I've been using Kubernetes for almost a year now and, to be honest, I like the experience so far. Most of my use cases were rather trivial and thanks to its declarative approach, Kubernetes makes deploying and scaling stateless services pretty simple. I usually just describe my application in a YAML file as a set of interconnected services, feed it to Kubernetes, and let the built-in control loops bring the state of the cluster closer to the desired state by creating or destroying some resources for me automagically.
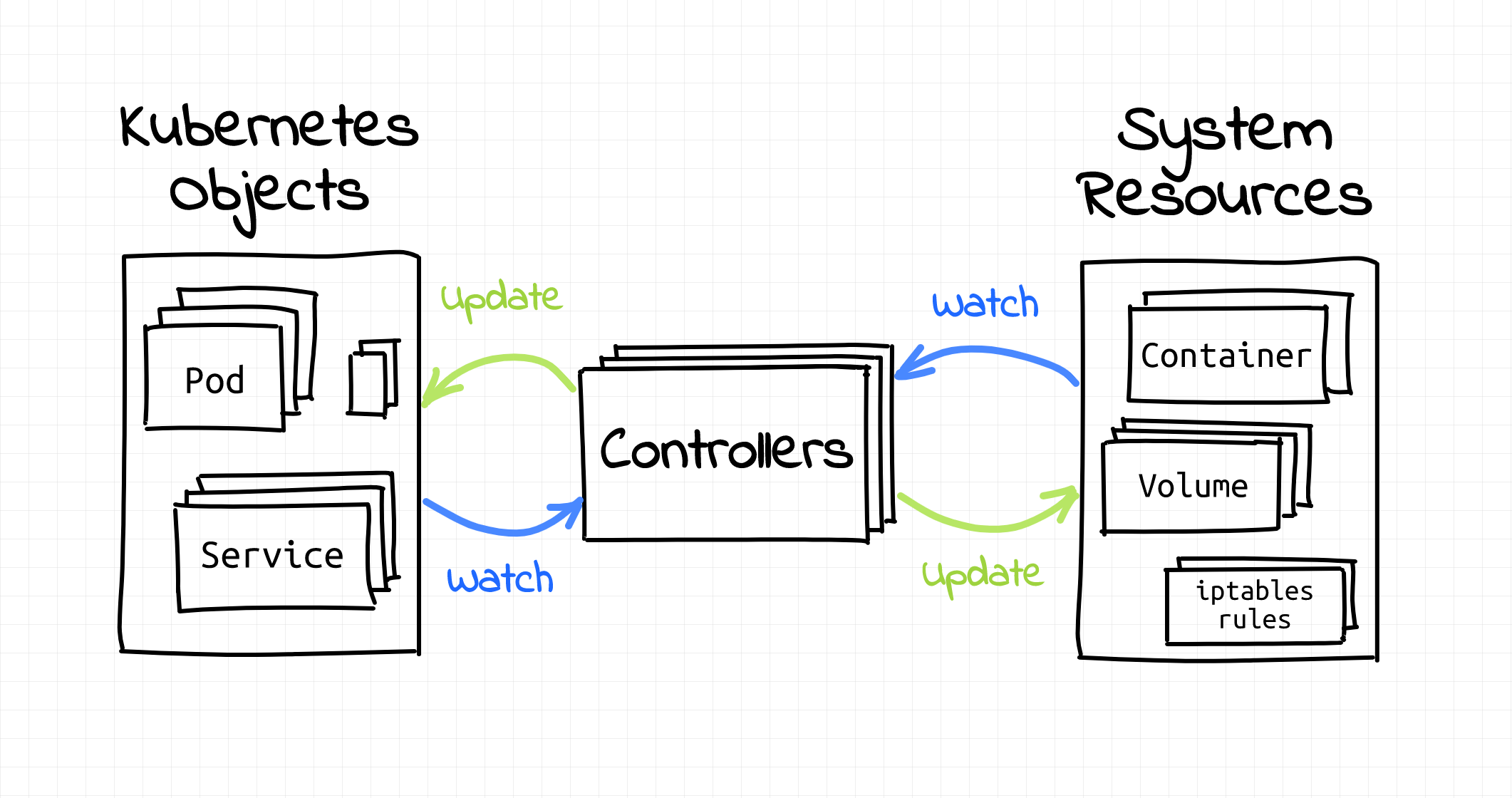
However, many times I've heard that the real power of Kubernetes is in its extensibility. Kubernetes brings a lot of useful automation out of the box. But it also provides extension points that can be used to customize Kubernetes capabilities. The cleverness of the Kubernetes design is that it encourages you to keep the extensions feel native! So when I stumbled upon the first few Kubernetes Operators on my Ops way, I could not even recognize that I'm dealing with custom logic...
In this article, I'll try to take a closer look at the Operators pattern, see which Kubernetes parts are involved in operators implementation, and what makes operators feel like first-class Kubernetes citizens. Of course, with as many pictures as possible.
Read more