- Kubernetes API Basics - Resources, Kinds, and Objects
- How To Call Kubernetes API using Simple HTTP Client
- How To Call Kubernetes API from Go - Types and Common Machinery
- How To Extend Kubernetes API - Kubernetes vs. Django
- How To Develop Kubernetes CLIs Like a Pro
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
Disclaimer: Django is a general-purpose web framework, while Kubernetes is, well, a container orchestrator, if you will. Obviously, so different projects shouldn't be compared at all. However, in this series, I try to demystify Kubernetes and show that its API is a pretty much normal HTTP API and that it can be extended in rather familiar ways. Hence, the title. And no, below you won't find a true comparison of Kubernetes and Django, sorry :)
There are many ways to extend Kubernetes with custom functionality, starting from writing kubectl plugins and ending with implementing scheduler extensions. The exhaustive list of extension points can be found in the official docs, but if there were a ranking based on the hype around the approach, I bet developing custom controllers or operators, if you will, would win.
The idea behind Kubernetes controllers is simple yet powerful - you describe the desired state of the system, persist it to Kubernetes, and then wait until controllers do their job and bring the actual state of the cluster close enough to the desired one (or report a failure).
However, while controllers get a lot of the press attention, in my opinion, writing custom controllers most of the time should be seen as just one (potentially optional) part of the broader task of extending the Kubernetes API. But to notice that, a decent familiarity with a typical workflow is required.
Custom Controllers
While the Kubernetes community offers a broader and more generic definition of a controller, after more than a year of dealing with Kubernetes controllers in the wild, I've come up with the following explanation that covers the majority of the custom controllers I've seen so far:
- A controller is indeed an active reconciliation process (read: infinite loop) that reads the desired state and updates the actual state accordingly.
- However, a controller is typically bound to a single Kubernetes resource type. Let's call it the controller's primary resource.
- The controller listens to system events: most importantly, creation or modification of primary resource objects, but also changes in other (secondary or owned) resources, timer events, etc.
- Regardless of the nature of the event, it's always possible to attribute the event to one or more objects of the primary resource type.
- Upon the event, the controller reads (one by one) the corresponding primary resource objects from the API, examines their spec attributes (i.e., the desired state), tries to apply changes to the system to bring it closer to the desired state, and updates the objects back with the status of the attempt.
💡 A controller can have any resource type as its primary, including built-in resources like pods, jobs, or services. The problem is that most if not all built-in resources already have corresponding built-in controllers. So, often custom controllers are written for custom resources to avoid multiple controllers updating the status of a shared object.
But what, in essence, is a resource? In Kubernetes own words:
A resource is an endpoint in the Kubernetes API that stores a collection of API objects of a certain kind; for example, the built-in pods resource contains a collection of Pod objects.
Thus, if resources are merely Kubernetes API endpoints, writing a controller for a resource is just a fancy way to bind a request handler to an API endpoint! 🙈
The controller's logic will be triggered (well, in particular) whenever there is a creation or modification request to the primary resource endpoint. An instance of the primary resource type that triggered the control loop iteration serves as a data transfer object for the request parameters (object's spec field) and the response status (object's status field).
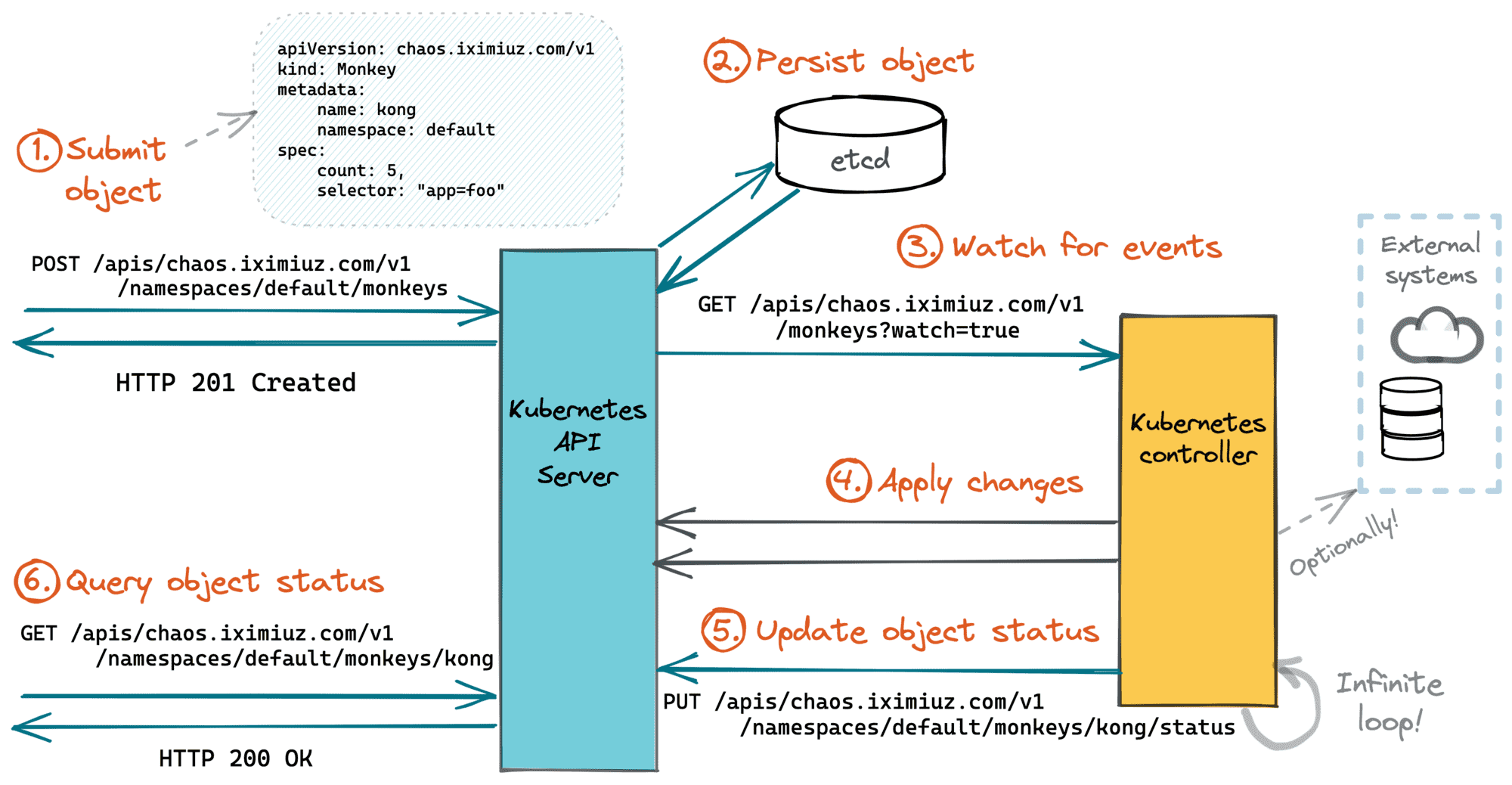
The main difference between controller-based handlers and more traditional request handlers is that the processing happens asynchronously to the actual API request. The API requests creating or modifying Kubernetes objects (e.g., POST, PUT, PATCH) just schedule the work for controllers (via recording the intent), and the API requests fetching the objects (GET, WATCH) are used to get back the processing status.
Custom Resources
If adding request handlers to the Kubernetes API happens through writing controllers, how adding new API endpoints is done?
Before answering this question, it's important to understand that there are two types of endpoints in the Kubernetes API:
- The first type is endpoints serving collections of Kubernetes objects (i.e., persistent Kubernetes entities) like Pods, ConfigMaps, Services, etc. The vast majority of the API endpoints belong to this type.
- The second type is, basically, everything else. Endpoints like
/metrics,/logs, or/apisare the most prominent examples of that other type of endpoints. Such endpoints are either baked into the Kubernetes API server or implemented using the API Aggregation Layer.
Are there some prominent examples when the Kubernetes API was extended using the Aggregation Layer?
— Ivan Velichko (@iximiuz) February 6, 2022
Or it's always Custom Resources paired with admission hooks and controllers?
Controllers typically work with the first type of endpoints. So, how a new endpoint serving a user-defined type of objects can be added to the API?
First, a CustomResourceDefinition (CRD) needs to be written. The CRD itself is an object that describes the new, custom resource. Most importantly, the CRD should contain the name and the versioned object schema (i.e., the fields) of the new resource type.
Click here for the hands-on part.
An example of a CustomResourceDefinition that registers a new resource monkeys serving objects of the new kind Monkey:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: monkeys.chaos.iximiuz.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: chaos.iximiuz.com
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: monkeys
# singular name to be used as an alias on the CLI and for display
singular: monkey
# kind is normally the PascalCased singular name of the schema
kind: Monkey
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
# Monkey objects will have just two properties: .count and .selector
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
count:
type: number
minimum: 1
selector:
type: string
maxLength: 1024
Applying the above snippet to a cluster and examining the updated list of the API endpoints gives the following:
$ kubectl get --raw / | jq .
{
"paths": [
...
"/apis/apps",
"/apis/apps/v1",
...
👉 "/apis/chaos.iximiuz.com",
👉 "/apis/chaos.iximiuz.com/v1",
...
"/apis/storage.k8s.io",
"/apis/storage.k8s.io/v1",
...
]
}
$ kubectl get --raw /apis/chaos.iximiuz.com/v1 | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "chaos.iximiuz.com/v1",
"resources": [
{
"name": "monkeys",
"singularName": "monkey",
"namespaced": true,
"kind": "Monkey",
"verbs": [
"delete",
"deletecollection",
"get",
"list",
"patch",
"create",
"update",
"watch"
],
"storageVersionHash": "OrLI4mAJgSw="
}
]
}
Then, the CRD needs to be submitted to the cluster. Applying a CRD to a cluster creates a new Kubernetes API endpoint serving a Custom Resource type. As simple as just that!
Objects of the custom resource type look and behave much like the built-in Kubernetes objects, they benefit from the common API features (CRUD, field validation, discovery, etc.), and at the same time, they have attributes required to solve your custom use case.
💡 A Custom resource can be useful on its own. - by registering a new resource, you immediately get (some limited) persistency, out-of-the-box field validation, RBAC, and more. However, most of the time, a custom resource is created to be accompanied by a custom controller.
Admission Webhooks
Getting back to the request handling...
The superpower of Kubernetes controllers is attributed to their asynchronous nature, but so is their greatest limitation. Requests to the Kubernetes API creating, modifying, or deleting objects work as a record of intent - the actual processing logic is deferred until the next control loop iteration. But what if synchronous request handling is required?
Well, it's also possible in Kubernetes! But for that, you'd need to intervene in the resource request processing by the Kubernetes API server.
Upon arrival to the API server, a request passes through the following stages before the change is persisted in etcd (or alike):
- Authentication & Authorization
- Mutating Admission
- Object Schema Validation
- Validating Admission.
And most (or all?) of the above stages can be extended with custom logic!
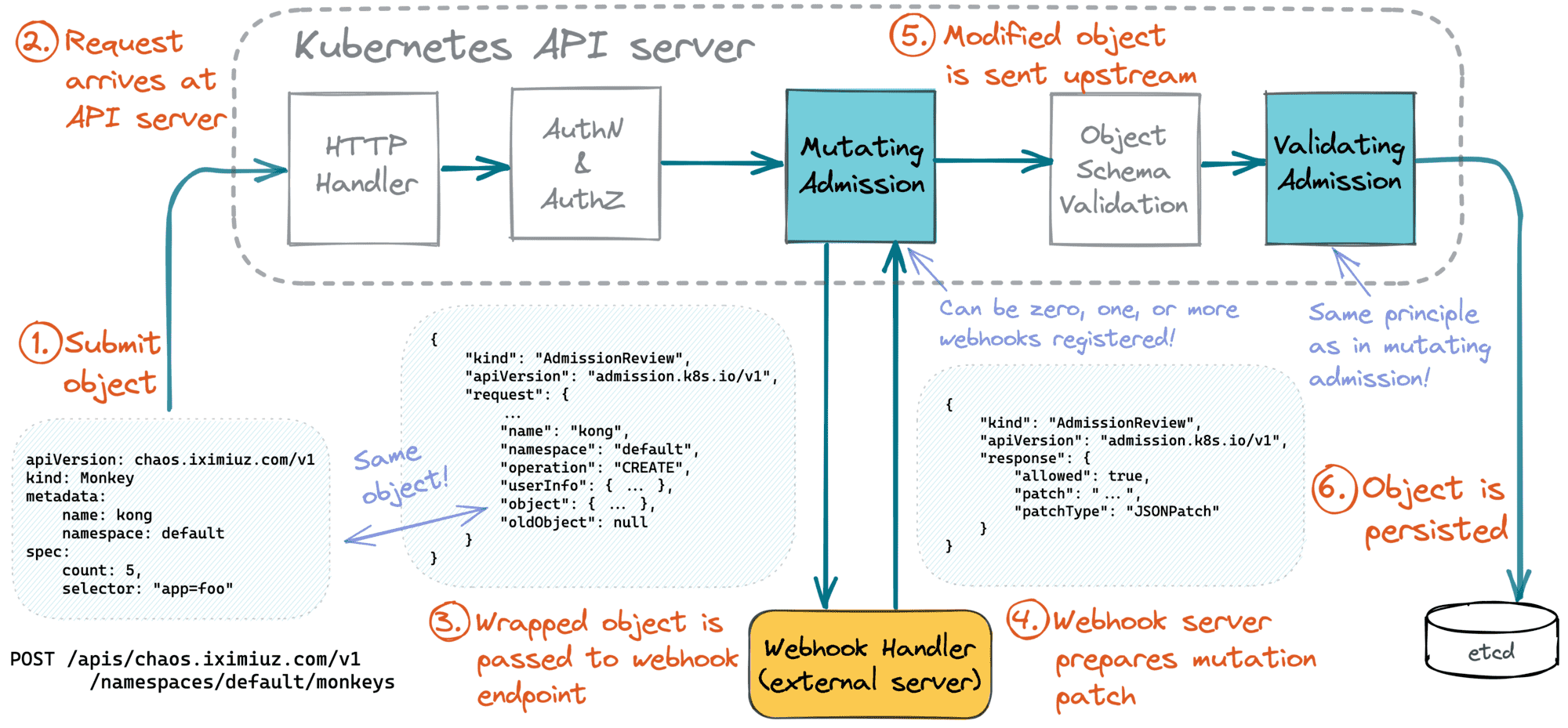
Thus, configuring an admission webhook will make the Kubernetes API server send the resource instance (wrapped into an envelope called AdmissionReview) to a custom HTTPS endpoint before actually persisting it.
Click here for the hands-on part.
Registering an admission webhook is as simple as just applying the following manifest:
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: my-validating-webhook-config
webhooks:
- name: my-validating-webhook-1
admissionReviewVersions:
- v1
# what endpoint to call
clientConfig:
# either a Kubernetes service
service:
name: my-webhook-service
namespace: my-namespace
path: /validate-monkey
# ...or a regular URL (beware, it must use HTTPS)
url: https://my-webhook-service.org/validate-monkey
rules:
# what API resource to react on
- apiGroups:
- /apis/chaos.iximiuz.com
apiVersions:
- v1
resources:
- monkeys
# what operations on the resource to react on
operations:
- CREATE
- UPDATE
sideEffects: None # Sweet!
In the above example, every POST/PUT request to the /apis/chaos.iximiuz.com/v1 endpoint will trigger a blocking side-request to the validation endpoint hosted wherever you want and doing whatever you want with the passed Monkey object. And by replacing ValidatingWebhookConfiguration with MutatingWebhookConfiguration, you can even mutate the objects before persisting.
Calling an admission webhook endpoint blocks the request processing by the Kubernetes API server. The implementation of the admission webhook can perform arbitrary validation logic, populate object's attributes with non-trivial defaults, label or annotate the object, or even modify other Kubernetes resources or make changes to external systems!
⚠️ In general, side-effects in webhook handlers should be avoided. In a webhook, it's impossible to know whether the object will actually be persisted or rejected by the processing chain. If the action on the resource is rejected by one of the checks, any changes made by the preceding steps will need to be somehow reverted.
Thus, webhooks is an easy way to bind synchronous request handlers to Kubernetes API endpoints. And this completes the feature parity of the Kubernetes API with any other traditional HTTP API 🎉
Summarizing
Let's try to put everything on one diagram. Here is how a more or less comprehensive Kubernetes API extension workflow can be depicted:
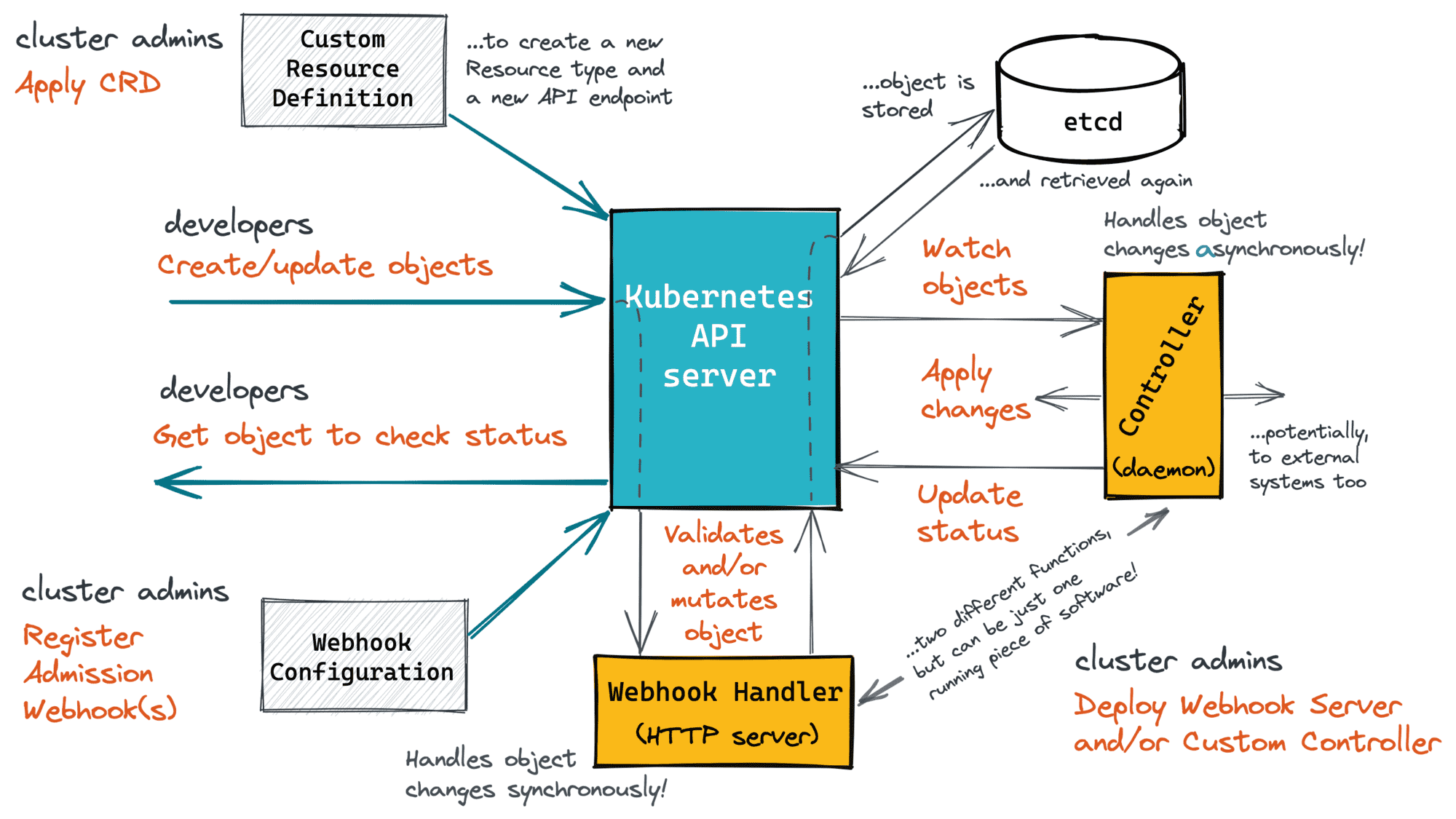
Hopefully, it's clear now that custom controllers is just one part of the bigger task of extending the Kubernetes API.
I hope, following the above explanation you've also noticed how Kubernetes is no different from good old tech we're all familiar with:
- Kubernetes Custom Resources is just a way to add new HTTP endpoints to the API.
- Kubernetes Custom Controllers is a way to bind asynchronous handlers to API endpoints.
- Kubernetes Admission Webhooks is a way to bind synchronous handlers to the same API endpoints.
So, Kubernetes is not so much different from Django, folks! 🙈
Seriously, though, drawing analogy with the familiar stuff generally helps me understand the new concepts faster. But when just understanding is not enough and fluency is required, practice is what usually helps me to internalize the concepts for real. However, this is a topic for another write-up. Stay tuned!
Resources
- Kubernetes API Basics - Resources, Kinds, and Objects
- How To Call Kubernetes API using Simple HTTP Client
- How To Call Kubernetes API from Go - Types and Common Machinery
- How To Extend Kubernetes API - Kubernetes vs. Django
- How To Develop Kubernetes CLIs Like a Pro
Don't miss new posts in the series! Subscribe to the blog updates and get deep technical write-ups on Cloud Native topics direct into your inbox.
