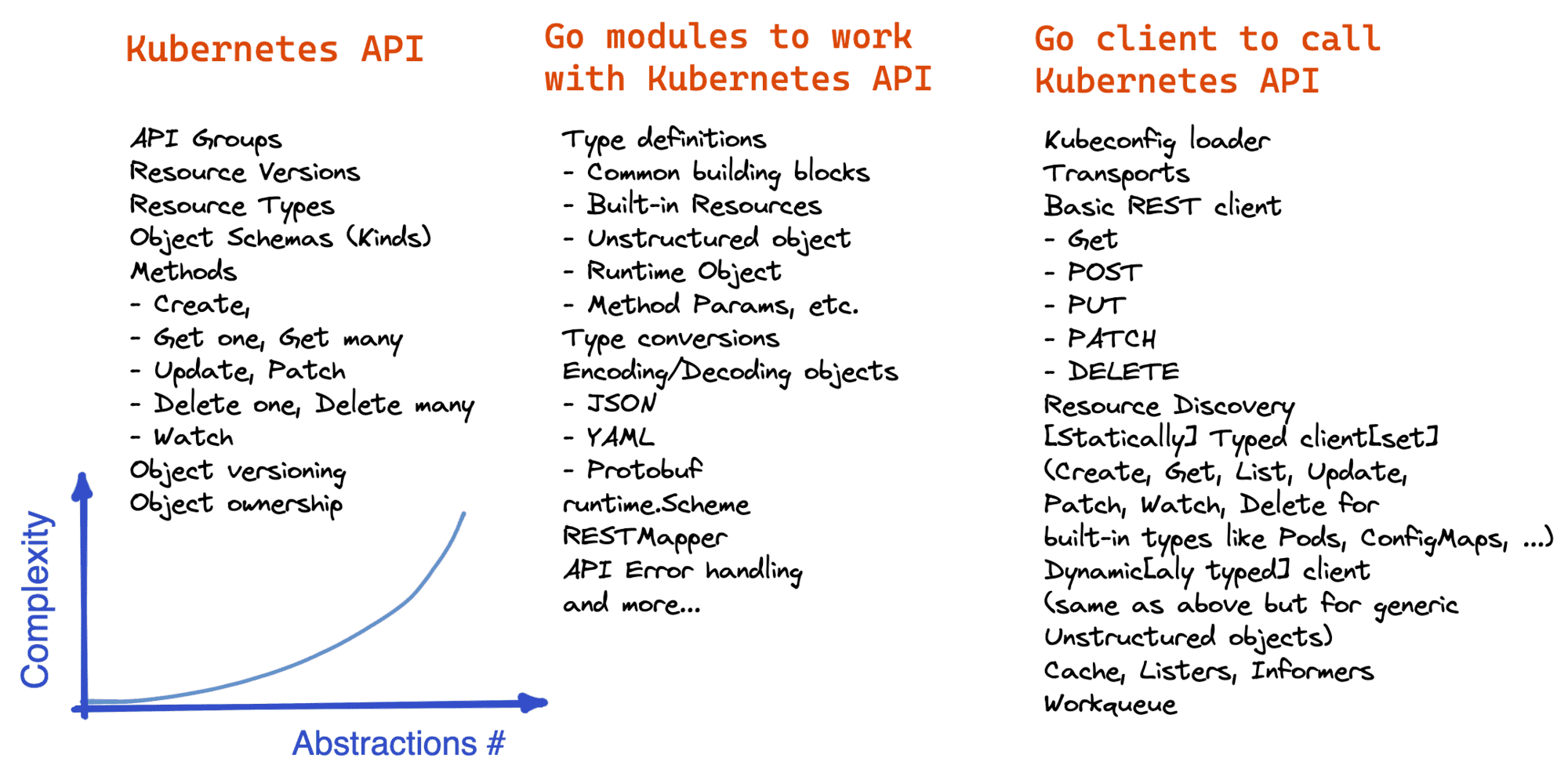
How To Extend Kubernetes API - Kubernetes vs. Django
There are many ways to extend Kubernetes with custom functionality, starting from writing kubectl plugins and ending with implementing scheduler extensions. The exhaustive list of extension points can be found in the official docs, but if there were a ranking based on the hype around the approach, I bet developing custom controllers or operators, if you will, would win.
The idea behind Kubernetes controllers is simple yet powerful - you describe the desired state of the system, persist it to Kubernetes, and then wait until controllers do their job and bring the actual state of the cluster close enough to the desired one (or report a failure).
However, while controllers get a lot of the press attention, in my opinion, writing custom controllers most of the time should be seen as just one (potentially optional) part of the broader task of extending the Kubernetes API. But to notice that, a decent familiarity with a typical workflow is required.