Термин container довольно сильно перегружен. Для разных людей и в зависимости от контекста он может означать разные вещи (systemd-nspawn, lxc/lxd, docker, rkt, OCI-complaint runtime, kata containers, etc). Но основная цель контейнеризации остается неизменной - это эффективная упаковка и изолированное выполнение пользовательских приложений, реализуемая на уровне операционной системы (а по факту - Linux). Эта идея и технология существует довольно давно, но по-настоящему популярной ей удалось стать именно благодаря удобной реализации от Docker.
Так хорошо всем знакомые docker build|push|pull|run позволили обычным смертными программистами воспользоваться всеми преимуществами контейнеризации без выполнения сложных последовательностей команд и тонкой конфигурации. Но, у такого коробочного решения оказалась и обратная сторона. Повседневное использование docker run -it ubuntu bash (или написание Dockerfile-ов, начинающихся с FROM centos) может привести к тому, что контейнер начнет казаться чем-то мало отличимым от полноценной операционной системы, спрятанной внутри некоторой коробочки виртуализации, созданной докером на вашем хосте.
Level up your server-side game — join 20,000 engineers getting insightful learning materials straight to their inbox.
На самом же деле, почти всегда контейнер - это лишь изолированный (namespaces) и ограниченный с точки зрения потребляемых ресурсов (cgroups) и доступных действий (capabilities, seccomp, AppArmor) процесс (или группа процессов). Такой же, как и все остальные процессы на вашем Linux хосте. [1] Например, вот так выглядит запуск docker run -d nginx:

Вывод ps axf (отрывок).
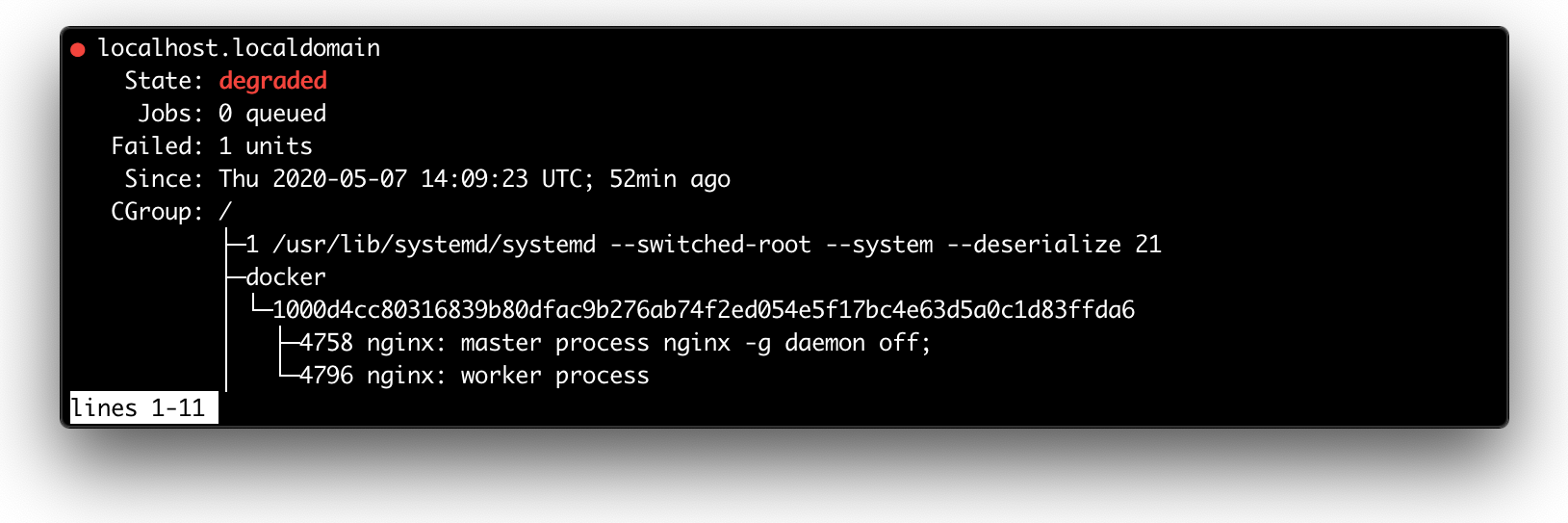
Вывод systemctl status (отрывок).
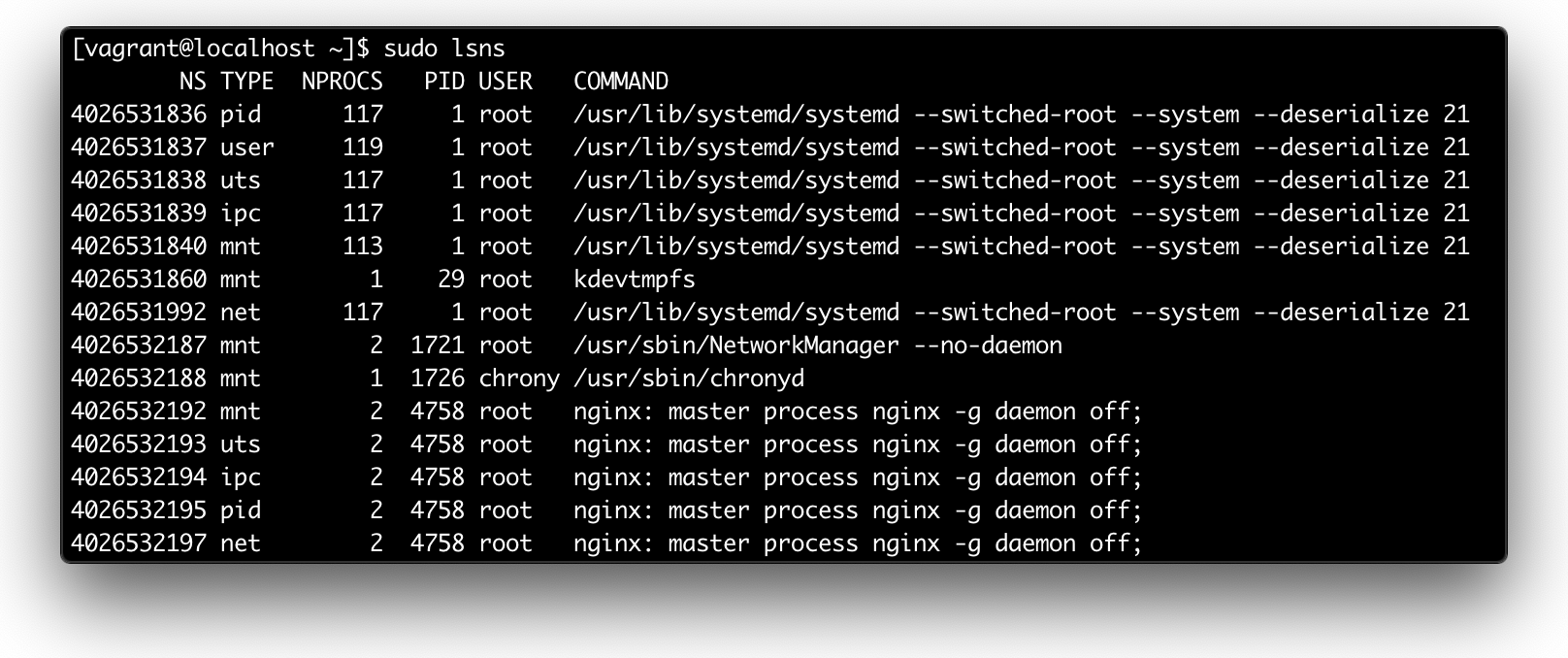
Вывод sudo lsns.
Но если контейнер - это обычный процесс, то для его запуска нам нужен всего лишь один единственный выполняемый файл! Т.е. можно создать контейнер с нуля FROM scratch (а не FROM debian|alpine|centos|etc) и добавить в пустую директорию (bundle) лишь один бинарник, который затем будет выполнен в изолированном окружении. Вполне себе валидный вариант использования, особенно для статических сборок, как в Go.
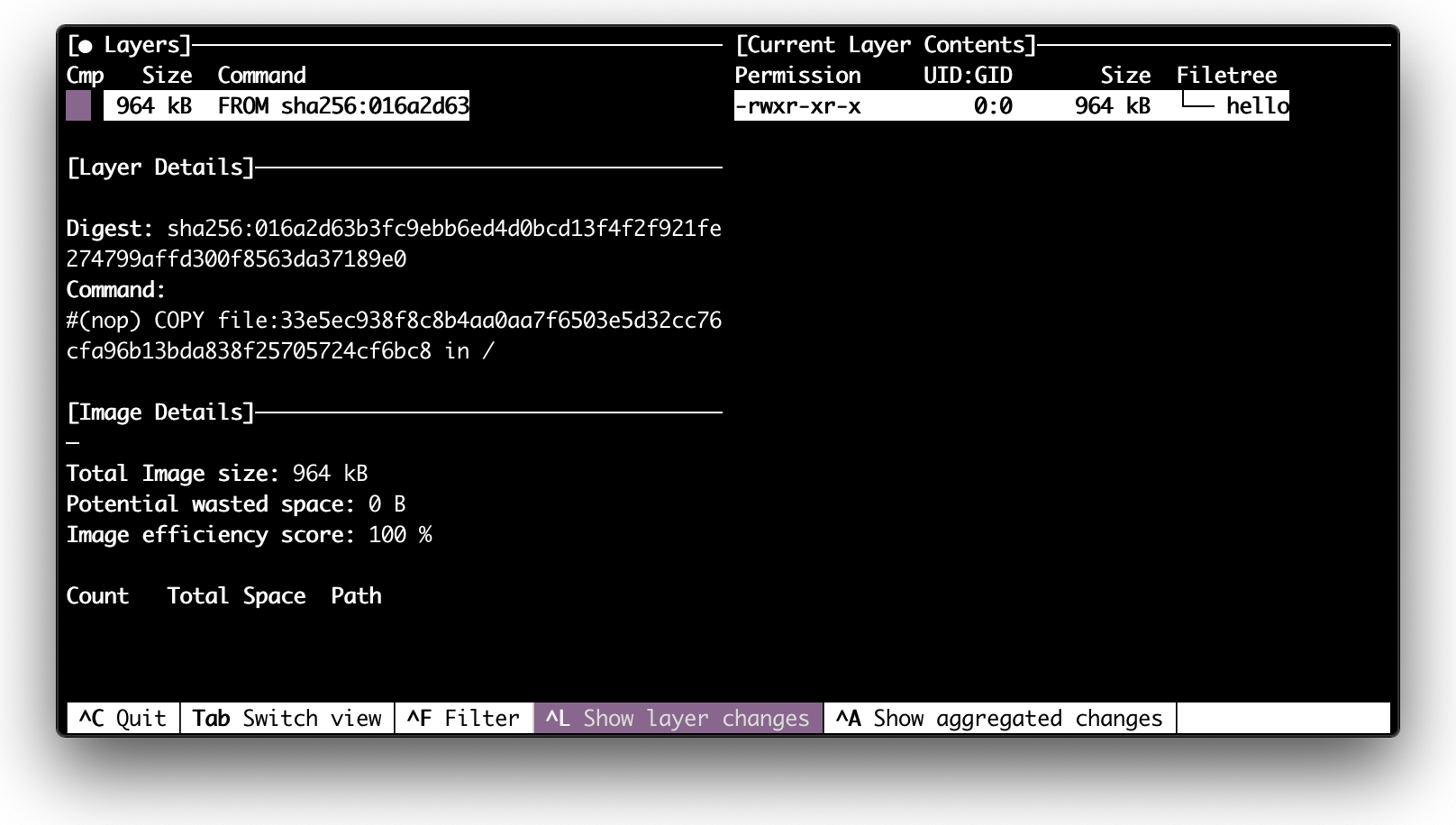
Вывод dive для минимального контейнера.
Если же программа внутри контейнера хочет иметь полноценную файловую структуру, что-то вроде того, что мы видим, выполняя ls /, то мы добавляем в bundle директорию все необходимые файлы. Заметили, что до сих пор мы ни разу не упомянули images? Только директории и исполняемые файлы, только хардкор!
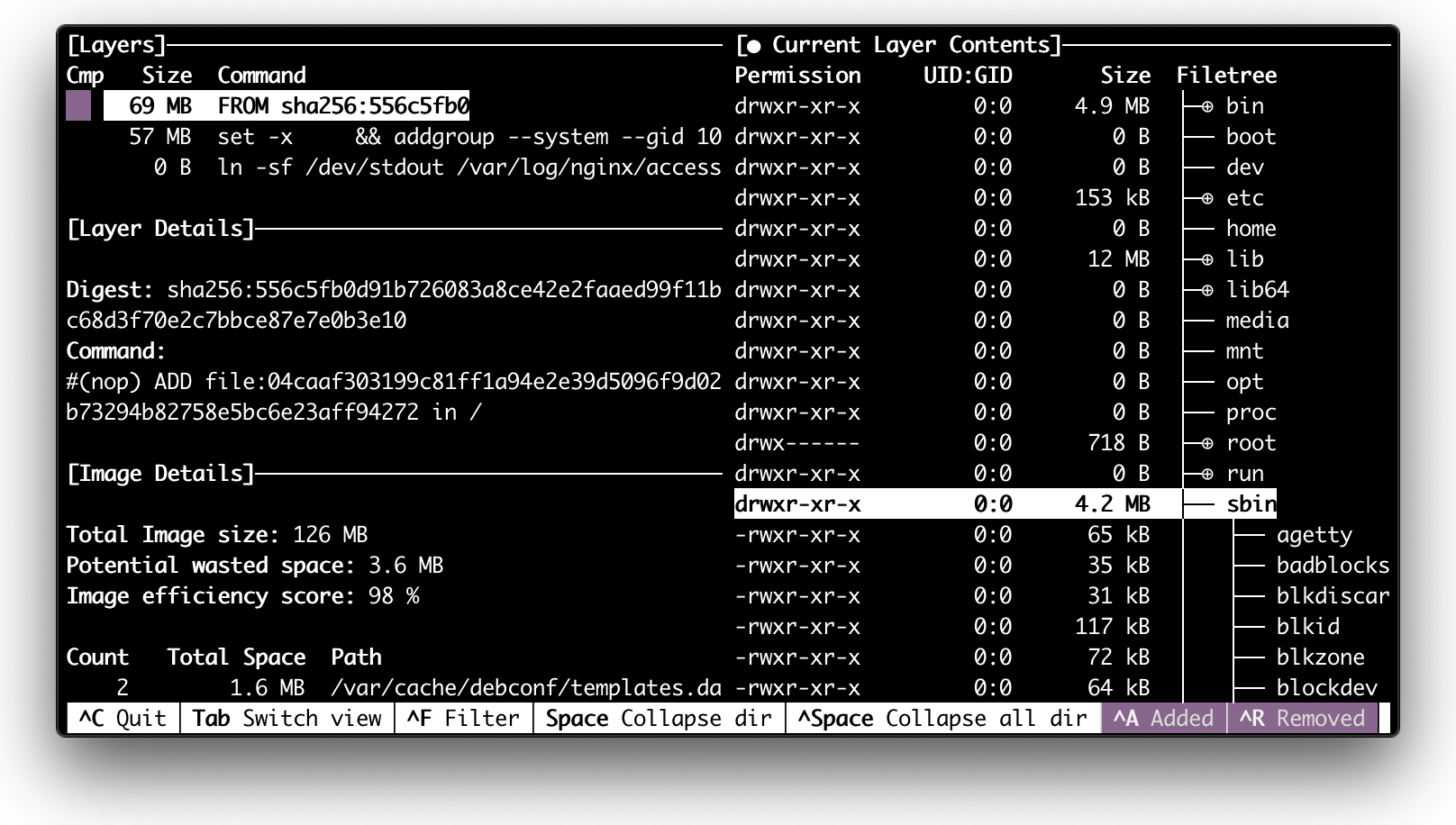
Вывод dive для контейнера с Linux distro внутри.
Так для чего же нужны все эти images? Оказывается, основная задача, решаемая с помощью images - это эффективная сборка и распространение контейнеров, а не их запуск. [2] Images - суть tar архивы с файловой системой внутри. Перед запуском контейнера такой архив распаковывается во временную директорию, которая затем становится bundle директорией контейнера. Но если у вас на хосте есть 10 кастомных образов, каждый из которых основывается на базовом образе debian (100+ MB), будет ли это означать, что они займут как минимум 1 GB на диске? К счастью - нет. Образы сохраняются слоями (layers). Базовый образ debian формирует один такой слой и этот слой - неизменяемый. На этот слой затем ссылаются все остальные кастомные образы. Отлично экономит место на диске нужное, для хранения образов. Что, если нам нужно запустить 100 экземпляров одного и того же контейнера? Нужно ли нам создать 100 копий bundle директории? Да! Займут ли они x100 от размера исходного образа? К счастью - нет! Опять же, спасибо слоям, мы можем создавать директории bundle монтирую слои один на другой с помощью какой-либо из реализаций union mount, например overlayfs. Все слои, кроме самого верхнего временного слоя, окажутся неизменяемыми и поэтому могут быть безопасно использованы совместно разными контейнерами. Все изменения файловой системы, сделанные любым из экземпляров контейнера будут сохранены в самом верхнем временном слое, который после остановки контейнера будет просто удален. Отлично экономит место на диске, нужное для запуска контейнеров.
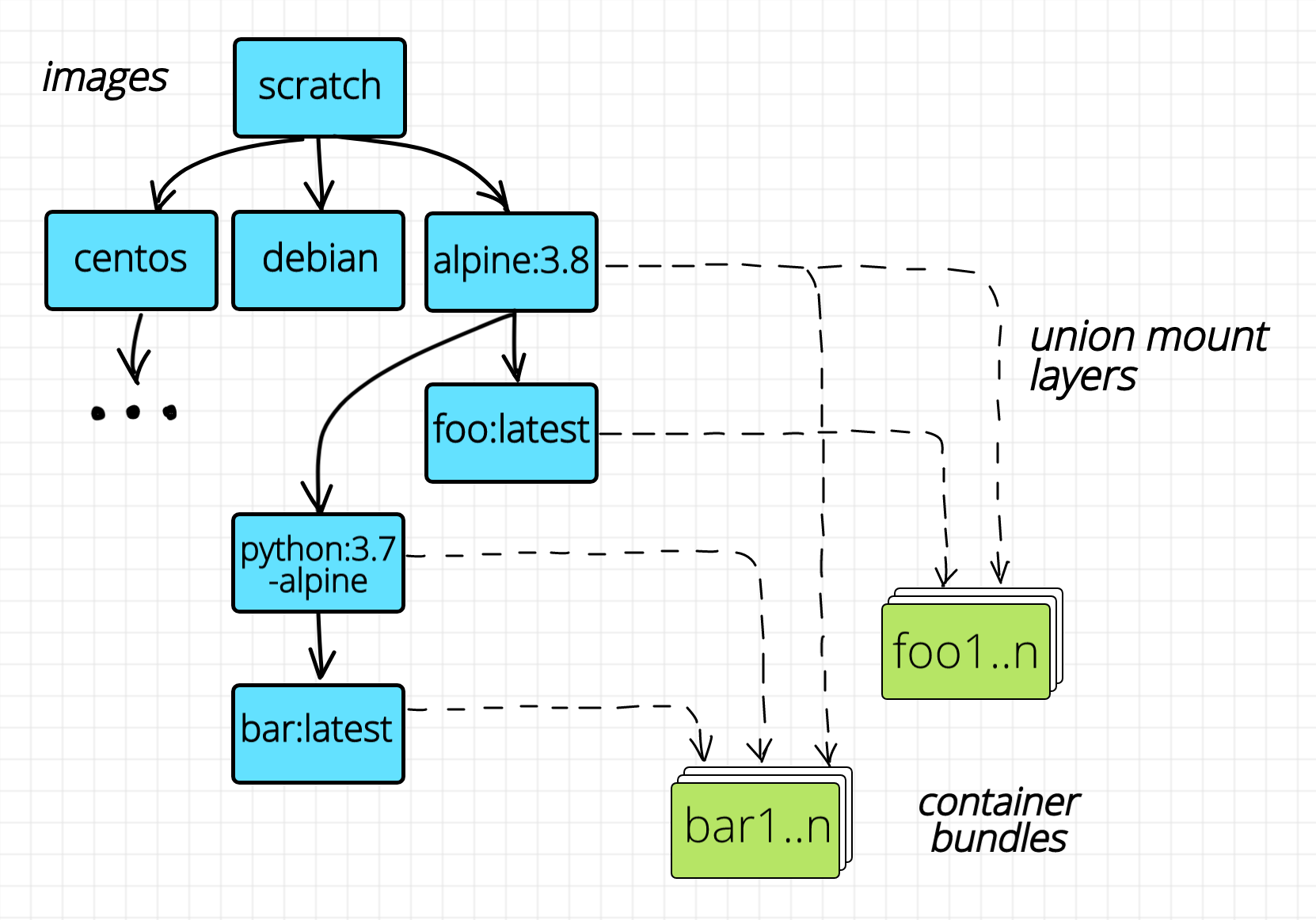
Итак, мы знаем, что images на самом деле не являются необходимым компонентом для контейнеров. Но на самом деле ситуация еще более "вывернутая" по сравнению с привычным нам вариантом использования docker build -> docker run. Для того, чтобы собрать образ, необходимо запускать контейнеры! [3] Обычно, мы их не видим, потому что docker (podman, buildah и т.п.) делает всю грязную работу за нас. Но, если в Dockerfile-е есть инструкция RUN это означает, что в процессе сборки образа будет происходить запуск промежуточных контейнеров. Задача таких контейнеров - выполнить команды из RUN в изолированном окружении.
Запуск docker build и docker stats в разных терминалах.
Как обычно, для создания таких контейнеров все промежуточные слои будут смонтированы для создания временной bundle директории. Все изменения файловой системы сделанные командами из инструкции RUN будут сохранены во временном слое, который затем будет сохранен, как один из слоев собираемого нами образа. Отличное и далеко не всегда явное использование технологии контейнеров!
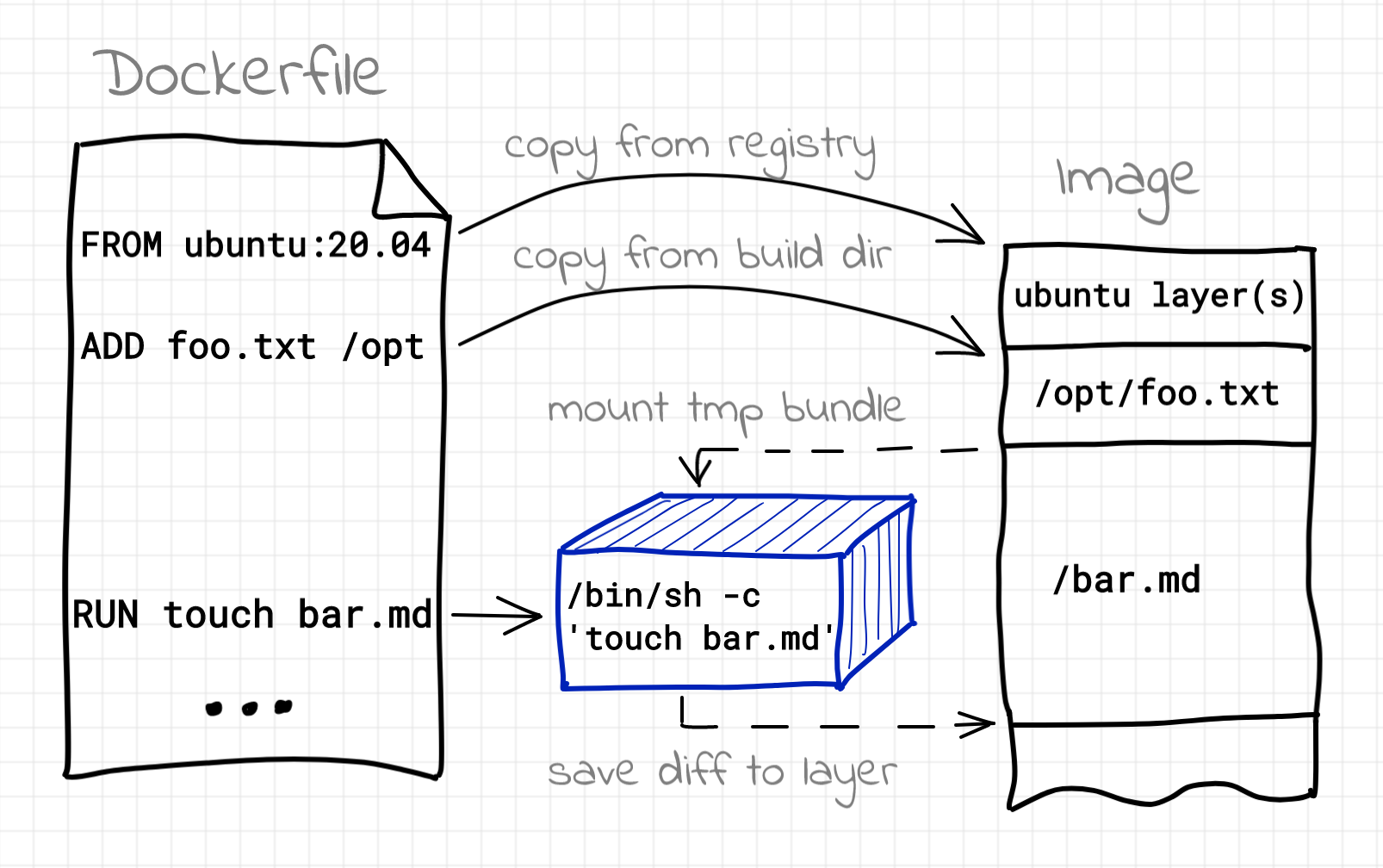
Сборка образа с использованием Dockerfile.
Надеюсь, что теперь контейнеры не кажутся вам чем-то магическим. Удачи!
Подпишись на обновления блогa, чтобы не пропустить следующий пост!
