Table of contents
Foreword
Writable streams are an abstraction for a destination to which data is written... And this time it's a concise abstraction! Compared to vague readable streams (multiple operation modes behind single abstraction) writable streams implement only one mode and hence expose only one essential method write(chunk). Nevertheless, the idea of writable streams is not trivial and it's due to one nice feature it provides - backpressure. Let's try to wrap our mind around writable stream abstraction.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
Producer–consumer problem
Imagine we have two bound processes. The first process produces data (eg. reads data from a network or generates prime numbers, etc.) and the second process consumes it (eg. dumps data to a file). If we take a look at some moving time window over such pipeline we might observe 4 different situations:
- Producing is slower than consuming.
- Producing is as fast as consuming.
- Producing is faster than consuming.
- A mix of the options from above.
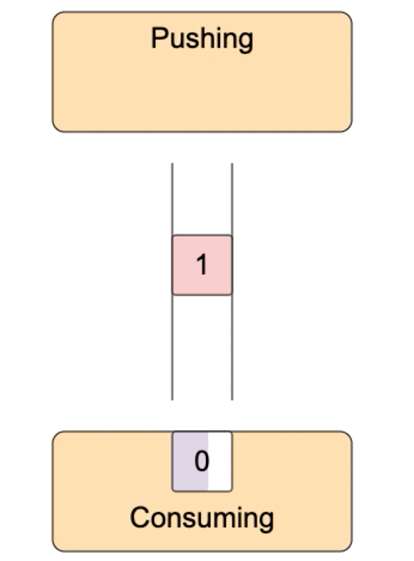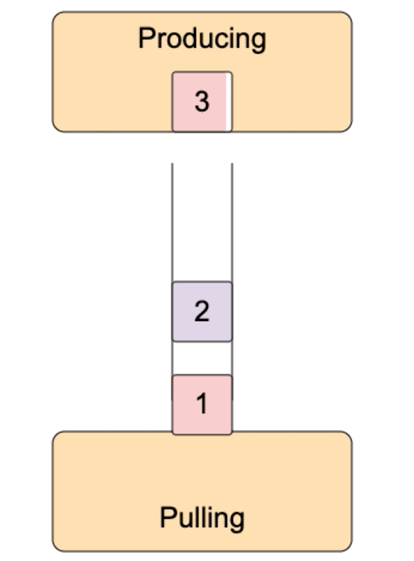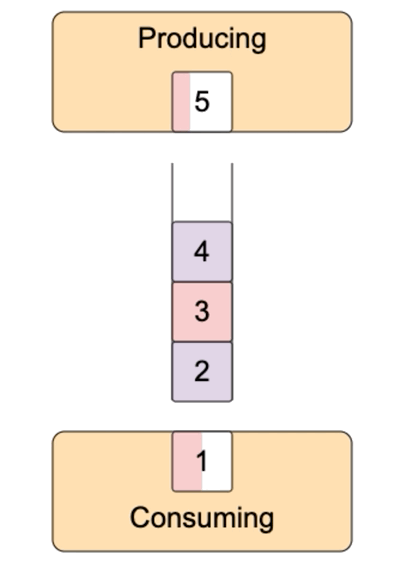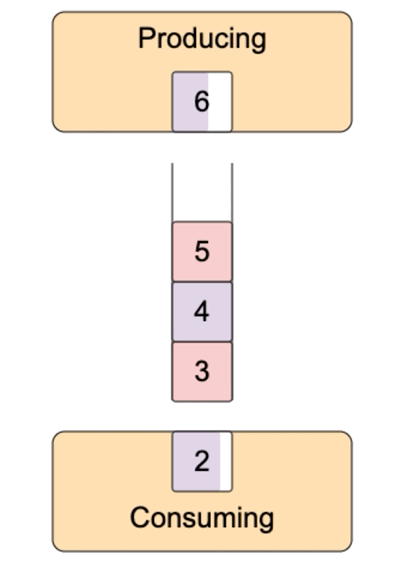
To organize the pipeline we need a buffer in between such processes. I.e. a spot in memory the data would be written to by the producer and later on would be read from by the consumer. If the producer is no faster than the consumer, we would need to prevent consumer's attempts to read from the empty buffer, i.e. pause the consumer once the buffer is empty. If the consumer is no faster than the producer we would need to prevent buffer overflow, i.e. pause the producer every time the buffer is full. The described situation is a classical producer-consumer problem.
The model below tries to visualize all the major cases.
[see sources on github]
Writable stream solution
It turns out that Node.js writable streams are just such consumers with built-in buffers. I.e. a writable stream is a process consuming data from its FIFO queue. Writable streams also provide mechanisms to notify the producing counterpart about both - the buffer overflow and the buffer got some spare space situations.
Right after the creation, the writable stream is idling. Once the first chunk is added to its queue, the writing process is resumed and the internal abstract _write(chunk, encoding, callback) method is called. Once the implementation of the _write() method calls the provided callback indicating that the chunk is consumed, the writing process repeats its consumption loop. However, if the buffer is empty the process starts idling again.
The size of the buffer is specified by the highWaterMark option. When the client code (i.e. the producing part) writes a chunk to the writable stream, method write(chunk) returns a hint about the state of the internal buffer. When after the writing some free space still remains, the returning value must be true indicating the client is free to write one more time. However, if the buffer is full after the current write() invocation, the returning value must be false indicating the need for backpressure. For better or worse, the returning value of the write() method is advisory. If the producer doesn't (or can't) respect it, the writable stream will continue buffering chunks, but this might lead to memory overconsumption.
If the producer got false from write(chunk) it experiences backpressure, i.e it should pause itself. However, we need a way to resume it as soon as there is free space in the consumer's buffer. For this purpose, the writable stream emits 'drain' event every time it pulls data from the overflowing internal buffer (see the visualization above). The producer should resume writing to the writable stream after receiving 'drain' event.
Stream pipes
While it's possible to use writable streams on them own, the most powerful way is to use them in conjunction with readable streams. Pipe-ing of a readable stream to a writable stream is basically a way to gracefully hide all the integration details (and some error handling) behind a single method call. When one pipes a readable stream to a writable:
- The writable subscribes to
'data'event leading the readable to start emitting data. - The readable binds its
resume()method (not completely true) to the'drain'event. - When on
'data'the readable receivesfalsefromwrite(chunk)method it pauses itself. - As soon as there is a free space in the buffer, the writable emits
'drain'leading to resuming of the readable.
Conclusion
We can see that during piping a readable stream operates in the flowing mode. As we already know it means that no internal buffering on the readable side is happening. Hence, the writable stream is doing all the heavy lifting in the implementation of the producer-consumer pipeline.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox:
