Disclaimer: I wrote this tutorial because gevent saved our project a few years ago and I still see steady gevent-related search traffic on my blog. So, the way gevent helped us may be useful for somebody else as well. Since I still have some handy knowledge I decided to make this note on how to set up things. However, I'd not advise starting a new project in 2020 using this technology. IMHO, it's aging and losing the traction.
TL;DR: check out code samples on GitHub.
Python is booming and Flask is a pretty popular web-framework nowadays. Probably, quite some new projects are being started in Flask. But people should be aware, it's synchronous by design and ASGI is not a thing yet. So, if someday you realize that your project really needs asynchronous I/O but you already have a considerable codebase on top of Flask, this tutorial is for you. The charming gevent library will enable you to keep using Flask while start benefiting from all the I/O being asynchronous. In the tutorial we will see:
- How to monkey patch a Flask app to make it asynchronous w/o changing its code.
- How to run the patched application using gevent.pywsgi application server.
- How to run the patched application using Gunicorn application server.
- How to run the patched application using uWSGI application server.
- How to configure Nginx proxy in front of the application server.
- [Bonus] How to use psycopg2 with psycogreen to make PostgreSQL access non-blocking.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
When do I need asynchronous I/O
The answer is somewhat naive - you need it when the application's workload is I/O bound, i.e. it maxes out on latency SLI due to over-communicating to external services. It's a pretty common situation nowadays due to the enormous spread of microservice architectures and various 3rd-party APIs. If an average HTTP handler in your application needs to make 10+ network requests to build a response, it's highly likely that you will benefit from asynchronous I/O. On the other hand, if your application consumes 100% of CPU or RAM handling requests, migrating to asynchronous I/O probably will not help.
What is gevent
From the official site description:
gevent is a coroutine-based Python networking library that uses greenlet to provide a high-level synchronous API on top of the libev or libuv event loop.
The description is rather obscure for those who are unfamiliar with the mentioned dependencies like greenlet, libev, or libuv. You can check out my previous attempt to briefly explain the nature of this library, but among other things it allows you to monkey patch normal-looking Python code and make the underlying I/O happening asynchronously. The patching introduces what's called cooperative multitasking into the Python standard library and some 3rd-party modules but the change stays almost completely hidden from the application and the existing code keeps its synchronous-alike outlook while gains the ability to serve requests asynchronously. There is an obvious downside of this approach - the patching doesn't change the way every single HTTP request is being served, i.e. the I/O within each HTTP handler still happens sequentially, even though it becomes asynchronous. Well, we can start using something similar to asyncio.gather() and parallelize some requests to external resources, but it would require the modification of the existing application code. However, now we can easily scale up the limit of concurrent HTTP requests for our application. After the patching, we don't need a dedicated thread (or process) per request anymore. Instead, each request handling now happens in a lightweight green thread. Thus, the application can serve tens of thousands of concurrent requests, probably increasing this number by 1-2 orders of magnitude from the previous limit.
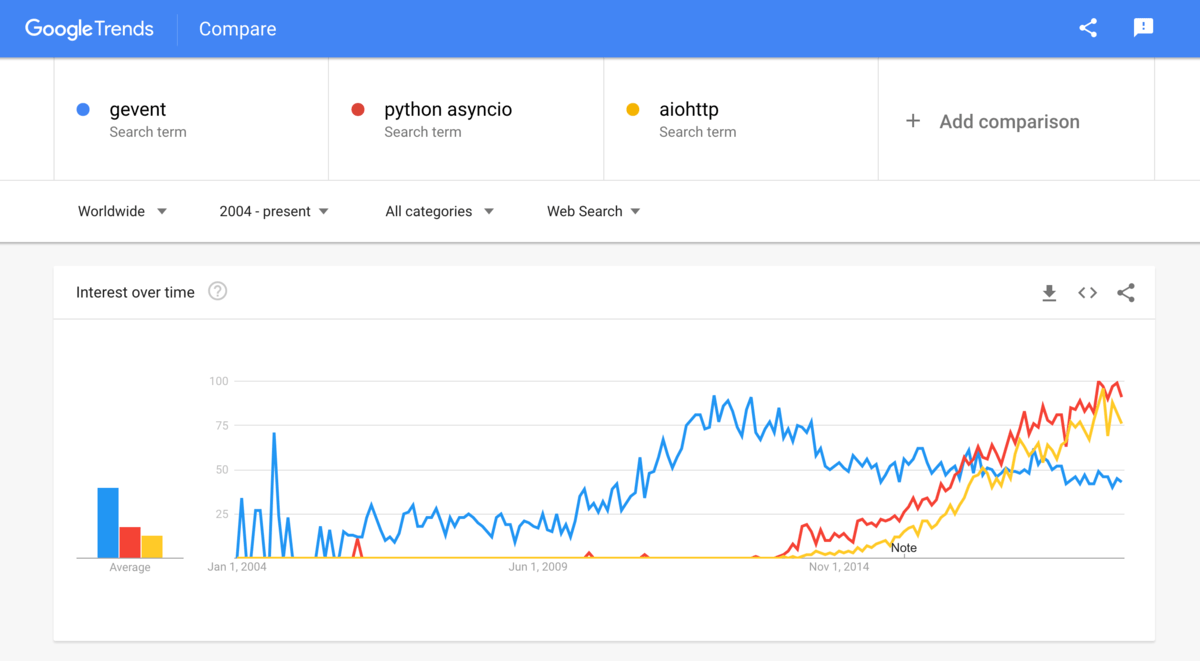
However, while the description sounds extremely promising (at least to me), the project and the surrounding eco-system is steadily losing traction (in favor of asyncio and aiohttp?):
Create simple Flask application
The standard tutorial format always seemed boring to me. Instead, we will try to make a tiny playground here. We will try to create a simple Flask application dependant on a sleepy 3rd party API endpoint. The only route of our application will be responding with some hard-coded string concatenated with the API response text. Having such a workload, we will play with different methods of achieving high concurrency in the Flask's handling of HTTP requests.
First, we need to emulate a slow 3rd party API. We will use aiohttp to implement it because it's based on the asyncio library and provides high concurrency for I/O-bound HTTP requests handling out of the box:
# ./slow_api/api.py
import os
import asyncio
from aiohttp import web
async def handle(request):
delay = float(request.query.get('delay') or 1)
await asyncio.sleep(delay)
return web.Response(text='slow api response')
app = web.Application()
app.add_routes([web.get('/', handle)])
if __name__ == '__main__':
web.run_app(app, port=os.environ['PORT'])
We can launch it in the following Docker container:
# ./slow_api/Dockerfile
FROM python:3.8
RUN pip install aiohttp
COPY api.py /api.py
CMD ["python", "/api.py"]
Now, it's time to create the target Flask application:
# ./flask_app/app.py
import os
import requests
from flask import Flask, request
api_port = os.environ['PORT_API']
api_url = f'http://slow_api:{api_port}/'
app = Flask(__name__)
@app.route('/')
def index():
delay = float(request.args.get('delay') or 1)
resp = requests.get(f'{api_url}?delay={delay}')
return 'Hi there! ' + resp.text
As promised, it's fairly simple.
Deploy Flask application using Flask dev server
The easiest way to run a Flask application is to use a built-in development server. But even this beast supports two modes of request handling.
In the single-threaded mode, a Flask application can handle no more than one HTTP request at a time. I.e. the request handling becomes sequential.
Sharing personal experience 🤦
This mode can be dangerous. If an application needs to send a request to itself it may get stuck in a deadlock.
In the multi-threaded mode, Flask spawns a thread for every incoming HTTP request. The maximal concurrency, i.e. the highest possible number of simultaneous threads doesn't seem configurable though.
We will use the following Dockerfile to run the Flask dev server:
# ./flask_app/Dockerfile-devserver
FROM python:3.8
RUN pip install Flask requests
COPY app.py /app.py
ENV FLASK_APP=app
CMD flask run --no-reload \
--$THREADS-threads \
--host 0.0.0.0 --port $PORT_APP
Let's spin up the first playground using handy Docker Compose:
# ./sync-devserver.yml
version: "3.7"
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-devserver
environment:
- PORT_APP=3000
- PORT_API=4000
- THREADS=without
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
flask_app_threaded: # extends: flask_app
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-devserver
environment:
- PORT_APP=3001
- PORT_API=4000
- THREADS=with
ports:
- "127.0.0.1:3001:3001"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
After running docker-compose build and docker-compose up we will have two instances of our application running. The single-threaded version is bound to the host's 127.0.0.1:3000, the multi-threaded - to 127.0.0.1:3001.
# Build and start app served by Flask dev server
$ docker-compose -f sync-devserver.yml build
$ docker-compose -f sync-devserver.yml up
It's time to serve the first portion of HTTP requests (using lovely ApacheBench). We will start from the single-threaded version and only 10 requests:
# Test single-threaded deployment
$ ab -r -n 10 -c 5 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 5
> Time taken for tests: 10.139 seconds
> Complete requests: 10
> Failed requests: 0
> Requests per second: 0.99 [#/sec] (mean)
As expected, we observed no concurrency. Even though we asked ab to simulate 5 simultaneous clients using -c 5, it took ~10 seconds to finish the scenario with an effective request rate close to 1 per second.
If you execute top -H in the server container to check the number of running threads, the picture will be similar to this:
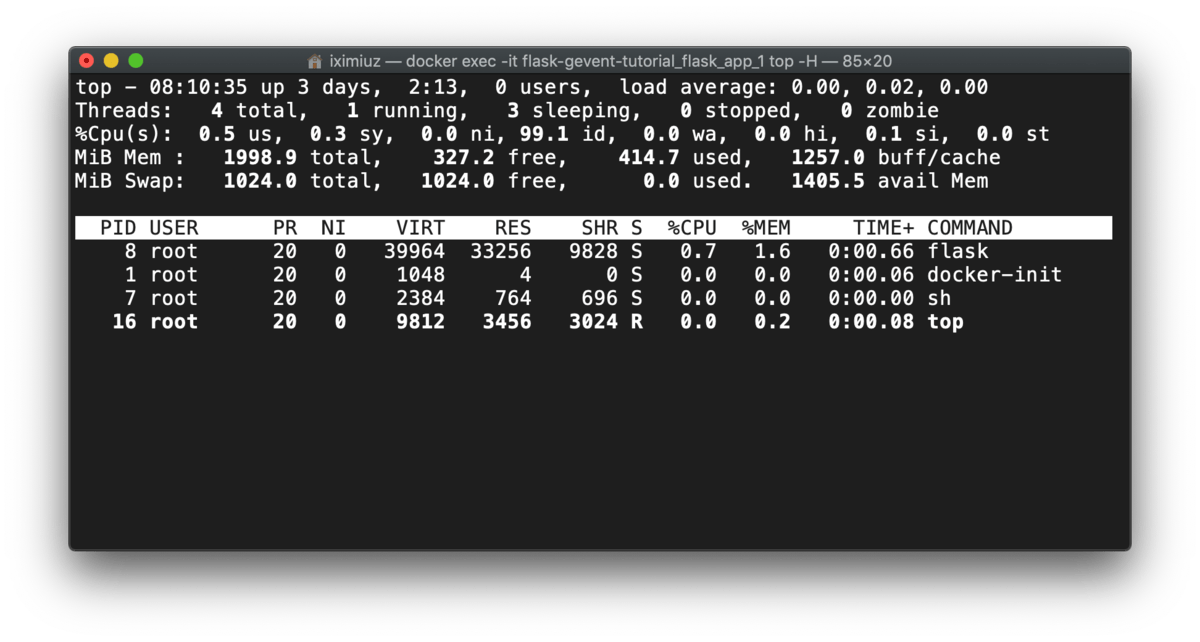
docker exec -it flask-gevent-tutorial_flask_app_1 top -H
Let's proceed to the multi-threaded version alongside with increasing the payload up to 2000 requests being produced by 200 simultaneous clients:
# Test multi-threaded deployment
$ ab -r -n 2000 -c 200 http://127.0.0.1:3001/?delay=1
> Concurrency Level: 200
> Time taken for tests: 16.040 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 124.69 [#/sec] (mean)
The effective concurrency grew to the mean of 124 requests per second, but a sample from top -H shows, that at some point of time we had 192 threads and 190 of them were sleeping:
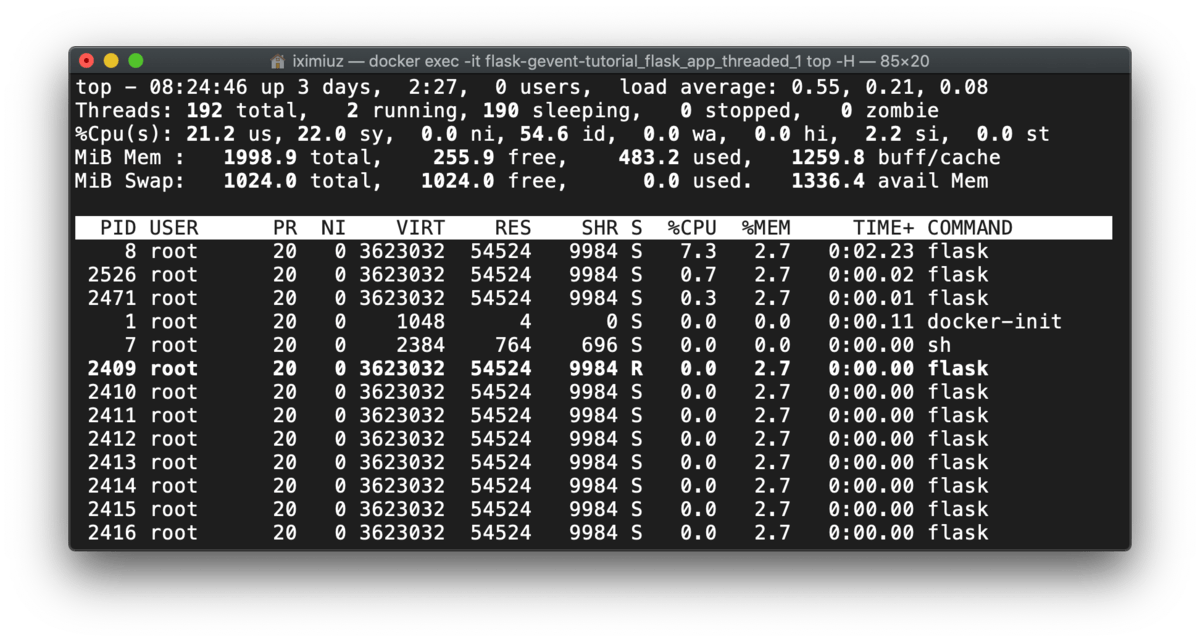
docker exec -it flask-gevent-tutorial_flask_app_threaded_1 top -H
Deploy Flask application using gevent.pywsgi
The fastest way to unleash the power of gevent is to use its built-in WSGI-server called gevent.pywsgi.
We need to create an entrypoint:
# ./flask_app/pywsgi.py
from gevent import monkey
monkey.patch_all()
import os
from gevent.pywsgi import WSGIServer
from app import app
http_server = WSGIServer(('0.0.0.0', int(os.environ['PORT_APP'])), app)
http_server.serve_forever()
Notice, how it patches our Flask application. Without monkey.patch_all() there would be no benefit from using gevent here because all the I/O in the application stayed synchronous.
The following Dockerfile can be used to run the pywsgi server:
# ./flask_app/Dockerfile-gevent-pywsgi
FROM python:3.8
RUN pip install Flask requests gevent
COPY app.py /app.py
COPY pywsgi.py /pywsgi.py
CMD python /pywsgi.py
Finally, let's prepare the following playground:
# ./async-gevent-pywsgi.yml
version: "3.7"
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-pywsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- THREADS=without
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
And launch it using:
# Build and start app served by gevent.pywsgi
$ docker-compose -f async-gevent-pywsgi.yml build
$ docker-compose -f async-gevent-pywsgi.yml up
We expect a decent concurrency level with very few threads (if any) in the server container:
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 200
> Time taken for tests: 17.536 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 114.05 [#/sec] (mean)
Executing top -H shows that we DO have some python threads (around 10). Seems like gevent employs a thread pool to implement the asynchronous I/O:
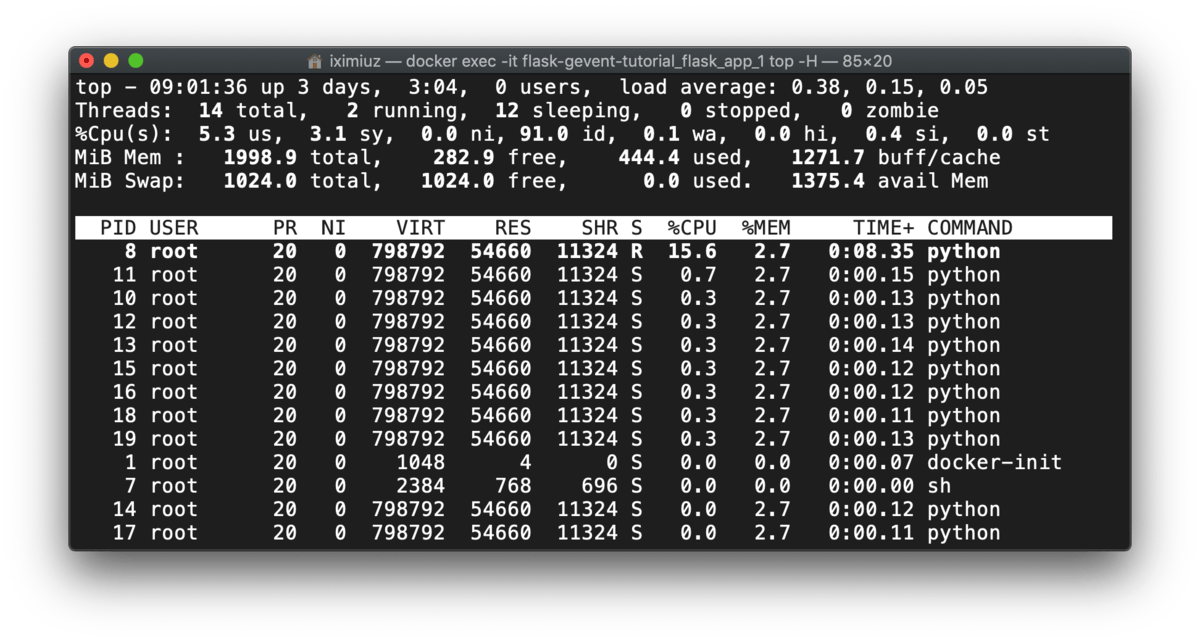
docker exec -it flask-gevent-tutorial_flask_app_1 top -H
Deploy Flask application using Gunicorn
Gunicorn is one of the recommended ways to run Flask applications. We will start from Gunicorn because it has slightly fewer parameters to configure before going than uWSGI.
Gunicorn uses the worker process model to serve HTTP requests. But there are multiple types of workers: synchronous, asynchronous, tornado workers, and asyncio workers.
In this tutorial, we will cover only the first two types - synchronous and gevent-based asynchronous workers. Let's start from the synchronous model:
# ./flask_app/Dockerfile-gunicorn
FROM python:3.8
RUN pip install Flask requests gunicorn
COPY app.py /app.py
CMD gunicorn --workers $WORKERS \
--threads $THREADS \
--bind 0.0.0.0:$PORT_APP \
app:app
Notice that we reuse the original app.py entrypoint without any changes. The synchronous Gunicorn playground looks as follows:
# ./sync-gunicorn.yml
version: "3.7"
services:
flask_app_gunicorn:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gunicorn
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=4
- THREADS=50
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
Let's build and start the server using 4 workers x 50 threads each (i.e. 200 threads in total):
# Build and start app served by Gunicorn
$ docker-compose -f sync-gunicorn.yml build
$ docker-compose -f sync-gunicorn.yml up
Obviously, we expect a high number of requests being served concurrently:
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 200
> Time taken for tests: 13.427 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 148.95 [#/sec] (mean)
But if we compare the samples from top -H before and after the test, we can notice an interesting detail:
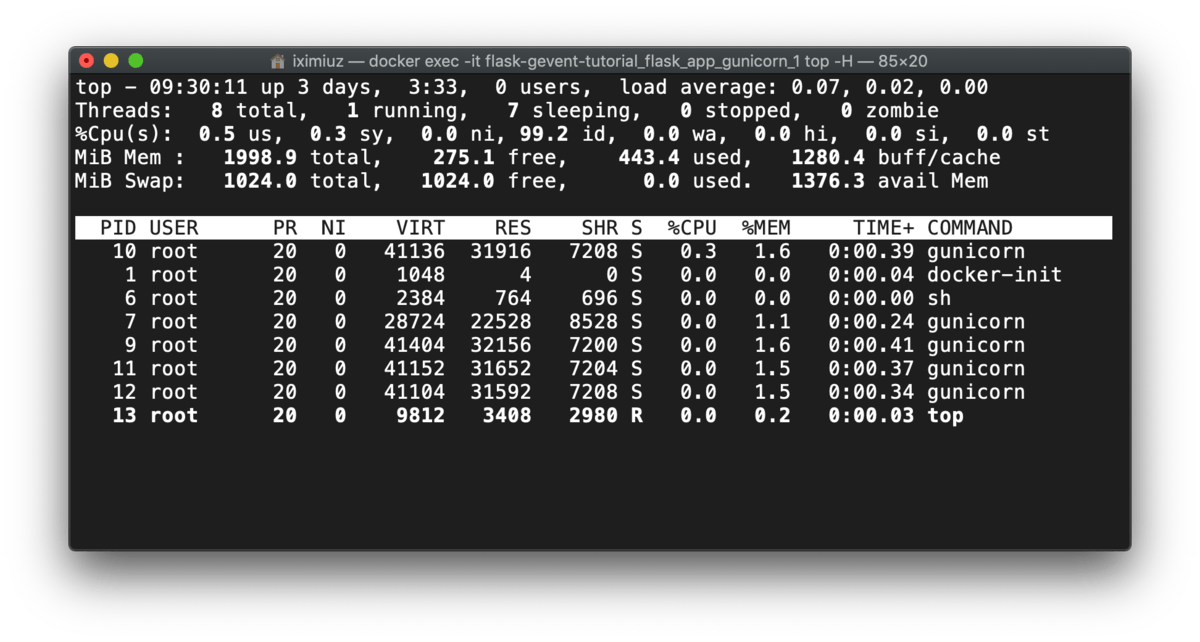
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (before test)
Gunicorn starts workers on the startup, but the workers spawn the threads on-demand:
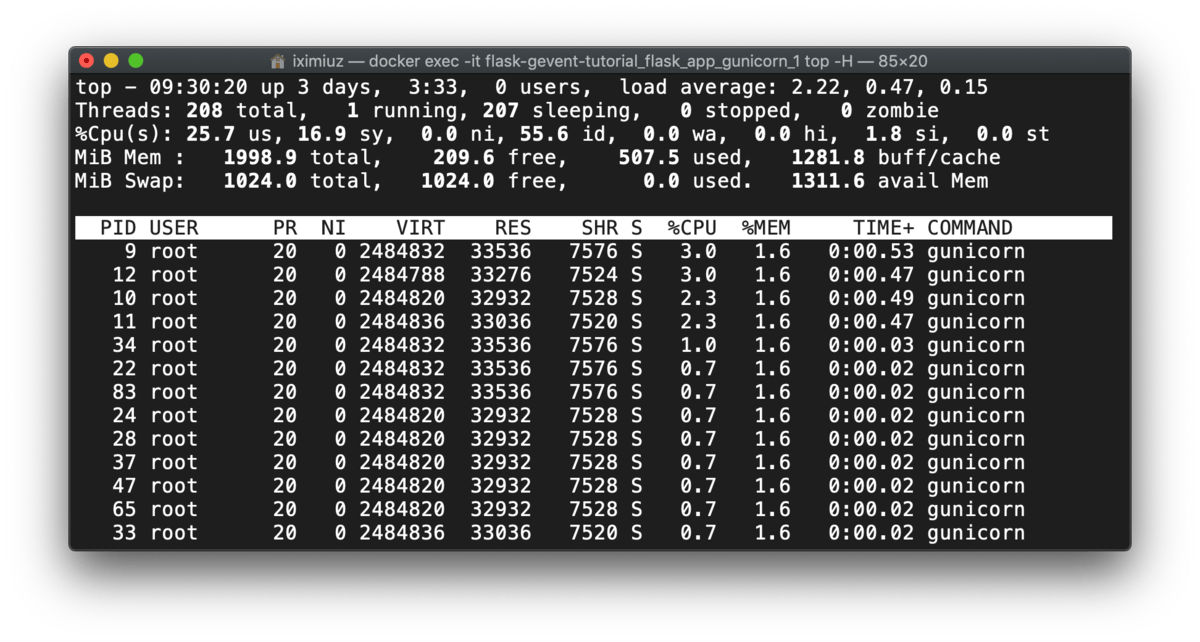
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (during test)
Now, let's switch to gevent workers. For this setup we need to make a new entrypoint to apply the monkey patching:
# ./flask_app/patched.py
from gevent import monkey
monkey.patch_all() # we need to patch very early
from app import app # re-export
The Dockerfile to run Gunicorn + gevent:
# ./flask_app/Dockerfile-gevent-gunicorn
FROM python:3.8
RUN pip install Flask requests gunicorn gevent
COPY app.py /app.py
COPY patched.py /patched.py
CMD gunicorn --worker-class gevent \
--workers $WORKERS \
--bind 0.0.0.0:$PORT_APP \
patched:app
# ./async-gevent-gunicorn.yml
version: "3.7"
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-gunicorn
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=1
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
Let's start it:
# Build and start app served by Gunicorn + gevent
$ docker-compose -f async-gevent-gunicorn.yml build
$ docker-compose -f async-gevent-gunicorn.yml up
And conduct the test:
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 200
> Time taken for tests: 17.839 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 112.11 [#/sec] (mean)
We observe similar behavior - only worker processes are alive before the test:
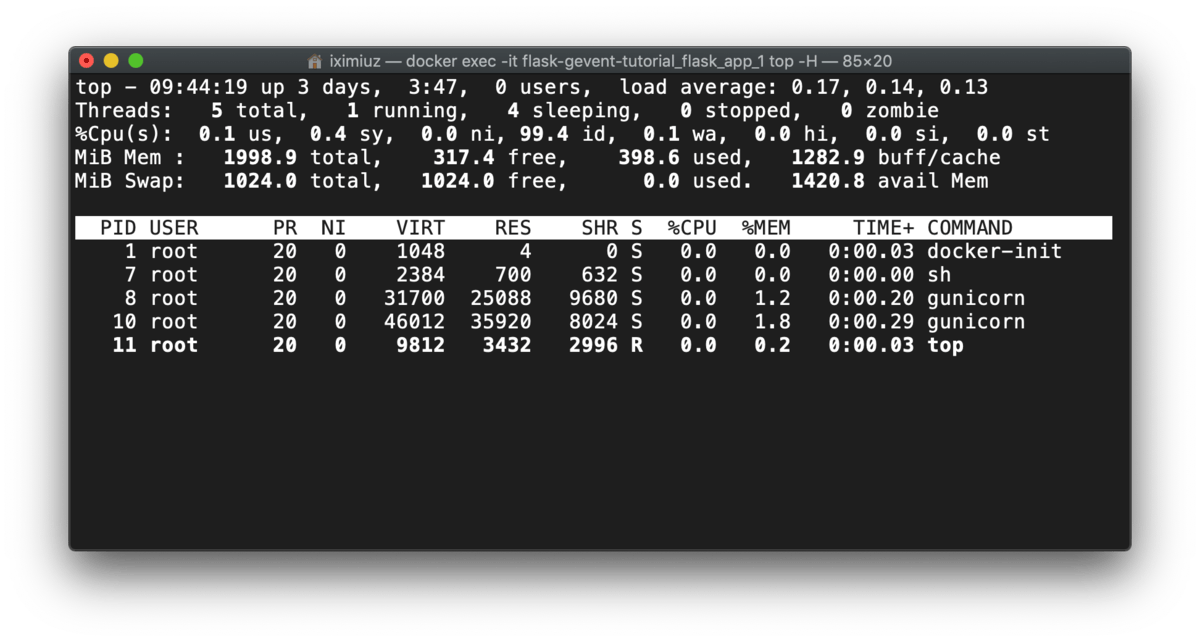
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (before test)
But during the test, we see 10 new threads spawned. Notice, how it resembles the number of threads used by pywsgi:
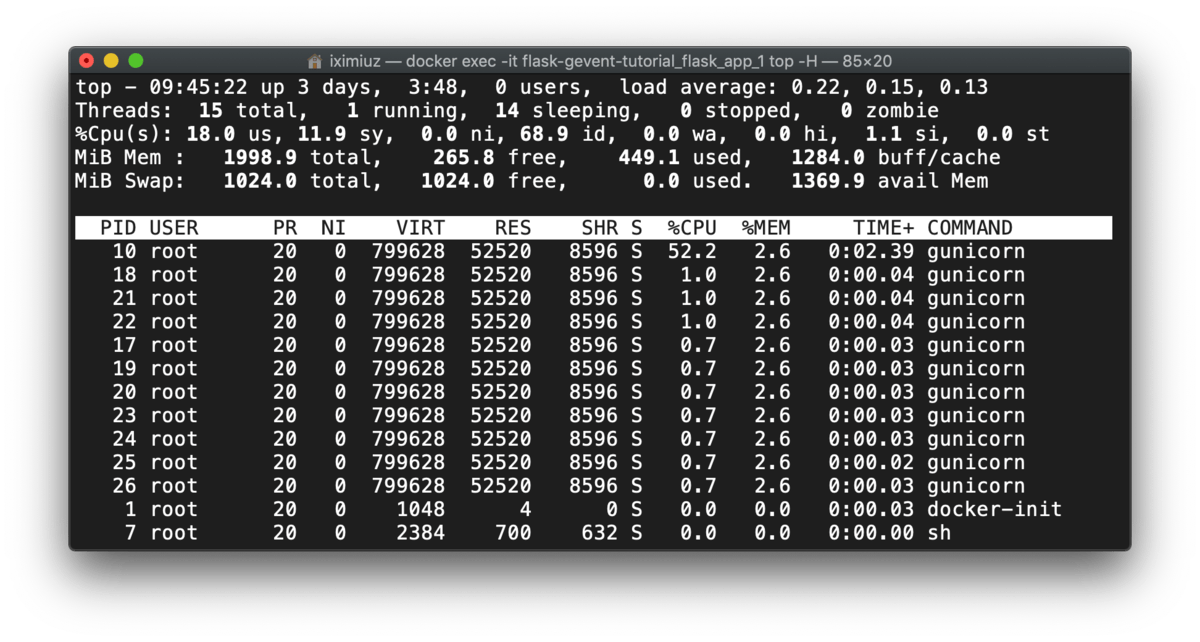
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (during test)
Deploy Flask application using uWSGI
uWSGI is a production-grade application server written in C. It's very fast and supports different execution models. Here we will again compare only two modes: synchronous (N worker processes x K threads each) and gevent-based (N worker processes x M async cores each).
First, the synchronous setup:
# ./flask_app/Dockerfile-uwsgi
FROM python:3.8
RUN pip install Flask requests uwsgi
COPY app.py /app.py
CMD uwsgi --master \
--workers $WORKERS \
--threads $THREADS \
--protocol $PROTOCOL \
--socket 0.0.0.0:$PORT_APP \
--module app:app
We use an extra parameters --protocol and the playground sets it to http:
# ./sync-uwsgi.yml
version: "3.7"
services:
flask_app_uwsgi:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-uwsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=4
- THREADS=50
- PROTOCOL=http
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
We again limit the concurrency by 200 simultaneous HTTP requests (4 workers x 50 threads each):
# Build and start app served by uWSGI
$ docker-compose -f sync-uwsgi.yml build
$ docker-compose -f sync-uwsgi.yml up
Let's send a bunch of HTTP requests:
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 200
> Time taken for tests: 12.685 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 157.67 [#/sec] (mean)
uWSGI spaws workers and threads beforehand:
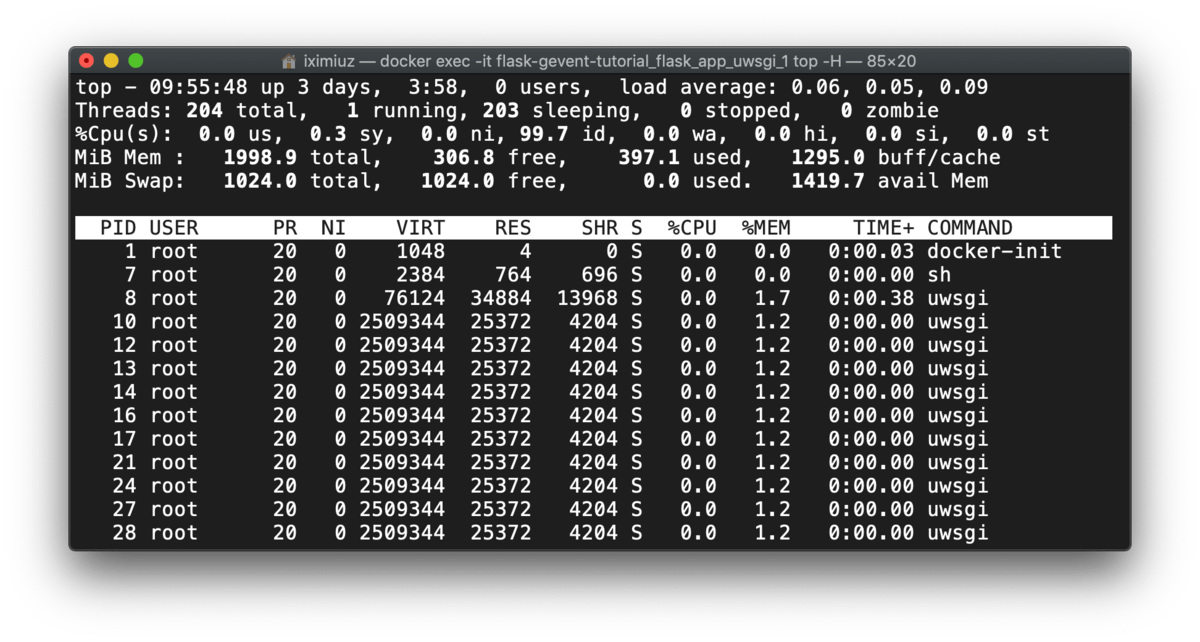
docker exec -it flask-gevent-tutorial_flask_app_uwsgi_1 top -H (before test)
So, only the load changes during the test:
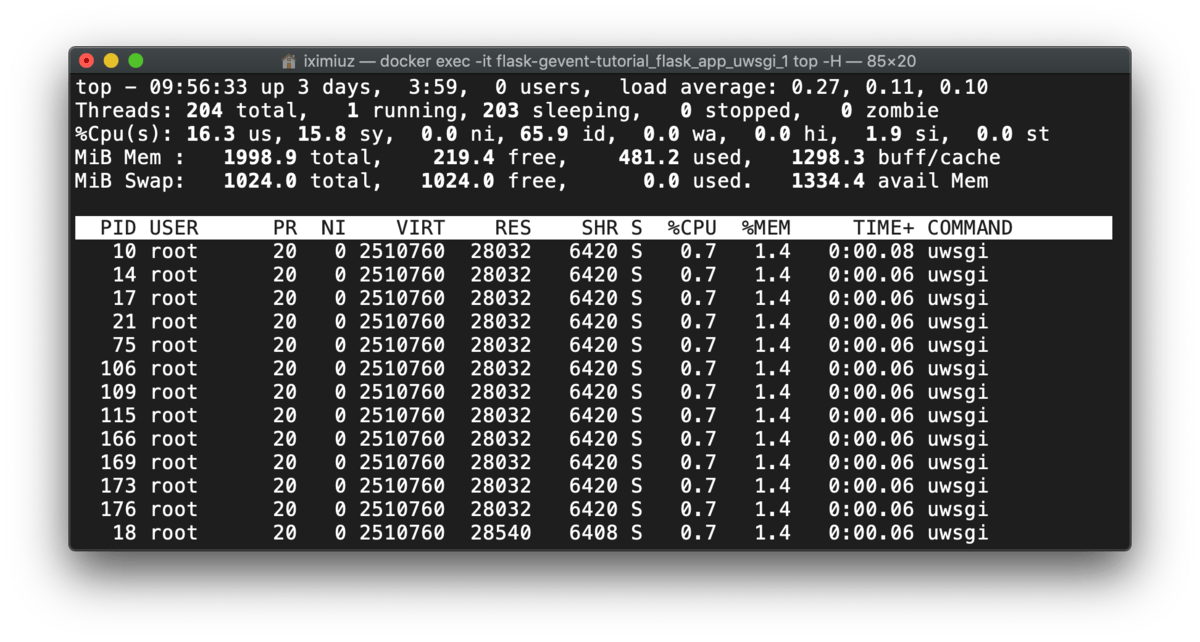
docker exec -it flask-gevent-tutorial_flask_app_uwsgi_1 top -H (during test)
Let's proceed to the gevent mode. We can reuse the patched.py entrypoint from the Gunicorn+gevent scenario:
# ./flask_app/Dockerfile-gevent-uwsgi
FROM python:3.8
RUN pip install Flask requests uwsgi gevent
COPY app.py /app.py
COPY patched.py /patched.py
CMD uwsgi --master \
--single-interpreter \
--workers $WORKERS \
--gevent $ASYNC_CORES \
--protocol $PROTOCOL \
--socket 0.0.0.0:$PORT_APP \
--module patched:app
One extra parameter the playground sets here is the number of async cores used by gevent:
# ./async-gevent-uwsgi.yml
version: "3.7"
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-uwsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=2
- ASYNC_CORES=2000
- PROTOCOL=http
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
Let's start the uWSGI+gevent server:
# Build and start app served by uWSGI + gevent
$ docker-compose -f async-gevent-uwsgi.yml build
$ docker-compose -f async-gevent-uwsgi.yml up
And do the test:
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
> Time taken for tests: 13.164 seconds
> Complete requests: 2000
> Failed requests: 0
> Requests per second: 151.93 [#/sec] (mean)
However, if we check the number of workers before and during the test we will notice a discrepancy with the previous method:
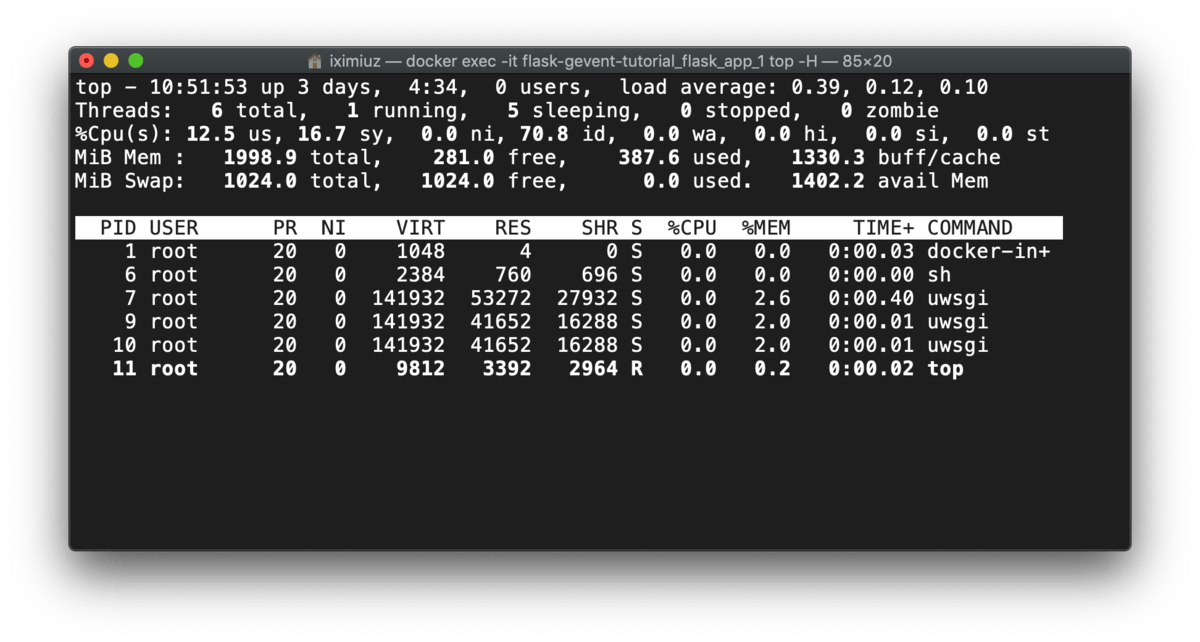
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (before test)
Before the test, uWSGI had the master and worker processes only, but during the test, threads were started, somewhat around 10 threads per worker process. This number resembles the numbers from gevent.pywsgi and Gunicorn+gevent cases:
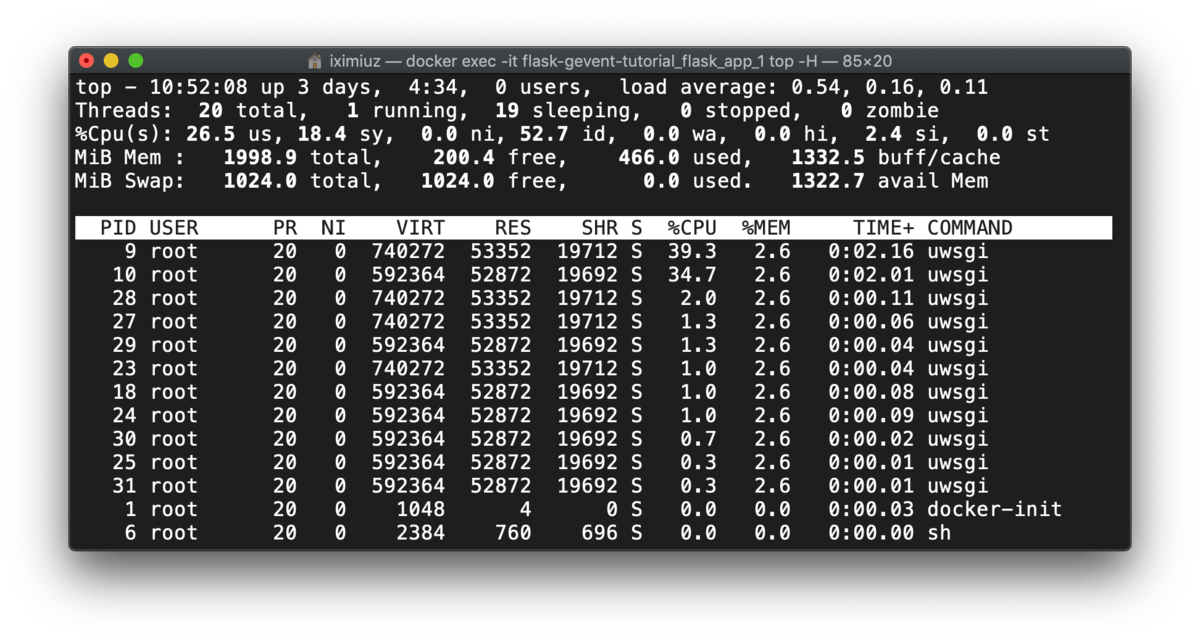
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (during test)
Use Nginx reverse proxy in front of application server
Usually, uWSGI and Gunicorn servers reside behind a load balancer and one of the most popular choices is Nginx.
Nginx + Gunicorn + gevent
Nginx configuration for Gunicorn upstream is just a standard proxy setup:
# ./flask_app/nginx-gunicorn.conf
server {
listen 80;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_pass http://flask_app:3000;
}
}
We can try it out using the following playground:
# ./nginx-gunicorn.yml
version: "3.7"
services:
ingress:
image: nginx:1.17.6
ports:
- "127.0.0.1:8080:80"
volumes:
- ./flask_app/nginx-gunicorn.conf:/etc/nginx/conf.d/default.conf
depends_on:
- flask_app
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-gunicorn
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=1
expose:
- "3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
And then:
$ docker-compose -f nginx-gunicorn.yml build
$ docker-compose -f nginx-gunicorn.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:8080/?delay=1
> ...
Nginx + uWSGI + gevent
uWSGI setup is very similar, but there is a subtle improvement. uWSGI provides a special binary protocol (called uWSGI) to communicate with the reverse proxy in front of it. This makes the joint slightly more efficient. And Nginx kindly supports it:
# ./flask_app/nginx-uwsgi.conf
server {
listen 80;
location / {
include uwsgi_params;
uwsgi_pass uwsgi://flask_app:3000;
}
}
Notice the environment variable PROTOCOL=uwsgi in the following playground:
# ./nginx-uwsgi.yml
version: "3.7"
services:
ingress:
image: nginx:1.17.6
ports:
- "127.0.0.1:8080:80"
volumes:
- ./flask_app/nginx-uwsgi.conf:/etc/nginx/conf.d/default.conf
depends_on:
- flask_app
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-uwsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=1
- ASYNC_CORES=2000
- PROTOCOL=uwsgi
expose:
- "3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
We can test the playground using:
$ docker-compose -f nginx-uwsgi.yml build
$ docker-compose -f nginx-uwsgi.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:8080/?delay=1
> ...
Bonus: make psycopg2 gevent-friendly with psycogreen
When asked, gevent patches only modules from the Python standard library. If we use 3rd party modules, like psycopg2, corresponding IO will remain blocking. Let's consider the following application:
# ./psycopg2/app.py
from gevent import monkey
monkey.patch_all()
import os
import psycopg2
import requests
from flask import Flask, request
api_port = os.environ['PORT_API']
api_url = f'http://slow_api:{api_port}/'
app = Flask(__name__)
@app.route('/')
def index():
conn = psycopg2.connect(user="example", password="example", host="postgres")
delay = float(request.args.get('delay') or 1)
resp = requests.get(f'{api_url}?delay={delay/2}')
cur = conn.cursor()
cur.execute("SELECT NOW(), pg_sleep(%s)", (delay/2,))
return 'Hi there! {} {}'.format(resp.text, cur.fetchall()[0])
We extended the workload by adding intentionally slow database access. Let's prepare the Dockerfile:
# ./psycopg2/Dockerfile
FROM python:3.8
RUN pip install Flask requests psycopg2 psycogreen uwsgi gevent
COPY app.py /app.py
COPY patched.py /patched.py
CMD uwsgi --master \
--single-interpreter \
--workers $WORKERS \
--gevent $ASYNC_CORES \
--protocol http \
--socket 0.0.0.0:$PORT_APP \
--module $MODULE:app
And the playground:
# ./bonus-psycopg2-gevent.yml
version: "3.7"
services:
flask_app:
init: true
build:
context: ./psycopg2
dockerfile: Dockerfile
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=1
- ASYNC_CORES=2000
- MODULE=app
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
- postgres
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
postgres:
image: postgres
environment:
POSTGRES_USER: example
POSTGRES_PASSWORD: example
expose:
- "5432"
Ideally, we expect ~2 seconds to perform 10 one-second-long HTTP requests with concurrency 5. But the test shows more than 6 seconds due to the blocking behavior of psycopg2 calls:
$ docker-compose -f bonus-psycopg2-gevent.yml build
$ docker-compose -f bonus-psycopg2-gevent.yml up
$ ab -r -n 10 -c 5 http://127.0.0.1:3000/?delay=1
> Concurrency Level: 5
> Time taken for tests: 6.670 seconds
> Complete requests: 10
> Failed requests: 0
> Requests per second: 1.50 [#/sec] (mean)
To bypass this limitation, we need to use psycogreen module to patch psycopg2:
The psycogreen package enables psycopg2 to work with coroutine libraries, using asynchronous calls internally but offering a blocking interface so that regular code can run unmodified. Psycopg offers coroutines support since release 2.2. Because the main module is a C extension it cannot be monkey-patched to become coroutine-friendly. Instead it exposes a hook that coroutine libraries can use to install a function integrating with their event scheduler. Psycopg will call the function whenever it executes a libpq call that may block. psycogreen is a collection of "wait callbacks" useful to integrate Psycopg with different coroutine libraries.
Let's create an entrypoint:
# ./psycopg2/patched.py
from psycogreen.gevent import patch_psycopg
patch_psycopg()
from app import app # re-export
And extend the playground:
# ./bonus-psycopg2-gevent.yml
services:
# ...
flask_app_2:
init: true
build:
context: ./psycopg2
dockerfile: Dockerfile
environment:
- PORT_APP=3001
- PORT_API=4000
- WORKERS=1
- ASYNC_CORES=2000
- MODULE=patched
ports:
- "127.0.0.1:3001:3001"
depends_on:
- slow_api
- postgres
If we test the new instance of the application with ab -n 10 -c 5, the observed performance will be much close to the theoretical one:
$ docker-compose -f bonus-psycopg2-gevent.yml build
$ docker-compose -f bonus-psycopg2-gevent.yml up
$ ab -r -n 10 -c 5 http://127.0.0.1:3001/?delay=1
> Concurrency Level: 5
> Time taken for tests: 3.148 seconds
> Complete requests: 10
> Failed requests: 0
> Requests per second: 3.18 [#/sec] (mean)
Draw your own conclusions :)
Related articles
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox:
