Containers gave birth to more advanced server-side architectures and sophisticated deployment techniques. Containers nowadays are so widespread that there is already a bunch of standard-alike specifications (1, 2, 3, 4, ...) describing different aspects of the containers universe. Of course, on the lowest level lie Linux primitives such as namespaces and cgroups. But containerization software is already so massive that it would be barely possible to implement it without its own concern separation layers. What I'm trying to achieve in this ongoing effort is to guide myself starting from the lowest layers to the topmost ones, having as much practice (code, installation, configuration, integration, etc) and, of course, fun as possible. The content of this page is going to be changing over time, reflecting my understanding of the topic.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
Container Runtimes
I want to start the journey from the lowest level non-kernel primitive - container runtime. The word runtime is a bit ambiguous in the containerverse. Each project, company or community has its own and usually context-specific understanding of the term container runtime. Mostly, the hallmark of the runtime is defined by the set of responsibilities varying from a bare minimum (creating namespaces, starting a containerized process) to comprehensive container management including (but not limiting) images operation. A good overview of runtimes can be found in this article.
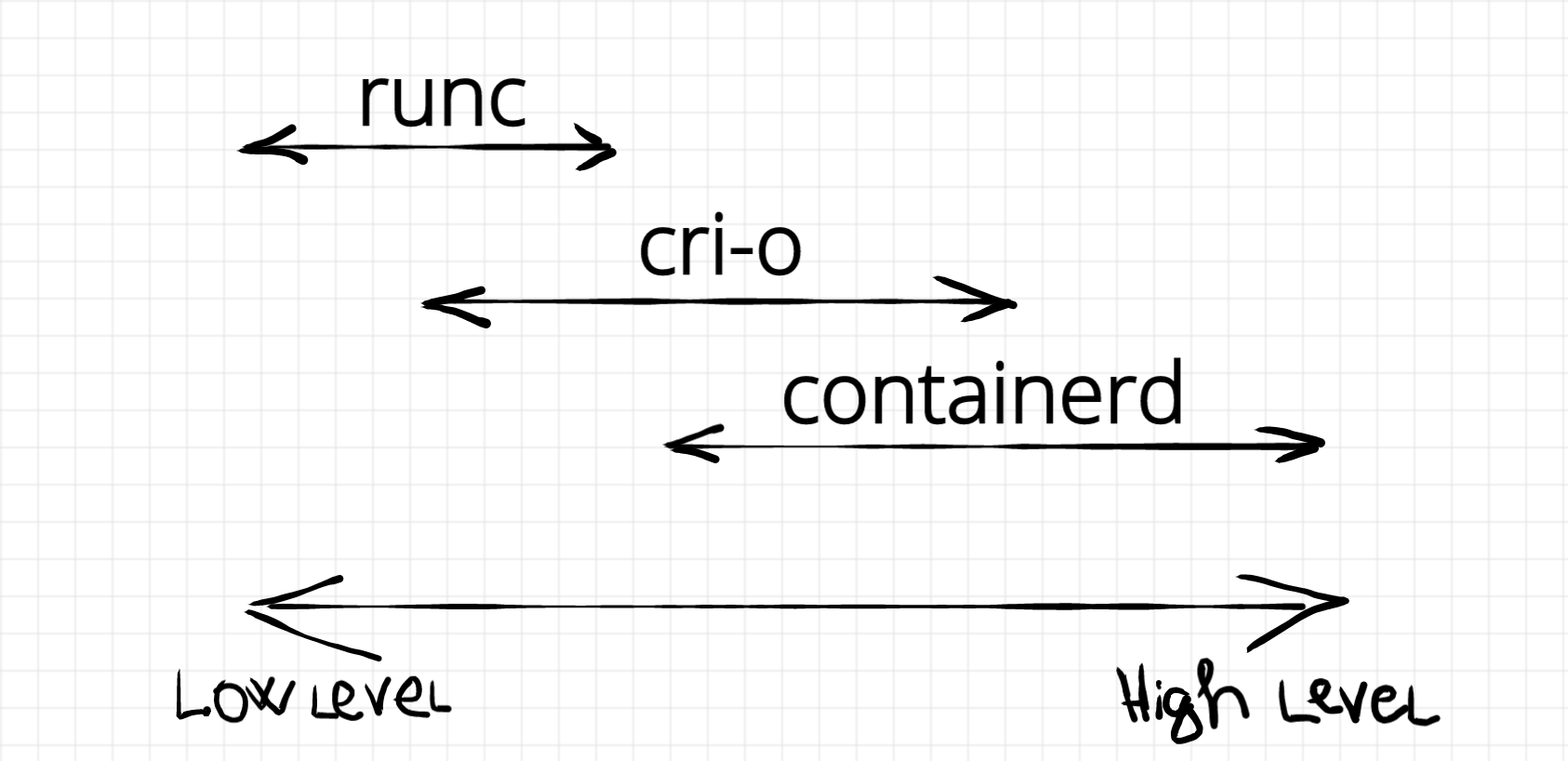
This section is dedicated to low-level container runtimes. A group of big players forming an Open Container Initiative standardized the low-level runtime in the OCI runtime specification. Making a long story short - a low-level container runtime is a piece of software that takes as an input a folder containing rootfs and a configuration [file] describing container parameters (such as resource limits, mount points, process to start, etc) and as a result the runtime starts an isolated process, i.e. container well... a workload. UPD: Often a workload is represented by a container, i.e. isolated and restricted Linux process. But the good part about OCI runtime specification is that is doesn't define the actual implementation of the runtime. Rather it defines the way to communicate with it. See the section below for alternative (and more secure) runtime implementations.
As of 2019, the most widely used container runtime is runc. This project started as a part of Docker (hence it's written in Go) but eventually was extracted and transformed into a self-sufficient CLI tool. It is difficult to overestimate the importance of this component - runc is basically a reference implementation of the OCI runtime specification. During our journey we will work a lot with runc and here is an introductory article.
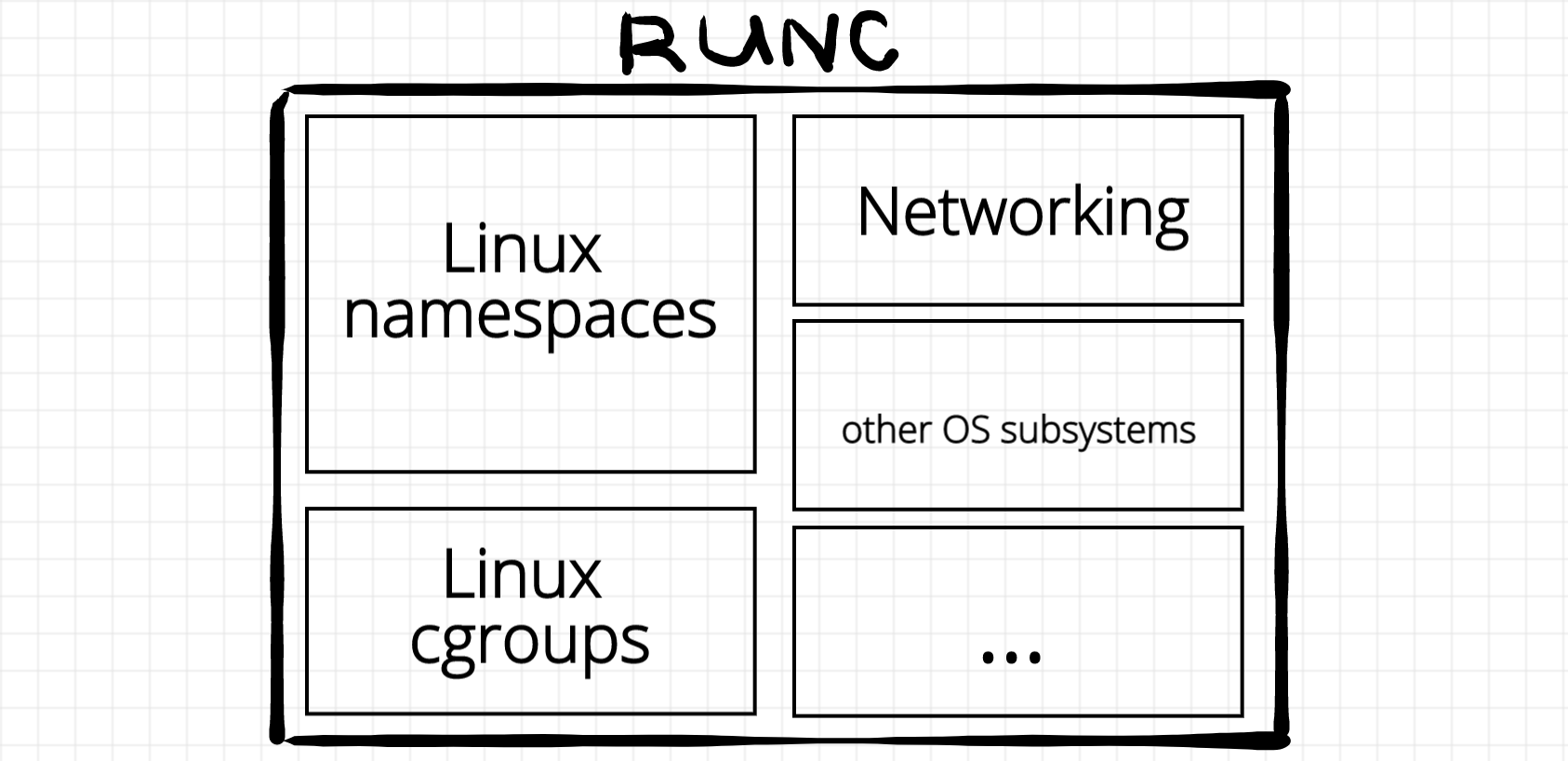
One more notable OCI runtime implementation out there is crun. It's written in C and can be used both as an executable and as a library. It's been originated by Red Hat and other Red Hat projects like buildah or podman tend to use crun instead of runc.
UPDATE Aug 2020: Historically, Docker was advocating for a "single container - single process" model and despite of some constant demand to bring containers somewhat closer to traditional virtual machines (with systemd or alike manager inside), it has never been officially supported by runc (while it's still possible via running tailored privileged containers). Luckily, there is a fresh (~90%) OCI-compatible container runtime called sysbox aiming to solve this problem.
Sysbox is an open-source container runtime (aka runc), originally developed by Nestybox, that enables Docker containers to act as virtual servers capable of running software such as Systemd, Docker, and Kubernetes in them, easily and with proper isolation. This allows you to use containers in new ways, and provides a faster, more efficient, and more portable alternative to virtual machines in many scenarios.
[More] Secure Container Runtimes
Traditional containers are lightweight, fast, and handy. But there is a significant problem with them. Since containers are essentially just isolated and restricted Linux processes, we are one kernel bug away from letting the containerized code gaining access to the host system. Depending on the environment, it can become a significant concern (say hi to multi-tenant clusters running potentially malicious workloads).
Traditional virtual machines provide an alternative and more secure (through higher-extent of isolation) way to run arbitrary code. But the price of that is a clumsier orchestration, higher per-workload overhead (CPU, RAM, disk space), and poor startup time (tens of seconds instead of milliseconds in the case of containers).
You can read more about the dilemma in this overview article.
Luckily, there is a bunch of projects trying to make lightweight container-like VMs. And one more time thanks to the power of standardisation - these implementation are OCI-compatible. Hence, they can be used by higher-level runtimes (below).
The notorious projects in this realm are Kata Containers, firecracker (though firecracker-containerd), and gVisor.
The implementation details vary between the projects, but the idea is to put another Linux-ish layer (an optimized VM, or user-space kernel implementation) on top of the host OS. Every such sandbox VM-like environment can have one ore many workloads running inside. Since the implementations are highly-optimized, the per-workload overhead is minimal and the startup time is still under a second.
- firecracker-containerd is a firecracker microVM (read a highly-optimized QEMU written in 50 kLOC of Rust) running a guest operating system with a bunch of runc-driven containers inside, integrated with containerd through a custom containerd-shim.
- kata containers project is a promising attempt to abstract an optimized hypervisor (KVM, QEMU, or even Firecracker) running a specialized OS image as a guest VM. Every such VM has an agent inside that can spawn workloads (architecture overview). They are OCI, CRI, and containerd compatible (source).
- gVisor runs a user-space application kernel written in Go (essentially a sandbox) that implements a necessary subset of Linux system calls. It provides a runsc (much like runc) OCI-compatible runtime. But because it's completely user-space, the runtime overhead is pretty high.
For a more detailed overview of these project check out this article.
Container management
Using runc in command line we can launch as many containers as we want. But what if we need to automate this process? Imagine we need to launch tens of containers keeping track of their statuses. Some of them need to be restarted on failure, resources need to be released on termination, images have to be pulled from registries, inter-containers networks need to be configured and so on. This is already a slightly higher-level job and it's a responsibility of a container manager. To be honest, I have no idea whether this term is in common use or not, but I found it convenient to structure things this way. I would classify the following projects as container managers: containerd, cri-o, dockerd, and podman.
containerd
As with runc, we again can see a Docker's heritage here - containerd used to be a part of the original Docker project. Nowadays though containerd is another self-sufficient piece of software. It calls itself a container runtime but obviously, it's not the same kind of runtime runc is. Not only the responsibilities of containerd and runc differ but also the organizational form does. While runc is a just a command-line tool, containerd is a long-living daemon. An instance of runc cannot outlive an underlying container process. Normally it starts its life on create invocation and then just execs the specified file from container's rootfs on start. On the other hand, containerd can outlive thousands of containers. It's rather a server listening for incoming requests to start, stop, or report the status of the containers. And under the hood containerd uses runc. (UPD: Actually, containerd is not limited by runc. See the UPDATE below). However, containerd is more than just a container lifecycle manager. It is also responsible for image management (pull & push images from a registry, store images locally, etc), cross-container networking management and some other functions.
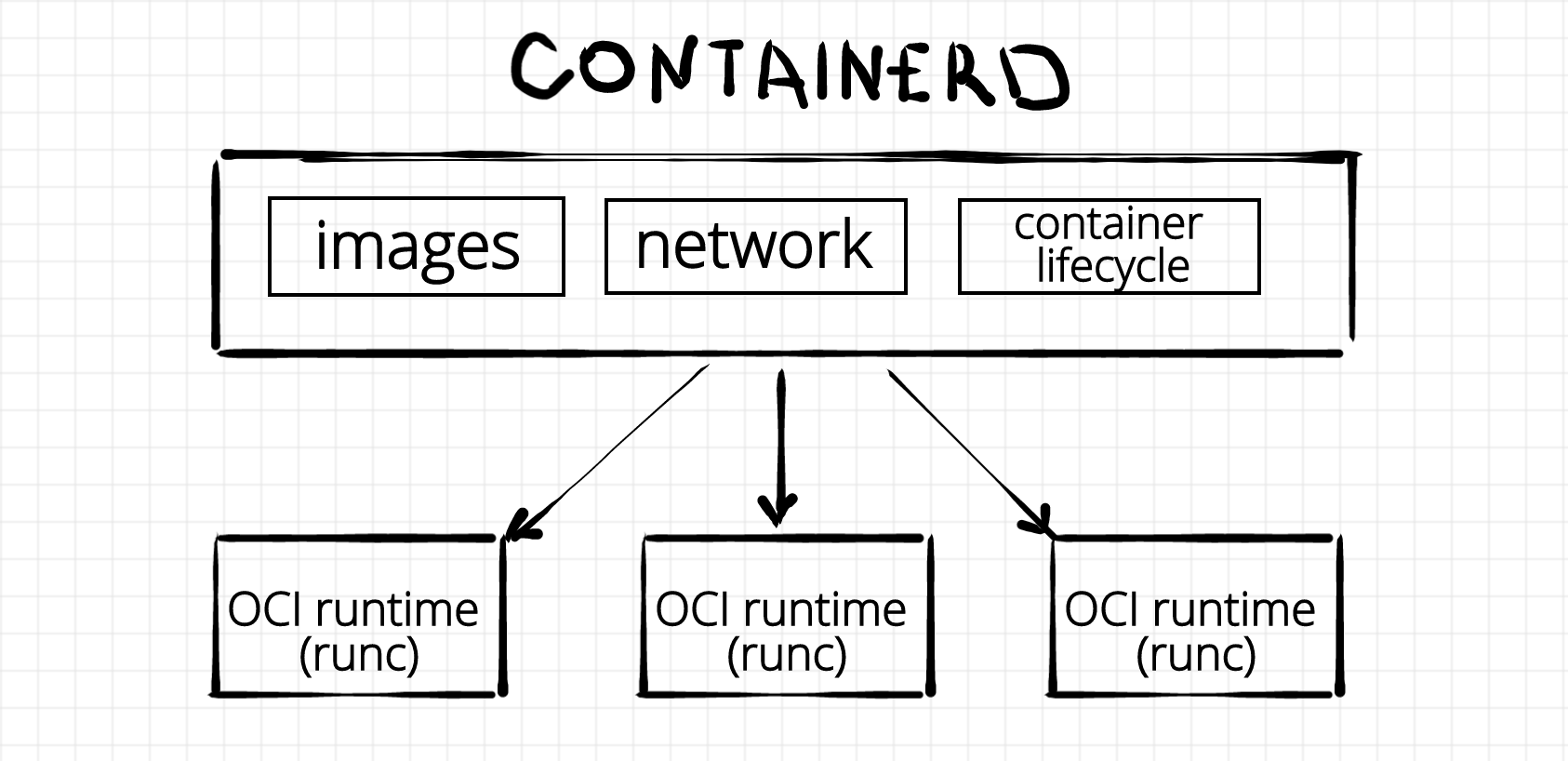
UPDATE Feb 2021: Containerd project is getting more and more traction in the Cloud Native community. Mostly because of its well-turned design. It nicely fits as a sort of plumbing in between higher-level tools like Docker or Kubernetes and lower-level runtimes like runc, gVisor, or firecracker. Containerd authors even standardized the way a new lower-level runtime can be plugged in. It should be done now by implementing a new containerd-shim. There is a bunch of production-ready implementations of the shim out there.
cri-o
Another container manager example is cri-o. While containerd evolved as a result of Docker re-architecting, cri-o has its roots in the Kubernetes realm. Back in the day, Kubernetes (ab)used Docker to manage containers. However, with rising of rkt some brave people added support of interchangeably container runtimes in Kubernetes, allowing container management to be done by Docker and/or rkt. This change, however, led to a huge number of conditional code in kubelet and nobody likes too many ifs in the code. As a result, Container Runtime Interface (CRI) was developed for Kubernetes. It made possible for any CRI-compliant higher-level runtimes (i.e. container managers) to be used without any code change on the Kubernetes side:
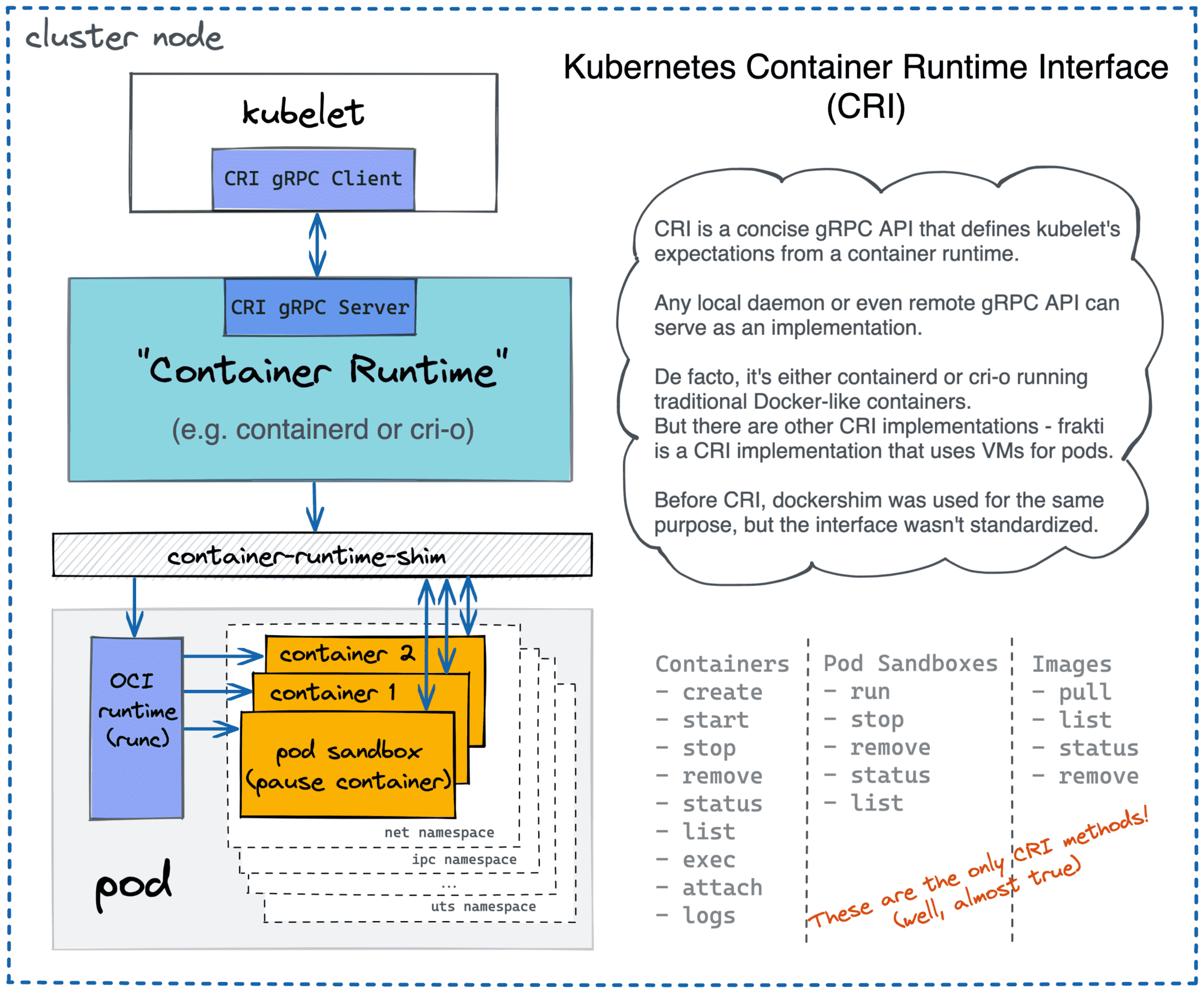
Kubernetes uses different container runtimes via CRI API.
The cri-o project is a Red Hat's implementation of CRI-complaint runtime. As with containerd cri-o is also a daemon exposing a [gRPC] server with endpoints to create, start, stop (and many more other actions) containers. Under the hood, cri-o can use any OCI-compliant [low-level] runtimes to work with containers but the default one is again runc. The main focus of cri-o is being a Kubernetes container runtime. The versioning is the same as k8s versioning, the scope of the project is well-defined and the code base is expectedly smaller (as of July 2019 it's around 20 CLOC and it's approximately 5 times less than containerd).
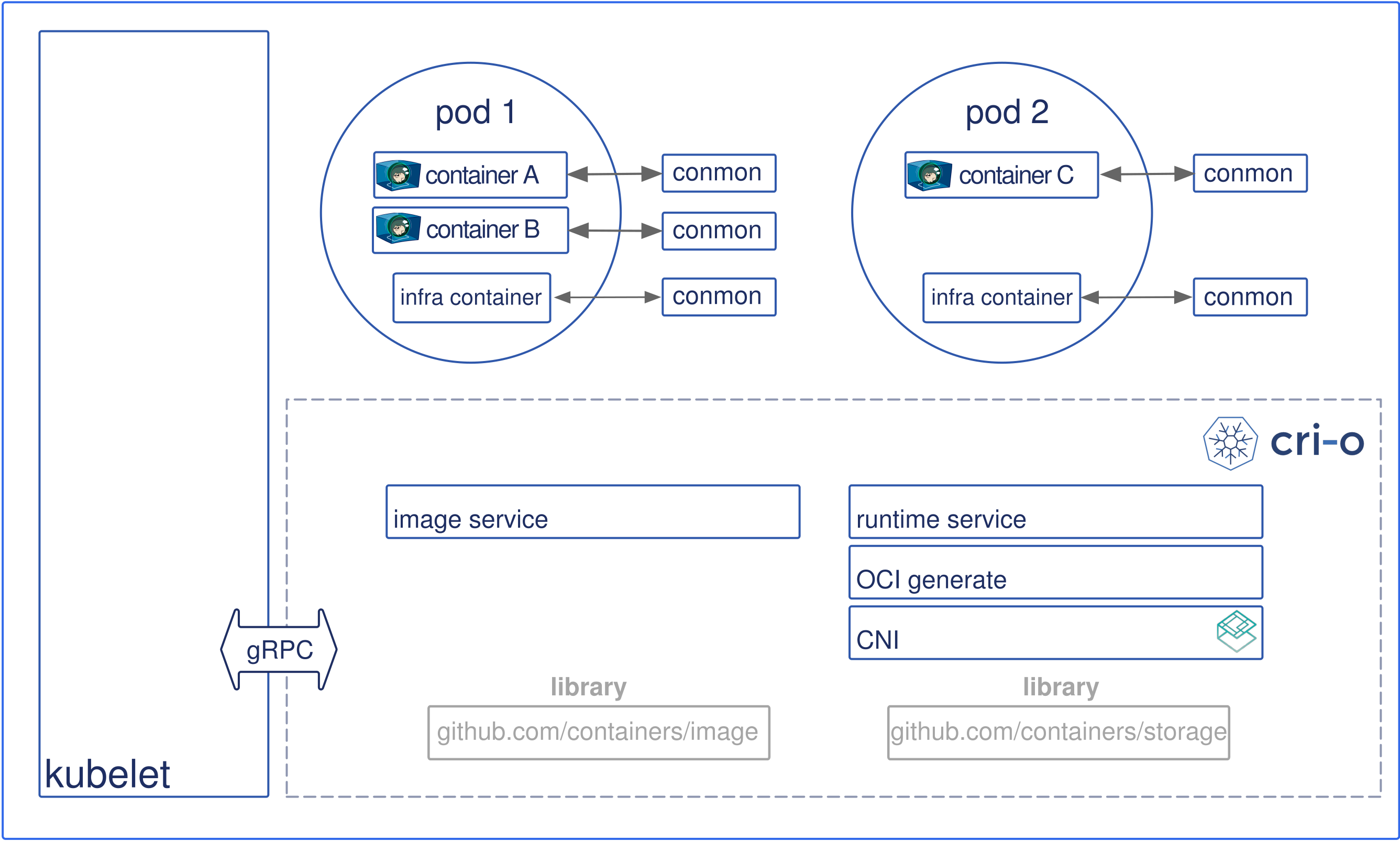
cri-o architecture (image from cri-o.io)
The nice thing about specifications is that everything complaint can be used interchangeably. Once CRI has been introduced, a plugin for containerd, implementing CRI gRPC server on top of containerd's functionality appeared. The idea happened to be viable and later on, containerd itself got a native CRI support. Thus, Kubernetes can use both cri-o and containerd as a runtime.
UPDATE Feb 2021: In December, 2020 Kubernetes finally deprecated its Docker support. Despite the CRI invention in 2016, the conditional code in kubelet still remains. Essentially, Kubernetes supports Docker as a container runtime through a so-called Dockershim module and all other container runtimes through CRI module. It seems like after Docker's Mirantis acquisition in late 2019, the chances of Docker implementing CRI became way to low (well, Docker folks just decided to focus more on developer experience than on integration with production systems). And as a result Kubernetes community decided to get rid of Docker support completely. Well, makes sense, Docker is too bloated for a CRI runtime, IMO. So, we are one cleanup away from freeing kubelet of Dockershim code (the plan is to remove it in Kubernetes v1.23). Another nice part about it is that for regular developers there is nothing to worry about. Thanks to the OCI standardisation, images build locally using Docker (or Podman, or any other compatible tool), will keep working on Kubernetes.
dockerd
One more daemon here is dockerd. This daemon is manifold. On the one hand, it exposes an API for Docker command-line client which gives us all these famous Docker workflows (docker pull, docker push, docker run, docker stats, etc). But since we already know, that this piece of functionality has been extracted to containerd it's not a surprise that under the hood dockerd relies on containerd. But that basically would mean that dockerd is just a front-end adapter converting containerd API to a historically widely used docker engine API.
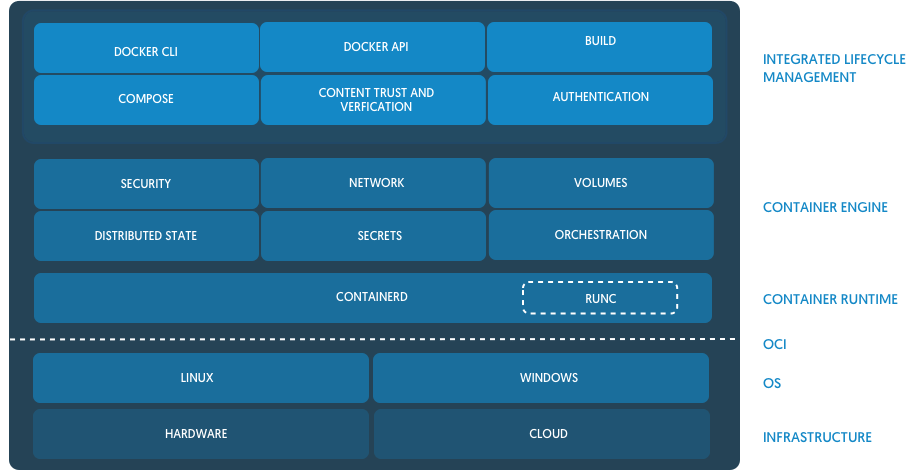
dockerd is a part in front of containerd (image from Docker Blog)
However, dockerd also provides compose and swarm things in an attempt to solve container orchestration problem, including multi-machine clusters of containers. As we can see with Kubernetes, this problem is rather hard to address. And having two big responsibilities for a single dockerd daemon doesn't sound good to me.
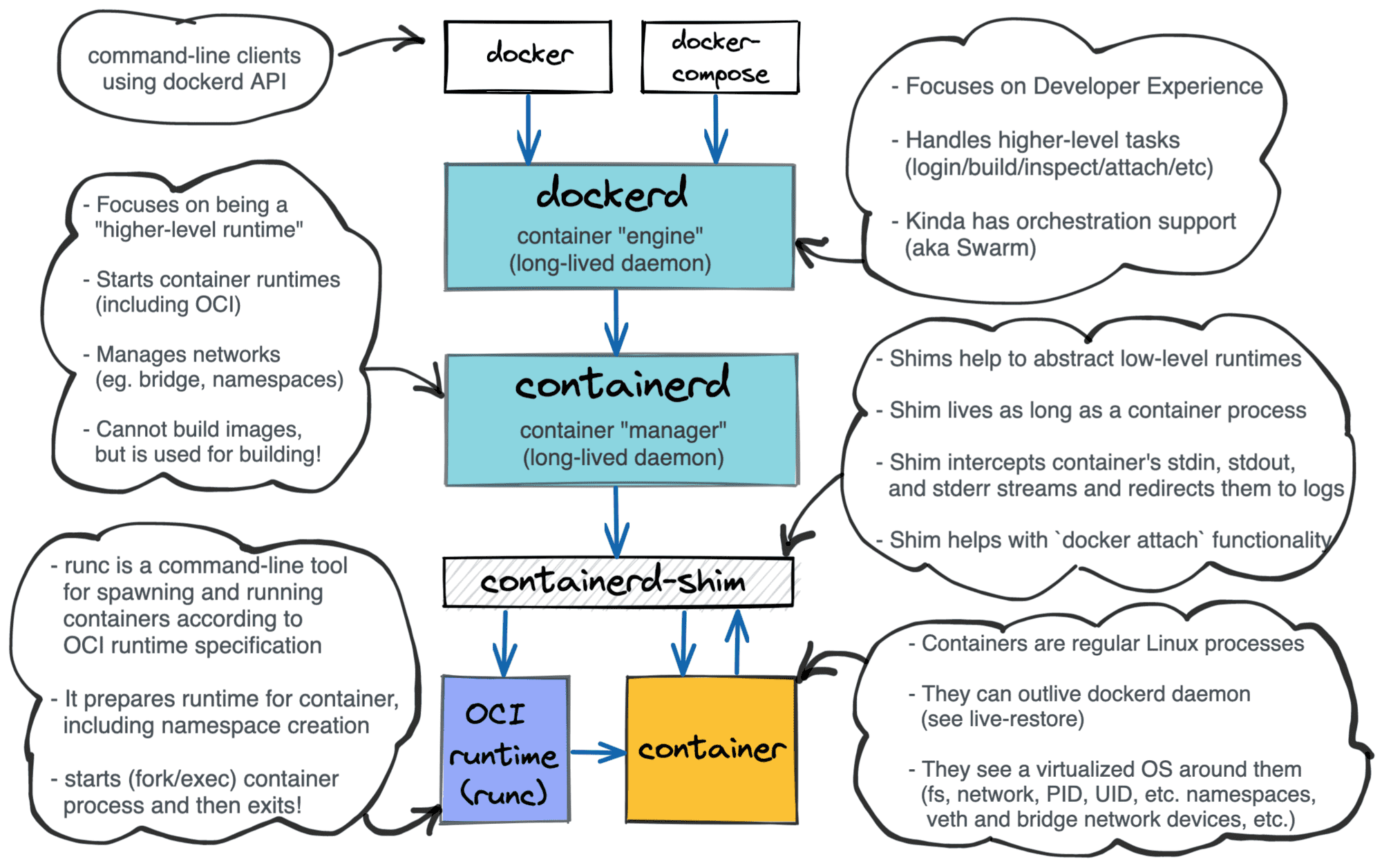
Layered Docker architecture.
UPDATE from November, 2019 - Mirantis acquired Docker Enterprise:
A blog post announcing the acquisition implied that Docker Swarm will be phased out, with Ionel writing that “The primary orchestrator going forward is Kubernetes. Mirantis is committed to providing an excellent experience to all Docker Enterprise platform customers and currently expects to support Swarm for at least two years, depending on customer input into the roadmap. Mirantis is also evaluating options for making the transition to Kubernetes easier for Swarm users.”
podman
An interesting exception from this daemons list is podman. It's yet another Red Hat project and the aim is to provide a library (not a daemon) called libpod to manage images, container lifecycles, and pods (groups of containers). And podman is a management command-line tool built on top of this library. As a low-level container runtime this project as usual uses runc. There is a lot in common between podman and cri-o (both are Red Hat projects) from the code standpoint. For instance, they both heavily use outstanding storage and image libraries internally. It seems that there's an ongoing effort to use libpod instead of runc directly in cri-o. Another interesting feature of podman is a drop-in replacement of some (most popular?) docker commands in a daily workflow. The project claims compatibility (to some extent of course) of the docker CLI API.
Why start a project like this when we already have dockerd, containerd or cir-o? The problem with daemons as container managers is that most of the time a daemon has to be run with root privileges. Even though 90% of the daemon's functionality can be hypothetically done without having root rights in the system since daemon is a monolithic thing, the remaining 10% requires that the daemon is launched as root. With podman, it's finally possible to have rootless containers utilizing Linux user namespaces. And this can be a big deal, especially in extensive CI or multi-tenant environments, because even non-privileged Docker containers are actually only one kernel bug away from gaining root access on the system.
More information on this intriguing project can be found here and here.

conman
Here is my (WiP) project aiming at the implementation of a tiny container manager. It's primarily for educational purposes, but the ultimate goal though is to make it CRI-compatible and launch a Kubernetes cluster with conman as a container runtime. Here you can find an introductory article about the project.
Runtime shims
Containers can be long-running while a container manager may need to be restarted due to a crash, update, or some other unforeseen reasons without killing (or losing control of) the managed containers. Thus, the container's process has to be fully independent of the manager's process while still preserving some communicational means. If you try to implement it yourself, you will find that with runc as a container runtime it gets complicated pretty quickly. Following is a list of difficulties need to be addressed.
Keep container's stdio streams open on container manager restart
We need to forward the data written by the container to its STDOUT and STDERR to logs at any given moment of time, regardless of the state of the manager. Surprisingly, the design of runc makes it a non-trivial task because runc tend to pass through the caller's stdio streams to the container. Thus, making the runc process independent of its parent becomes barely possible. If we launch runc in the detached mode and then unluckily terminate the parent, an attempt to read from STDIN or write to STDOUT/STDERR can cause the container to be killed by SIGPIPE.
Keep track of container exit code
OCI runtime specification standartizes the launching of a container as a two-steps procedure. First, the container needs to be created (i.e. fully initialized) and only then started. On container creation step, runc deliberately daemonizes the container process by forking and then exiting the foreground process. Having containers detached leads to an absence of container status update. One way to address this problem is to make the process launching runc a subreaper. Then we can teach it to wait for the container's process termination and report its exit code to a predefined location (eg. a file on the disk). Of course, the subreaper process needs to stay alive until the end of the container's existence.
Synchronize container manager and runc container creation
Since runc daemonizes the container creation process we need a side-channel (eg. a Unix socket) to communicate the actual start (or failure) of the container back to the container manager.
Attaching to a running container
We need to provide a way to stream some data in and out from the container, including PTY-controlled scenarios. It sounds like we need a listening server accepting attaching connections and performing the streaming to and from the container's stdio. And again this server has to be long-lived.
To address all these problems (and probably some others) so-called runtime shims are usually used. A shim is a lightweight daemon controlling a running container. The shim's process is tightly bound to the container's process but is completely detached from the manager's process. All the communications between the container and the manager happen through the shim. Examples of the shims out there are conmon and containerd runtime shim. I spent some time trying to implement my own shim as a part of the conman project and the results can be found in the article "Implementing container runtime shim".
Container Network Interface (CNI)
Since we have multiple container runtimes (or managers) with overlapping responsibilities it's pretty much obvious that we either need to extract networking-related code to a dedicated project and then reuse it, or each runtime should have its own way to configure NIC devices, IP routing, firewalls, and other networking aspects. For instance, both cri-o and containerd have to create Linux network namespaces and setup Linux bridges and veth devices to create sandboxes for Kubernetes pods. To address this problem, the Container Network Interface project was introduced.
The CNI project provides a Container Network Interface Specification defining a CNI Plugin. A plugin is an executable [sic] which is supposed to be called by container runtime (or manager) to set up (or release) a network resource. Plugins can be used to create a network interface, manage IP addresses allocation, or do some custom configuration of the system. CNI project is language-agnostic, and since a plugin defined as an executable, it can be used in a runtime management system implemented in any programming language. However, CNI project also provides a set of reference plugin implementations for the most popular use cases shipped as a separate repository named plugins. Examples are bridge, loopback, flannel, etc.
Some 3rd party projects implement their network-related functionality as CNI plugins. To name a few most famous things here we should mention Project Calico and Weave.
Orchestration
Orchestration of the containers is an extra-large topic. In reality, the biggest part of the Kubernetes code addresses rather the orchestration problem than containerization. Thus, orchestration deserves its own article (or a few). Hopefully, they will follow soon.
UPD, Aug 2022: Three years later, the first one showed up: How Kubernetes Reinvented Virtual Machines (in a good sense).
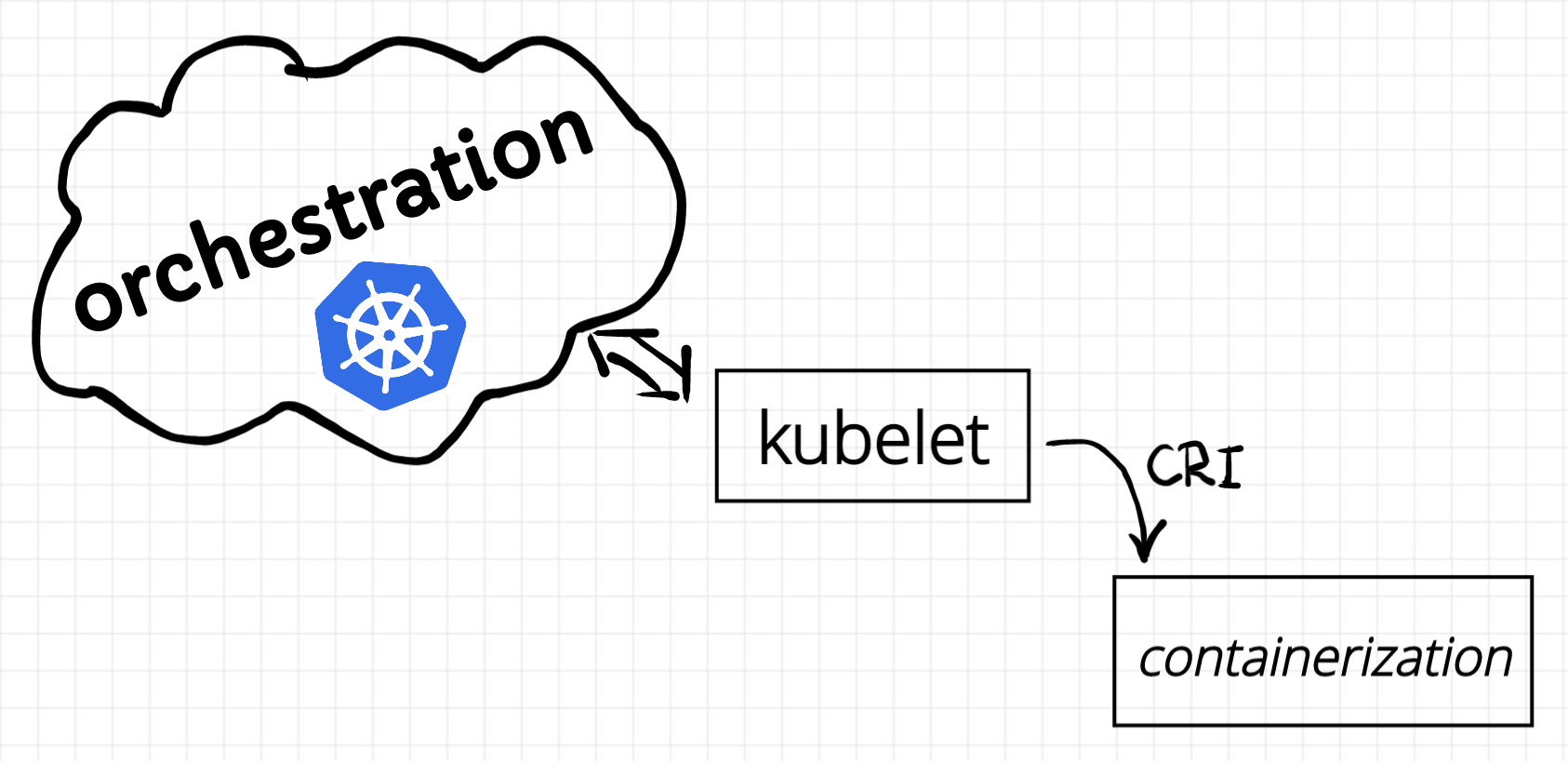
Related Articles
- conman - [the] Container Manager: Inception
- Implementing container runtime shim
- Not every container has an operating system inside
- You don't need an image to run a container
- You need containers to build images
Appendix I: Notable Projects
👉 Find a more complete (and curated) list of projects on iximiuz/awesome-container-tinkering.
buildah
Buildah is a command-line tool to work with OCI container images. It's a part of a group of projects (podman, skopeo, buildah) started by RedHat with an aim at redesigning Docker's way to work with containers (primarily to switch from monolithic and daemon-based to more fine-grained approach).
cni
CNI Project defines a Container Network Interface plugin specification as well as some Go tools to work with it. For a more in-depth explanation see the corresponding section of the article.
cni-plugins
A home repository for the most popular CNI plugins (such as bridge, host-device, loopback, dhcp, firewall, etc). For a more in-depth explanation see the corresponding section of the article.
containerd
A higher-level container runtime (or container manager) started as a part of Docker and extracted to an independent project. For a more in-depth explanation see the corresponding section of the article.
conmon
A tiny OCI runtime shim written in C and used primarily by cri-o. It provides synchronization between a parent process (cri-o) and the starting containers, tracking of container exit codes, PTY forwarding, and some other features. For a more in-depth explanation see the corresponding section of the article.
cri-o
Kubernetes-focused container manager following Kubernetes Container Runtime Interface (CRI) specification. The versioning is same as k8s versioning. For a more in-depth explanation see the corresponding section of the article.
crun
Yet another OCI runtime spec implementation. It claims to be a "...fast and low-memory footprint OCI Container Runtime fully written in C." But the most importantly it can be used as a library from any C/C++ code (or providing bindings - from other languages). It allows avoiding some runc specific drawbacks caused by its daemon-nature. See Runtime Shims section for more.
Firecracker
A highly-optimized virtual machine monitor (VMM). Much like QEMU, but with lots of things removed. 50 kLOC of Rust.
firecracker-containerd
A secure low-level container runtime utilizing Firecracker, runc, and containerd-shim.
gVisor
A secure low-level container runtime (runsc) implemented as an application (i.e. user-space) kernel. Kind of a system calls interceptor written in Go.
image
An underrated (warn: opinions!) Go library powered such well-known projects as cri-o, podman and skopeo. Probably it's easy to guess by its name - the aim is at working in various way with containers' images and container image registries.
Kata Containers
A secure low-level container runtime utilizing QEMU/KVM-driven lightweight virtual machines to run containerized workloads.
lxc
An alternative and low-level container runtime written in C.
lxd
A higher-level container runtime (or container manager) written in Go. Under the hood, it uses lxc as low-level runtime.
moby
A higher-level container runtime (or container manager) formerly known as docker/docker. Provides a well-known Docker engine API based on containerd functionality. For a more in-depth explanation see the corresponding section of the article.
OCI distribution spec
A specification of a container image distribution (WiP).
OCI image spec
A specification of a container image.
OCI runtime spec
A specification of a [low level] container runtime.
podman
A daemon-less Docker replacement. The frontman project of Docker redesign effort. More explanation can be found on RedHat developers blog.
rkt
Another container management system. It provides a low-level runtime as well as a higher-level management interface. It advertises to be pod-native. An idea to add rkt support to Kubernetes gave birth to CRI specification. The project was started by CoreOS team ~5 years ago, but after its acquisition by RedHat, it is rather stagnating. As of August 2019, the last commit to the project is about 2 months old. UPDATE: On August, 16th, CNCF announced that the Technical Oversight Committee (TOC) has voted to archive the rkt project.
runc
A low-level container runtime and a reference implementation of OCI runtime spec. Started as a part of Docker and extracted to an independent project. Extremely ubiquitous. For a more in-depth explanation see the corresponding section of the article.
skopeo
Skopeo is a command-line utility that performs various operations on container images and image repositories. It's a part of RedHat effort to redesign Docker (see also podman and buildah) by extracting its responsibilities to dedicated and independent tools.
storage
An underrated (warn: opinions!) Go library powered such well-known projects as cri-o, podman and skopeo. is a Go library which aims to provide methods for storing filesystem layers, container images, and containers (on disk). It also manages mounting of bundles.
sysbox
An open-source container runtime that enables Docker containers to act as virtual servers capable of running software such as Systemd with proper isolation.
Appendix II: Resources
- Docker and the OCI container ecosystem - a trustworthy (it's LWN) overview/summary of the ecosystem.
- Yet Another Brief History of container(d) - from the old-day VMs, through Linux namespaces & cgroups, to LXC, then Docker, libcontainer, runc, and containerd.
- LXC and LXD: a different container story - Docker started as a UX layer on top of LXC, then moved away, but the story of LXC (and LXD) continued.
- A Comprehensive Container Runtime Comparison - surprisingly good overview by Capital One's Critical Stack.
- Using runc to explore the OCI Runtime Specification - this article starts with a concise but pretty good ecosystem overview.
- veggiemonk/awesome-docker - a curated list of [not only] Docker resources and projects.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox:
