and podman. The problem space of such shims is highly event-driven. Most of the time a shim just awaits the input from or to the controlled container process. The I/O event may arise in the form of some data available on the stdout or stderr of the container process, some new content on the attached stdin stream, a signal and so forth. The conmon shim is written in C and it uses callbacks to handle the asynchronous I/O. This makes the business logic scattered throughout the whole program and it's pretty hard to reproduce the causal relationship of the components.
Luckily, it's possible to tackle the event-driven domains differently. The approach is called a reactor pattern. We can take all the sources of I/O, i.e. the file descriptors corresponding to stdio streams and the signal file descriptor and supply them to a multiplexer, like epoll. And the glorious mio crate provides a slightly higher-level but way more handy wrapper for it:
// see https://github.com/iximiuz/shimmy/blob/v0.1.0/src/container.rs#L32-L254
pub fn serve_container<P: AsRef<Path>>(
sigfd: Signalfd,
container_pid: Pid,
container_stdio: IOStreams,
container_logfile: P,
) -> TerminationStatus {
debug!("[shim] serving container {}", container_pid);
let mut server = reactor::Reactor::new(
container_pid,
logwriter::LogWriter::new(container_logfile),
Duration::from_millis(5000),
);
server.register_signalfd(sigfd);
server.register_container_stdout(container_stdio.Out);
server.register_container_stderr(container_stdio.Err);
server.run()
}
mod reactor {
const TOKEN_STDOUT: Token = Token(10);
const TOKEN_STDERR: Token = Token(20);
const TOKEN_SIGNAL: Token = Token(30);
pub struct Reactor {
poll: Poll,
heartbeat: Duration,
// ...
}
impl Reactor {
pub fn new(/* ... */) -> Self {
Self {
poll: Poll::new().expect("mio::Poll::new() failed"),
heartbeat: heartbeat,
// ...
}
}
pub fn register_container_stdout(&mut self, stream: IOStream) {}
pub fn register_container_stderr(&mut self, stream: IOStream) {}
pub fn register_signalfd(&mut self, sigfd: Signalfd) {}
pub fn run(&mut self) -> TerminationStatus {
while self.cont_status.is_none() {
if self.poll_once() == 0 {
debug!("[shim] still serving container {}", self.cont_pid);
}
}
self.cont_status.unwrap()
}
fn poll_once(&mut self) -> i32 {
let mut events = Events::with_capacity(128);
self.poll.poll(&mut events, Some(self.heartbeat)).unwrap();
let mut event_count = 0;
for event in events.iter() {
event_count += 1;
match event.token() {
TOKEN_STDOUT => self.handle_cont_stdout_event(&event),
TOKEN_STDERR => self.handle_cont_stderr_event(&event),
TOKEN_SIGNAL => self.handle_signalfd_event(&event),
_ => unreachable!(),
}
}
event_count
}
}
}
Integration with conman
Last but not least, we need to teach our experimental container manager to deal with the container runtime shim.
Synchronous container creation errors
It's time to use the sync pipe and send its file descriptor to the shim. The corresponding change needs to be done in the oci.Runtime.CreateContainer() method:
func (r *runcRuntime) CreateContainer(
id container.ID,
bundleDir string,
logfile string,
exitfile string,
timeout time.Duration,
) (pid int, err error) {
cmd := exec.Command(
r.shimmyPath,
"--shimmy-pidfile", path.Join(bundleDir, "shimmy.pid"),
"--shimmy-log-level", strings.ToUpper(logrus.GetLevel().String()),
"--runtime", r.runtimePath,
"--runtime-arg", fmt.Sprintf("'--root=%s'", r.rootPath),
"--bundle", bundleDir,
"--container-id", string(id),
"--container-pidfile", path.Join(bundleDir, "container.pid"),
"--container-logfile", logfile,
"--container-exitfile", exitfile,
)
syncpipeRead, syncpipeWrite, err := os.Pipe()
if err != nil {
return 0, err
}
defer syncpipeRead.Close()
defer syncpipeWrite.Close()
cmd.ExtraFiles = append(cmd.ExtraFiles, syncpipeWrite)
cmd.Args = append(
cmd.Args,
// 0,1, and 2 are STDIO streams
"--syncpipe-fd", strconv.Itoa(2+len(cmd.ExtraFiles)),
)
// We expect shimmy execution to be almost instant, because its
// main process just validates the input parameters, forks the
// shim process, saves its PID on disk, and then exits.
if _, err := runCommand(cmd); err != nil {
return 0, err
}
syncpipeWrite.Close()
type Report struct {
Kind string `json:"kind"`
Status string `json:"status"`
Stderr string `json:"stderr"`
Pid int `json:"pid"`
}
return pid, timeutil.WithTimeout(timeout, func() error {
bytes, err := ioutil.ReadAll(syncpipeRead)
if err != nil {
return err
}
syncpipeRead.Close()
report := Report{}
if err := json.Unmarshal(bytes, &report); err != nil {
return errors.Wrap(
err,
fmt.Sprintf("Failed to decode report string [%v]. Raw [%v].",
string(bytes), bytes),
)
}
if report.Kind == "container_pid" && report.Pid > 0 {
pid = report.Pid
return nil
}
return errors.Errorf("%+v", report)
})
}
Now, if we try to create a container with a misspelled command name, the error report will be shown right away:
> bin/conmanctl container create --image test/data/rootfs_alpine/ cont1 -- bahs
FATA[0000] Command failed (see conmand logs for details)
error="rpc error: code = Unknown
desc = {
Kind:runtime_abnormal_termination
Status:Runtime Exited with code 1.
Stderr:container_linux.go:345: starting container process caused \"exec: \\\"bahs\\\":
executable file not found in $PATH\"\n Pid:0
}"
The previous version of conman would not even notice such an error until the consequent attempt to start the container. But even in this case, the diagnostic message from runc would be lost in the ether.
Container exit code tracking
The second change needs to be done in the cri.RuntimeService component. On every container status check, if the state of the container is stopped, we need to parse the exit file from the agreed location on disk.
func (rs *runtimeService) getContainerNoLock(
id container.ID,
) (*container.Container, error) {
cont := rs.cmap.Get(id)
if cont == nil {
return nil, errors.New("container not found")
}
// Request container state
state, err := rs.runtime.ContainerState(cont.ID())
if err != nil {
return nil, err
}
// Set container status from state
status, err := container.StatusFromString(state.Status)
if err != nil {
return nil, err
}
cont.SetStatus(status)
// Set container exit code if applicable
if cont.Status() == container.Stopped {
ts, err := rs.parseContainerExitFile(id)
if err != nil {
return nil, err
}
cont.SetFinishedAt(ts.At())
if ts.IsSignaled() {
cont.SetExitCode(127 + ts.Signal())
} else {
cont.SetExitCode(ts.ExitCode())
}
}
blob, err := cont.MarshalJSON()
if err != nil {
return nil, err
}
if err := rs.cstore.ContainerStateWriteAtomic(id, blob); err != nil {
return nil, err
}
return cont, nil
}
If we try to run an intentionally broken container, the conmanctl container status command will reveal its exit code and the path to the file with logs:
> bin/conmanctl container create --image test/data/rootfs_alpine/ cont2 -- mkdir /foo/bar
{"containerId":"5028faee161e42789b597d67fe448e65"}
> bin/conmanctl container start 5028faee161e42789b597d67fe448e65
{}
> bin/conmanctl container status 5028faee161e42789b597d67fe448e65
{
"status": {
"containerId": "5028faee161e42789b597d67fe448e65",
"containerName": "cont2",
"state": "EXITED",
"createdAt": "1576741340000000000",
"startedAt": "0",
"finishedAt": "1576741355000000000",
"exitCode": 1,
"message": "",
"logPath": "/var/log/conman/containers/5028faee161e42789b597d67fe448e65.log"
}
}
> cat /var/log/conman/containers/5028faee161e42789b597d67fe448e65.log
2019-12-19T07:42:35.381893667+00:00 stderr mkdir: can't create directory '/foo/bar': No such file or directory
Having this functionality in conman brings our troubleshooting abilities to the next level.
Stay tuned
In the next articles we will add support for:
- Interactive containers. This will allow us to send input data to running containers, similarly to
echo "foo" | docker run -i ubuntu cat. - Pseduo-terminal-controlled containers. This will enable interactive shell-based use cases, close to the famous
docker run -it ubuntu bash.
Related articles
- Implementing Container Runtime Shim: runc
- Implementing Container Runtime Shim: Interactive Containers
- conman - [the] Container Manager: Inception
- A journey from containerization to orchestration and beyond
More Container insights from this blog
- conman - [the] Container Manager: Inception
- Implementing Container Runtime Shim: runc
- Implementing Container Runtime Shim: First Code
- Implementing Container Runtime Shim: Interactive Containers
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
